Homework 2
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
Homework 2
Due date: 11:59 pm 3/2/2024
Submission: please submit a report including the answer for each question and corresponding screenshots.
A statistical attack on a polyalphabetic cipher, such as the Vigenère cipher, is a
method used to break the encryption without prior knowledge of the key. The
Vigenère cipher, for instance, uses a series of different Caesar ciphers based on
the letters of a keyword. While more secure, polyalphabetic ciphers are still
vulnerable to statistical attacks if the message is long enough. This attack can be achieved by using the frequency analysis of English letter in English language. The following table is the frequency of each letter in English language.
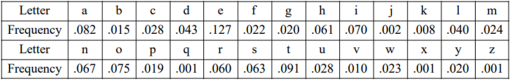
Taks 1. Please follow the steps to achieve the statistical attack for poly-alphabetic cipher with known key length.
Here is the ciphertext:
usojlbxpkieoiqmwucdyiaxamvknplbeaxcfjmvsjmvsfzblxstgrbbmfxgwyvhjgkamvknp axacjbachvqnvkmggrqztwfnmxgljglrwquuelgclaqlbaypgqcnkivikfagrtbaaswmrkmm jwvbrbfyqvgmltmgfypulbamjmbyuqgdgvoukqhlvmuwcwlsjivbvnmmxstxrutewxqbr zwusvgmfnmusvgiiltrseuqvteykjtidbacvmullxmggrqldqlbavgwkqhlgjvbvaxpnmeyjb acqttimqwc
Assume that the keyword has length 8, we need to partition the ciphertexts into different blocks and there are 8 letters in each block. Then the first letter of each block is encrypted with the same letter – they are encrypted with the same shifting number. Similarly, the second letter of each block is encrypted with the same shifting number. The same goes for the third to the seventh letters of each block. Because shifting the same number is easily broken by frequency analysis, we can discover the letters of the keyword. Here is how we can proceed.
Step 1: partition the ciphertext into different blocks.
Usojlbxp kieoiqmw ucdyiaxa mvknplbe axcfjmvs jmvsfzbl xstgrbbm
fxgwyvhj gkamvknp axacjbac hvqnvkmg grqztwfn mxgljglr wquuelgc
laqlbayp gqcnkivi kfagrtba aswmrkmm jwvbrbfy qvgmltmg fypulbam
jmbyuqgd gvoukqhl vmuwcwls jivbvnmm xstxrute wxqbrzwu svgmfnmu
svgiiltr seuqvtey kjtidbac vmullxmg grqldqlb avgwkqhl gjvbvaxp nmeyjbac qttimqwc
Step 2: calculate the frequency of each letter (a-z) among the first letter of each block using the code HW2_task1.py. You will find the most frequent letter is .
Step 3: since in English language the most frequent letter is “e”, then we can guess the first letter of key is .
Step 4: let us repeat step 2 and step 3 for the second, third, fourth, fifth, sixth and seventh letter of each block respectively. We can get the full key is .
Step 5: you decrypt the ciphertext with the above full key. Now you can find your decryption since . (For this task, you should analyze your decryption failure or success and the corresponding reason. )
Task 2. Compared to the task 1 which only uses the most frequent letter “e” in English for frequency analysis during the statistical attack, we will calculate the IC information of ciphertext to achieve the statistical attack. Based on the content we learnt in the class, for single letter, the IC in English should be close to 0.065 . After partitioning the ciphertext into different blocks (length of each block should be the same with the key), the i-th letter of each block (i in the range of [1, key length]) should shift the same number. Thus we calculate the IC of i-th letter among all blocks.
Process to compute the IC. Let the length of the text be N and let the size of the alphabet be n. Consider the i-th letter a_i in the alphabet. Suppose a_i appears in the given text Fi times. Since the number of a_i's in the text is Fi, picking the first a_i has Fi different choices and picking the second ai has only Fi-1 different choices because one a_i has been selected. Since there are N(N-1) different ways of picking two characters from the text, the probability of having two a_i's is
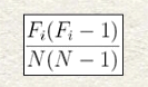
Therefore, the indexof coincidence is:
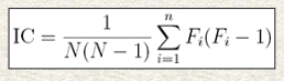
Note that English has n = 26 letters.
Please follow the steps below using the code HW2_task2.py:
Step 1: you need to guess the key length with IC. Please fill out the missing code (yellow part) based on the above information and comments.
******************************************************************
from collections import Counter
import numpy as np
# Function to calculate the Indexof Coincidence (IC)
def index_of_coincidence(text):
Write the code to calculate the IC
return ic
# Function to calculate the average IC for different key lengths
def average_ic(ciphertext, max_key_length):
avg_ics = []
for key_length in range(1, max_key_length + 1):
ics = [] # This list is to store the ic value for i-th position of blocks
for i in range(key_length):
nth_letters = write the code to create a substring of the ciphertext starting
from index i and selecting every key_length-th character since these letters shift
the same number
ic = index_of_coincidence(nth_letters)
ics.append(ic)
avg_ic = np.mean(ics)
avg_ics.append((key_length, avg_ic))
return avg_ics
# Sample ciphertext (replace this with your actual ciphertext)
ciphertext=
"usojlbxpkieoiqmwucdyiaxamvknplbeaxcfjmvsjmvsfzblxstgrbbmfxgwyvhjgkamvkn paxacjbachvqnvkmggrqztwfnmxgljglrwquuelgclaqlbaypgqcnkivikfagrtbaaswmrkm mjwvbrbfyqvgmltmgfypulbamjmbyuqgdgvoukqhlvmuwcwlsjivbvnmmxstxrutewxq brzwusvgmfnmusvgiiltrseuqvteykjtidbacvmullxmggrqldqlbavgwkqhlgjvbvaxpnmey jbacqttimqwc "
# Calculate and display the average IC for key lengths up to 10 (you can adjust this value)
max_key_length = 10
avg_ics = average_ic(ciphertext, max_key_length)
# Print the average ICs for each key length
for key_length, ic in avg_ics:
print(f"Key Length: {key_length}, Average IC: {ic:.4f}")
# Identify the key length with the IC closest to the expected IC for the language (0.065 for English)
expected_ic = 0.065
closest_key_length = min(avg_ics, key=lambda x: abs(x[1] - expected_ic))[0]
print(f"\nClosest key length to expected IC is: {closest_key_length}")
******************************************************************
After filling this, please run it and put the screenshot here. From this program, you will get the key length that is the closest to expected IC= 0.065.
Step 2: once you find the key length, you should find the specific key. Please read the following code and answer the questions.
******************************************************************
def key_finder(list, keylength, i):
smallest_x2 = float('inf')
best_c = ' '
N = 0
expected_freq = [
0.08167, 0.01492, 0.02782, 0.04253, 0.12702, 0.02228, 0.02015, 0.06094, 0.06966, 0.00153, 0.00772, 0.04025, 0.02406, 0.06749, 0.07507, 0.01929, 0.00095, 0.05987, 0.06327, 0.09056, 0.02758,
0.00978, 0.0236, 0.0015, 0.01974, 0.00074
]
observed_freq = [0] * 26
freq = [0] * 26
for j in range(i, len(list),keylength):
freq[ord(list[j]) - ord('a')] += 1
N = sum(freq)
for j in range(26):
observed_freq[j] = freq[j] / N
for j in range(26):
x2 = 0
for k in range(26):
x2 += ((observed_freq[(j + k) % 26] - expected_freq[k]) ** 2) / expected_freq[k]
if x2 < smallest_x2:
smallest_x2 = x2
best_c = chr(ord('A') + j)
return best_c
******************************************************************
Q1: In this code, instead of using the frequent letter “e” in English, the keypoint to guess the correct key is to compute “x2 += ((observed_freq[(j + k) % 26] - expected_freq[k]) ** 2) / expected_freq[k]” . Based on your understanding, what does this line mean? Compared to use the frequent letter frequent letter “e” in English for guessing password, what is the advantage of this computation?
Q2: What is the key? What is the plaintext? Put your screenshot here.
2024-02-29