Program 1 Iteration and Major Data Types: List, Tuple, Set, and Dict (and Open for files)
ICS-33: Intermediate Programming
| Introduction |
This programming assignment is designed to ensure that you know how to use combinations of Python's most important data types to model and compactly write/debug code that solves a wide variety of different programming problems. The kind of abstract thinking that goes into modeling solutions to these programming problems with these data types (and iteration over them) is critical to your development as computer scientists.
There are five parts to this assignment. In each you will be asked to write a module that contains a few functions and a script at the bottom, which ties these functions together to solve the problem. You should download the program1 project folder and use it to create an Eclipse project. The project folder contains files for all the modules in which to write your functions and scripts; it also contains all the data files that you need to test/debug your modules; finally, it contains all the batch self-check files I will use when grading your programs. In your modules, you may import additional standard/courselib modules and you may write additional helper functions. I recommend that you work on this assignment in pairs, and I recommend that you work with someone in your lab section (so that you have 4 hours each week of scheduled time together). These are just recommendations. Try to find someone who lives near you, with similar programming skills, and work habits/schedule: e.g., talk about whether you prefer to work mornings, nights, or weekends; what kind of commitment you will make to submit programs early. Only one student should submit all parts of the the assignment, but both students' UCInetID and name should appear in a comment at the top of each submitted .py file. A special grading program reads this information. The format is a comment starting with Submitter and Partner (when working with a partner), followed by a colon, followed by the student's UCInetID (in all lower-case), followed by the student's name in parentheses (last name, comma, first name -capitalized appropriately). If you omit this information, or do not follow this exact form, it will require extra work for us to grade your program, so we will deduct points. For example if Romeo Montague (whose UCInetID is romeo1) submitted a program that he worked on with his partner Juliet Capulet (whose UCInetID is jcapulet) the comment at the top of each .py file would appear as: # Submitter: romeo1(Montague, Romeo) # Partner : jcapulet(Capulet, Juliet) # We certify that we worked cooperatively on this programming # assignment, according to the rules for pair programmingIf you do not know what the terms cooperatively and/or rules for pair programming mean, please read about Pair Programming before starting this assignment. Please turn in each program as you finish it, so that I can more accurately assess the progress of the class as a whole during this assignment. Print this document and carefully read it, marking any parts that contain important detailed information that you find (for review before you turn in the files). The code you write should be as elegant and compact as possible, using appropriate Python idioms. You should familiarize yourselves with the safe_open function in the goody module and all the functions in the prompt module, both of which you should have installed in your courselib folder as part of the Eclipse/Python installation. Recall how to use the sep and end parameters in the print function. Currently Pythons f-strings offer the easiest way to format strings; know how to use them. Reread the section on Time Management from Programming Assignment 0 before starting this assignment. IMPORTANT 1: Before starting this assignment, download the xref project folder which contains a small Python script xref.py that produces a cross-reference of all the words (converted to lower case) in a file (where words appear with spaces between them: see xrefin.txt for an example): the words are listed in alphabetic order followed by a set (i.e., no duplicates) of the line numbers it appears on (listed in increasing numeric order). Before solving the problems in this programming assignment, ensure you understand all the details of how this program works: look at features and functions like safe_open, defaultdict (and how it is used), enumerate, rstrip and lower, split and join, sorted, lambda, for loops with two (unpacked) indexes, the two comprehensions (in the call to max and join), and f-strings. These are the building blocks for many parts of this assignment; explore and experiment with this code to understand how all the parts work together to achieve the desired result. Run this code on more complicated data files. IMPORTANT 2: This assignment has 5 parts: pairs should work on each part together, not split them up and do them separately. Parts 1-3 are going to be worth 12 points each; parts 4-5 are to be worth 7 points each. This skewing of points towards the simpler parts means students finishing the first 3 parts correctly will yield a 72% average; those finishing the first 4 parts correctly will have an 86% average; but to get an A on this assignment requires solving all parts correctly. I strongly recommend finishing the first part by the weekend, and then finishing another part every few days. In the past, many students waited until the last few days and then tried to write all their solutions: that is a recipe for learning little and getting a poor grade (or worse, cheating and getting caught; remember that I'm going to be running MOSS on all the parts of this assignment, checking for very similar solutions). So, now I am grading only 2 parts submitted on the day before the due date or later (and only 1 part submitted on the due date). You can submit as many parts as you want earlier than the day before the due date. That is if you submit all 5 parts on the day before the due date, I will grade only 2 parts; if you submit all parts on the due date I will grade only 1 part. If you submit all 5 parts two days before the due date, I will grade all 5 parts and you will get two extra credit points. In the worst case, to have me grade all parts, you must submit 3 parts two days before the due date, 1 part the day before the due date, and 1 part on the due date. So, start early on this assignment and submit your work well before the due date. IMPORTANT 3: I will mostly grade all these programs automatically, using the batch self-check files provided in the download. Use the driver program (explored in Programming Assignment #0) to run the batch-self check files in this assignment; debug any errors that they produce. But the TAs (with some automated tools) will also look at/run the code in some of your scripts: so the scripts need to follow exactly what is shown in the Sample Interactions part for each problem, including the wording of all prompts and messages. Therefore, I suggest testing your code first to match the scripts; when those results are correct, test it using the batch self-check files. Finally, if a submitted Python module contains even one syntax error or bad import, it will fail all its batch self-checks; ensure that you submit modules with no syntax or bad import errors (Python sometimes adds strange imports at the top of your file; ensure that all your imports are used and are reasonable). See Announcement #5 for details. |
| Problem #1: Influencers |
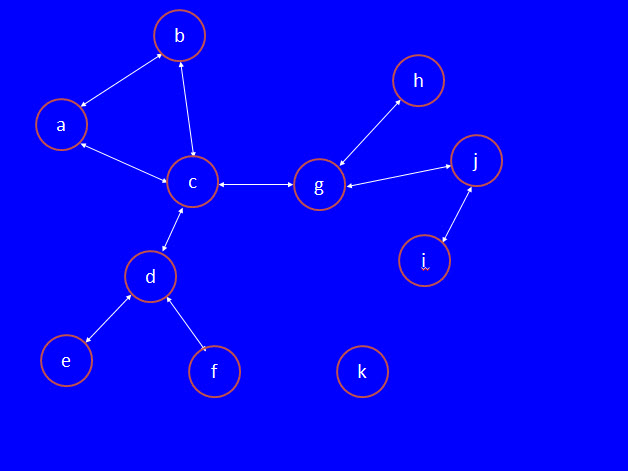
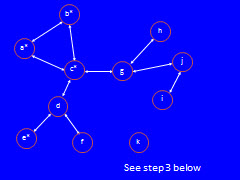
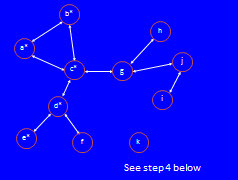
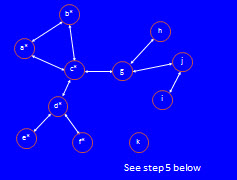
Problem Summary:Write the required functions and script that prompts the user for the name of a file representing a graph; reads the file (storing the graph in a dictionary); prints the graph/dictionary in a special form; computes an approximation to the minimmum influencers (a special set of node names in the graph); repeatedly prompts the user for a set of node names in the graph (rejecting sets that specify any node name not in the graph); computes and prints all the nodes that are "influenced" (see below) by the node names in the set.We can use a graph to describe friendships or professional relationships, as Facebook and LinkedIn do. Each node in a friendshiop graph is the name of a person, and that person has edges (arrows) leading from his/her node to the nodes of all his/her friends. In this model, friendship is symmetric (goes both ways): if a is b's friend (there is an arrow from a to b), then b is a's friend (there is an arrow from b to a). For simplicity, we will represent these two arrows by one double arrow: a single line with arrowheads at both ends. Such a graph, with all double-arrow edges, is called undirected. The undirected graph below shows all the friendships among the names a-k: note tha there k is edgeless, meaning he/she has no friends.
So, for example, in the above graph c has 4 friends: a, b, d, and g. Likewise g has 3 friends: c, h, and j. Of course, because c has g as a friend, g has c as a friend: see the double arrow. Note that h has just 1 friend: g. Finally k has 0 (no) friends. Assume that people in a friendship graph can influence their friends: specifically, assume in this example that if half or more of a person's friends like a song, then that person will decide (be influenced) to like the song too. For example, c has 4 friends, so if 2 or more of c's friends like a song, then c will be influenced to like it too; it doesn't matter which of c's friends like the song, so long as 2 or more of his/her friends like it. How does this rule apply if a person has an odd number of friends? For example, g has 3 friends, so half for g's friend would be 3/2 = 1.5 friends; in this case, we round upward to an integer and require 2 or more of g's 3 friends to like the song in order to influence g to like it. Let's see how a few people's influence can spread through this friendship graph. To start, let's suppose that that person b and e like a song. Here is how they can influence their friends, illustrated and explained below.
Computing which friends are influenced by b and e:
In fact, no pair of people wields enough influence for everyone in this graph to like a song (note that no one can influence k to like it). But if d, g, and k like a song, they can influence everyone else to like it too (check that this statement is true, to ensure that you understand the influencing process). This is the minimum number of people needed to influence everyone in this friendship graph. In this problem, we will learn how to represent friendship graphs in Python and implement an algorithm that computes a small set of nodes that can influence all the others. If we wanted to create a viral marketing campaign to promote say a new song (or any belief), we would concentrate our efforts on this set, because they could convince everyone else in their social network. Input and Output:We will store this graph in a dictionary: each person's/node's name will be a key (str) whose associated value is a set of str of the people/node names of his/her friends.Read a file where each line is either one node name (a person with no identifiable friends) or a pair of node names (representing an undirected friendship edge) in the graph. Note that node names may be any number of characters (not just the single characters used in this example), separated by one semicolon character. Build a dictionary whose keys are str node names, and whose associated values are sets of str node names that are friends. We annotate this dictionary as {str:{str}}. For example, the input file graph1.txt contains the following lines (which could appear in this order, or any other order, and still produce the same dictionary). By convention, we will put all friendless names at the end of the file. a;b a;c b;c c;d d;e d;f c;g g;h g;j i;j kwhich represent the original friendship graph we examined above.
Print the graph, one node name per line followed by the set of all his/her friend's node names (alphabetically). This graph above would print as Graph: person -> [friends]
a -> ['b', 'c']
b -> ['a', 'c']
c -> ['a', 'b', 'd', 'g']
d -> ['c', 'e', 'f']
e -> ['d']
f -> ['d']
g -> ['c', 'h', 'j']
h -> ['g']
i -> ['j']
j -> ['g', 'i']
k -> []
Note that the node names must be sorted alphabetically; and, the set of associated node names must appear in a list whose values are sorted alphabetically: we use a list, because it makes no sense to talk about sorted sets. Note that because node k appears in the input file on a line by itself, it has no friends. Remember that friendship is symmetric! So the line a;b means b is a's friend and a is b's friend; this means the node name b appears in node a's associated set and the node name a appears in node b's associated set. There are multiple data files for this program: graph1.txt (shown above), graph2.txt and graph3.txt; test/debug your program on the first file; when you are done, test it on the remaining files. Draw the graph represented by each file to ensure that your code correctly prints it and computes the set of influencer nodes (which you can do by eyeballing the graphs: they are small). Here is a description of the Influencer algorithm for computing a small set of nodes that can influence every node in the graph. It is guaranteed to produce a small set of nodes with the desired property, but it will not necessarily compute the smallest such set in all cases (that is a much harder problem). You must implement this Influencer algorithm, as it is described below. It is fairly straightforward to specify the Influencer algorithm, which is straightforward to implement in Python. But, first you must understand these English instructions, and only then can you carefully translate them into Python code. You should hand-simulate this algorithm using the data above, and verify that it produces the results that you expect, before coding it in Python.
Upon terminating, the keys remaining in infl_dict represent a small (but not necessarily the smallest) set of influencers for the entire friendship graph. Note that although infl_dict changes, the original dictionary storing the friendship graph remains unchanged. Read these instructions carefully, a few times. Hand simulate these instructions to ensure that you understand the Influencer algorithm; use the data above, which is automatically traced in the example below. Do not attempt to write any Python code to solve this problem until you understand this algorithm and can apply it to the data specified above. Eventually you will write your Python code to produce such a trace conditionally. Here is a trace (see the 2nd parameter to the find_influencers function described below, which activiates the trace) for the friendship graph specified above. The order of values in the dictionaries and lists are arbitrary; I have written these data structures on multiple lines for formating purposes.. influencer dictionary = {'a': [1, 2, 'a'], 'b': [1, 2, 'b'], 'c': [2, 4, 'c'], 'd': [1, 3, 'd'],
'e': [0, 1, 'e'], 'f': [0, 1, 'f'], 'g': [1, 3, 'g'], 'h': [0, 1, 'h'],
'j': [1, 2, 'j'], 'i': [0, 1, 'i'], 'k': [-1, 0, 'k']}
removal candidates = [(1, 2, 'a'), (1, 2, 'b'), (2, 4, 'c'), (1, 3, 'd'), (0, 1, 'e'),
(0, 1, 'f'), (1, 3, 'g'), (0, 1, 'h'), (1, 2, 'j'), (0, 1, 'i')]
(0, 1, 'e') is the smallest candidate
Removing e as key from influencer dictionary, also decrementing each friend's values there
influencer dictionary = {'a': [1, 2, 'a'], 'b': [1, 2, 'b'], 'c': [2, 4, 'c'], 'd': [0, 2, 'd'],
'f': [0, 1, 'f'], 'g': [1, 3, 'g'], 'h': [0, 1, 'h'], 'j': [1, 2, 'j'],
'i': [0, 1, 'i'], 'k': [-1, 0, 'k']}
removal candidates = [(1, 2, 'a'), (1, 2, 'b'), (2, 4, 'c'), (0, 2, 'd'), (0, 1, 'f'),
(1, 3, 'g'), (0, 1, 'h'), (1, 2, 'j'), (0, 1, 'i')]
(0, 1, 'f') is the smallest candidate
Removing f as key from influencer dictionary, also decrementing each friend's values there
influencer dictionary = {'a': [1, 2, 'a'], 'b': [1, 2, 'b'], 'c': [2, 4, 'c'], 'd': [-1, 1, 'd'],
'g': [1, 3, 'g'], 'h': [0, 1, 'h'], 'j': [1, 2, 'j'], 'i': [0, 1, 'i'],
'k': [-1, 0, 'k']}
removal candidates = [(1, 2, 'a'), (1, 2, 'b'), (2, 4, 'c'), (1, 3, 'g'), (0, 1, 'h'),
(1, 2, 'j'), (0, 1, 'i')]
(0, 1, 'h') is the smallest candidate
Removing h as key from influencer dictionary, also decrementing each friend's values there
influencer dictionary = {'a': [1, 2, 'a'], 'b': [1, 2, 'b'], 'c': [2, 4, 'c'], 'd': [-1, 1, 'd'],
'g': [0, 2, 'g'], 'j': [1, 2, 'j'], 'i': [0, 1, 'i'], 'k': [-1, 0, 'k']}
removal candidates = [(1, 2, 'a'), (1, 2, 'b'), (2, 4, 'c'), (0, 2, 'g'), (1, 2, 'j'),
(0, 1, 'i')]
(0, 1, 'i') is the smallest candidate
Removing i as key from influencer dictionary, also decrementing each friend's values there
influencer dictionary = {'a': [1, 2, 'a'], 'b': [1, 2, 'b'], 'c': [2, 4, 'c'], 'd': [-1, 1, 'd'],
'g': [0, 2, 'g'], 'j': [0, 1, 'j'], 'k': [-1, 0, 'k']}
removal candidates = [(1, 2, 'a'), (1, 2, 'b'), (2, 4, 'c'), (0, 2, 'g'), (0, 1, 'j')]
(0, 1, 'j') is the smallest candidate
Removing j as key from influencer dictionary, also decrementing each friend's values there
influencer dictionary = {'a': [1, 2, 'a'], 'b': [1, 2, 'b'], 'c': [2, 4, 'c'], 'd': [-1, 1, 'd'],
'g': [-1, 1, 'g'], 'k': [-1, 0, 'k']}
removal candidates = [(1, 2, 'a'), (1, 2, 'b'), (2, 4, 'c')]
(1, 2, 'a') is the smallest candidate
Removing a as key from influencer dictionary, also decrementing each friend's values there
influencer dictionary = {'b': [0, 1, 'b'], 'c': [1, 3, 'c'], 'd': [-1, 1, 'd'], 'g': [-1, 1, 'g'],
'k': [-1, 0, 'k']}
removal candidates = [(0, 1, 'b'), (1, 3, 'c')]
(0, 1, 'b') is the smallest candidate
Removing b as key from influencer dictionary, also decrementing each friend's values there
influencer dictionary = {'c': [0, 2, 'c'], 'd': [-1, 1, 'd'], 'g': [-1, 1, 'g'], 'k': [-1, 0, 'k']}
removal candidates = [(0, 2, 'c')]
(0, 2, 'c') is the smallest candidate
Removing c as key from influencer dictionary, also decrementing each friend's values there
influencer dictionary = {'d': [-2, 0, 'd'], 'g': [-2, 0, 'g'], 'k': [-1, 0, 'k']}
removal candidates = []
When the algorithm terminates, the small influencer set is {'d', 'g', 'k'}: the node names remaining in the infl_dict whose associated 3-list stores a negative number at index 0. Now, repeatedly prompt the user for a set of node names in the graph (until the user enters done) and compute and print all the nodes these influence (as well as the percentage of nodes in the graph influenced): the default value for the prompt should be all the nodes computed above, which when entered should influence 100% of the nodes in the friendship graph (if they were computed correctly). Reject any set that contains a node name that is not a key in the graph. Call the function all_influenced to compute this value: it uses the friendship graph and the set of node names the user enters to compute all the influenced nodes in the friendship graph as follows.
Pick any subset (or enter done)[{'d', 'g', 'k'}]: {'b','d'} Friends influenced by subset (54.54545454545455% of graph) = {'c', 'b', 'a', 'f', 'e', 'd'}
Pick any subset (or enter done)[{'d', 'g', 'k'}]: {'a','x'} Entry Error: '{'a','x'}';
Please enter a legal String
Pick any subset (or enter done)[{'d', 'g', 'k'}]:
Friends influenced by subset (100.0% of graph) = {'h', 'c', 'b', 'a', 'i', 'f', 'j', 'e', 'd', 'g', 'k'}
Pick any subset (or enter done)[{'d', 'g', 'k'}]: done
Functions and Script:Write the following functions and script. I am providing line counts for these function bodies not as requirements, but to indicate the lengths of well-written Pythonic code.
Sample Interaction:The program, as specified, will have the following interaction: user-typed information appears in italics. Your output should "match" this one (sets will match if they have the same contents, independent of their order). You should also check that it works for other graphs. Pick the file name containing the friendship graph: graph.txt:
Graph: person -> [friends]
a -> ['b', 'c']
b -> ['a', 'c']
c -> ['a', 'b', 'd', 'g']
d -> ['c', 'e', 'f']
e -> ['d']
f -> ['d']
g -> ['c', 'h', 'j']
h -> ['g']
i -> ['j']
j -> ['g', 'i']
k -> []
Produce Trace of Algorithm[True]: False The influencers are {'g', 'k', 'd'}
Pick any subset (or enter done)[{'g', 'k', 'd'}]:
Friends influenced by subset (100.0% of graph) = {'i', 'g', 'f', 'k', 'c', 'j', 'h', 'a', 'b', 'd', 'e'}
Pick any subset (or enter done)[{'g', 'k', 'd'}]: done
|
| Problem #2: Stable Marriage |
Problem Summary:Write the required functions and script that prompts the user for the names of two files: a file representing the marriage preferences of a sequence of men, and a file representing the marriage preferences of a sequence of women; reads these files (storing this information in special data structures: dictionaries storing preference as lists); prints the dictionary/preferences of the men and women in a special form; runs the Gale/Shapley algorithm for finding a stable marriage (tracing its progress, if required); prints the stable marriage as a set of man/woman tuples. Please excuse my use of heteronormative terms. The problem is easier to state and understand when it uses two disjoint sets, men and women, whose members match only others outside their sets.Suppose that N men and N women want to match in a heterosexual marriage. Each produces a list of his/her preferences, ranking all members of the opposite gender in highest to lowest order of acceptability as a partner. The Gale/Shapley algorithm (described in detail below) matches men and women in stable marriages. Marriages are stable when we cannot find a man and woman, who prefer each other to their match. This scenario can be used to find stable matches in other contexts. For example, this algorithm is used when medical school graduates match with hospitals for their residencies: the students and institutions rank each other and then the algorithm is run, processing these rankings. In this case, the residents propose (act as the men in the description above) and the hospitals accept/reject the proposals (act as the women). The fundamental data structure used throughout this process (as both arguments to functions and the results returned by functions) is characterized by {str:[str,[str]]}, which describes a dictionary whose keys are associated with 2-lists. The dictionary keys are the names of men/women (str). Each man/woman is associated with a 2-list, whose first index is the current match of that person (str), and whose second index is a list ranking other possible matches (list of str), from highest to lowest preference. For example, the following dictionary represents information about three men participating in marriages (m1, m2, m3): {'m1': [None, ['w3', 'w2', 'w1']],
'm2': [None, ['w3', 'w1', 'w2']],
'm3': [None, ['w2', 'w1', 'w3']]}
Here, m1 is currently matched with no one (None) and ranks the women, in order of preference, as follows w3 (hightes ranking) followed by w2 followed by w1 (lowest ranking). The other lines in this dictionary are interpreted similarly. In this example (and the ones below) I have printed each key/value pair (alphabetically by key) on its own line; of course, if we print a dictionary in Python, it can print its key/value pairs in any order.
The following dictionary represents information about three women participating in marriages (w1, w2, and w3): {'w1': [None, ['m1', 'm2', 'm3']],
'w2': [None, ['m2', 'm1', 'm3']],
'w3': [None, ['m3', 'm2', 'm1']]}
Here, w2 is currently matched with no one (None) and ranks the men, in order of preference, as follows m2 (highest ranking) followed by m1 followed by m3 (lowest ranking).
After running the Gale/Shapley algorithm (with men proposing to women, and women accepting or rejecting their proposals: more on these details later), these dictionaries are mutated to {'m1': ['w2', ['w3', 'w2', 'w1']],
'm2': ['w3', ['w3', 'w1', 'w2']],
'm3': ['w1', ['w2', 'w1', 'w3']]}
{'w1': ['m3', ['m1', 'm2', 'm3']],
'w2': ['m1', ['m2', 'm1', 'm3']],
'w3': ['m2', ['m3', 'm2', 'm1']]}
Note the following invariant: if a man is matched to a woman in the man's dictionary, then that same woman must be matched to that man in the woman's dictionary. Verify that this is true above.
Are these marriages stable? First, let's look just at m1, who is matched to w2. By his preferences, he would rather marry w3, but she prefers m2 (her match) to m1. Now, let's look just at w1, who is matched to m3. By her preferences, she would rather marry m1, but he prefers w2 (his match) to w1; also w1 would prefer to marry m2, but he also prefers w3 (his match) to w1. If you check all the other men and women (do it) you will find that you can find no pair who would both rather marry each other, rather than their current matches, so these marriages are considered stable. Input and Output:Read files of men and women and their rankings of all members of the opposite gender (highest to lowest preference), separated by semicolons, building a dictionary like the ones above (where each match is initially the special value None). As described above, we annotate the structure of this dictionary as {str:[str,[str]]}.In the file, the person's name appears first, followed by the names of all members of the opposite gender in highest to lowest preference, separated by one semicolon character. For example, the input file men0.txt contains the following lines: these line could appear in this order, or any other, but the each man's preferences must appear in decleasing order of preference. m1;w3;w2;w1 m2;w3;w1;w2 m3;w2;w1;w3The first line means, m1 ranks the members of the opposite gender in the order of preference from w3, w2, and w1 in decreasing order of preference Each line is guaranteed to start with a unique name, which is guaranteed to be followed by all the names of all members of the opposite gender, each appearing once; and all names are separated by semicolons. When you print such information, print each person on a separate line, followed by his/her match and preferences. For example, the file above would print as: m1 -> [None, ['w3', 'w2', 'w1']] m2 -> [None, ['w3', 'w1', 'w2']] m3 -> [None, ['w2', 'w1', 'w3']] Note that the names on the lines must be sorted in alphabetical order; the list of preferences must appear in the same order they appeared in the file. There are multiple pairs of data files for this program, all named like men0.txt and women0.txt; Test/debug your program on the first file; when you are done, test it on the remaining files. Here is a description of the Gale/Shapley Algorithm for computing a stable marriage. You must implement this algorithm, as it is described below. There might be other stable marriages, but this algorithm will always compute the same one. This algorithm is not symmetric: here men get to propose to women and women get to accept/reject men. If we ran the algorithm the other way (with women proposing to men, and men accepting or rejecting women, we would also get a stable marriage, but the matches might be different. It is fairly straightforward to specify the Gale/Shapley algorithm, which is straightforward to implement in Python. But, first you must understand these English instructions, and only then can you carefully translate them into Python code. You should hand-simulate this algorithm using the data above, and verify that it produces the results that you expect, before coding the algorithm in Python.
Here is a trace (see the 3rd parameter to the make_match function below) for the men and women data structures specified above. Women Preferences (unchanging)
w1 -> [None, ['m1', 'm2', 'm3']]
w2 -> [None, ['m2', 'm1', 'm3']]
w3 -> [None, ['m3', 'm2', 'm1']]
Men Preferences (current)
m1 -> [None, ['w3', 'w2', 'w1']]
m2 -> [None, ['w3', 'w1', 'w2']]
m3 -> [None, ['w2', 'w1', 'w3']]
unmatched men = {'m2', 'm3', 'm1'}
m2 proposes to w3, an unmatched woman, who accepts the proposal
Men Preferences (current)
m1 -> [None, ['w3', 'w2', 'w1']]
m2 -> ['w3', ['w1', 'w2']]
m3 -> [None, ['w2', 'w1', 'w3']]
unmatched men = {'m3', 'm1'}
m3 proposes to w2, an unmatched woman, who accepts the proposal
Men Preferences (current)
m1 -> [None, ['w3', 'w2', 'w1']]
m2 -> ['w3', ['w1', 'w2']]
m3 -> ['w2', ['w1', 'w3']]
unmatched men = {'m1'}
m1 proposes to w3, a matched woman, who rejects the proposal (she prefers her current match)
Men Preferences (current)
m1 -> [None, ['w2', 'w1']]
m2 -> ['w3', ['w1', 'w2']]
m3 -> ['w2', ['w1', 'w3']]
unmatched men = {'m1'}
m1 proposes to w2, a matched woman, who accepts the proposal (she prefers her new match)
Men Preferences (current)
m1 -> ['w2', ['w1']]
m2 -> ['w3', ['w1', 'w2']]
m3 -> [None, ['w1', 'w3']]
unmatched men = {'m3'}
m3 proposes to w1, an unmatched woman, who accepts the proposal
Algorithm traced: the final matches = {('m1', 'w2'), ('m3', 'w1'), ('m2', 'w3')}
The resulting matches form stable marriages (the ones discussed above, when we discussed the meaning of stability). When this algorithm stops, the local copy of the men's data structure has become
m1 -> ['w2', ['w1']] m2 -> ['w3', ['w1', 'w2']] m3 -> ['w1', ['w3']] Note that each man's preference list shows only the women he did not propose to. Finally, if we used the same algorithm but let the women propose to the men, who accept or reject the proposals, we would get the following matches. Algorithm traced: the final matches = {('w2', 'm2'), ('w1', 'm1'), ('w3', 'm3')}
These matches are all different, but the marriages are all still stable. So, who proposes to whom can determine the results of the algorithm: we can run the program, swapping the men's/women's files, to see if it produces an alternative stable matching. Functions and Script:Write the following functions and script. I am providing line counts for these function bodies not as requirements, but to indicate the lengths of well-written Pythonic code.
Sample Interaction:The program, as specified, will have the following interaction: user-typed information appears in italics. Your output should match this one. Pick the file name containing the preferences for men: men0.txt Pick the file name containing the preferences for women: women0.txt Men Preferences
m1 -> [None, ['w3', 'w2', 'w1']]
m2 -> [None, ['w3', 'w1', 'w2']]
m3 -> [None, ['w2', 'w1', 'w3']]
Women Preferences
w1 -> [None, ['m1', 'm2', 'm3']]
w2 -> [None, ['m2', 'm1', 'm3']]
w3 -> [None, ['m3', 'm2', 'm1']]
Produce Trace of Algorithm[True]: False The final matches = {('m1', 'w2'), ('m3', 'w1'), ('m2', 'w3')}
Note that if the user specified True for tracing the algorithm, the program would also print all the information shown above in the example of tracing the Gale/Shapley algorithm. Finally, you can also try processing the men1.txt/women1.txt and men2.txt/women2.txt pairs of files. You can print these data files and hand-simulate the Gale/Shapely algorithsm on them to compute their stable matches. You can also feed the women file in as the men file, and the men file in as the women file, to see the match that results from letting women propose and men accept or reject: it can produce different matching pairs, but the matching pairs it produces will be stable. |
| Problem #3: Finite Automata |
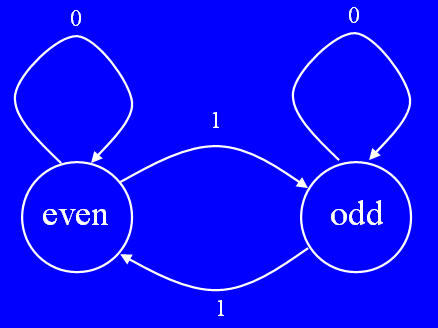
Problem Summary:Write the required functions and script that prompts the user for the name of a file representing a finite automaton: indicating its states and input->state transitions; reads the information in the file (storing the finite automaton in a dictionary); prints the finite-automaton/dictionary in a special form; prompts the user for the name of a file storing the start-state and inputs to process (each line in the file contains this combination); repeatedly processes these lines, computing the results of the finite automaton on each input, and then prints the results. Note that a finite automaton is really a program; in this problem we are reading a program from a file and then executing it (running the finite automaton) on various inputs. So, we are really writing a compiler/interpreter for a small programming language.A finite automaton (FA) is an machine that is sometimes called a Deterministic Finite Automaton (DFA; see the next problem for an NDFA: a non-deterministic finite automaton). An FA is described by its states and its transitions: each transition for a state specifies an input and what state in the FA that input leads to. We can illustrate an FA as a graph with state labels in circles and edge labels for transitions (see below). Input and Output:Read a file that describes a FA: each line contains a state and an arbitrary number of input->state transitions. Build a dictionary such that each key is a str state and whose associated value is another dictionary specifying all the transitions from that state: this second dictionary has keys that are str inputs and associated values are str states. The first token on each line is the str state and the remaining tokens (always coming in pairs) are str inputs and their resulting states. All tokens (which can comprise any number of characters) are separated by one semicolon character. We annotate this dictionary as {str:{str:str}}.For example, the input file faparity.txt contains the following lines (which could appear in this order, or any other and still specify the same FA): even;0;even;1;odd odd;0;odd;1;evenHere is a picture of the parity FA. It graphically illustrates the two states (even and odd) and their transitions, using inputs (0 and 1) that always lead back to one of these two states.
Here, the state even (meaning it has seen an even number of 1 inputs so far) is a key in the main dictionary. Its value is a dictionary with two key/value pairs 0->even and 1->odd. It means that in the even state, if the input is a 0 the FA stays in the even state; if the input is a 1 the FA goes to the odd state. And similarly (the next line) means that for the odd state, if the input is a 0 the FA stays in the odd state; if the input is a 1 the FA goes back to the even state. So, seeing an input of 0 keeps the FA in the same state; seeing an input of 1 flips the FA into the other state. Print the finite automaton, one state (and its transitions) per line; the states are printed alphabetically and the transition dictionary for each state is printed as a list of input/state items (tuples) such that these are printed alphabetically by the inputs. For example, the file above would print as: The Contents of the file picked for this Finite Automaton
even transitions: [('0', 'even'), ('1', 'odd')]
odd transitions: [('0', 'odd'), ('1', 'even')]
Note that there are multiple data files for this program: faparity.txt and fadivisibleby3.txt; test/debug your program on the first file; when you are done, test it on the last file. Draw the FA represented by each for to ensure that your code correctly prints and computes with it. Important: This task is not to write a Python code that simulates the Parity FA; it is to write code that simulates any FA, whose description it reads from a file. Next, repeatedly read and process lines from a second input file, computing the results of the finite automaton running on the specified start-state with its inputs; then print out the results in a special form. Each line in the file contains a start-state followed by a sequence of inputs (all separated by semicolons). The start-state will be a state in the FA (it is a key in the outer dictionary) the inputs may specify legal or illegal transitions (may or may not be keys in some inner dictonary). For example, the input file fainputparity.txt contains the following three lines: even;1;0;1;1;0;1 even;1;0;1;1;0;x odd;1;0;1;1;0;1The first line means, the start-state is even and the inputs are 1, 0, 1, 1, 0, and 1. The result of processing each line is to print the start-state, and then each input and the new state it transitions to, and finally print the stop-state. For the parity FA and the first line in this file, it should print Start state = even Input = 1; new state = odd Input = 0; new state = odd Input = 1; new state = even Input = 1; new state = odd Input = 0; new state = odd Input = 1; new state = even Stop state = even Note that the second line contains an input x which is not a legal input allowed in any state; any such input should stop the simulation for that line only, continuing to start a new simulation for all following lines (as illustrated in the Sample Interaction). Functions and Script:Write the following functions and script. I am providing line counts for these function bodies not as requirements, but to indicate the lengths of well-written Pythonic code.
Sample Interaction:The program, as specified, will have the following interaction: user-typed information appears in italics. Your output should match this one. Pick the file name containing this Finite Automaton: faparity.txt The Contents of the file picked for this Finite Automaton
even transitions: [('0', 'even'), ('1', 'odd')]
odd transitions: [('0', 'odd'), ('1', 'even')]
Pick the file name containing a sequence of start-states and subsequent inputs: fainputparity.txt Commence tracing this FA from its start-state
Start state = even
Input = 1; new state = odd
Input = 0; new state = odd
Input = 1; new state = even
Input = 1; new state = odd
Input = 0; new state = odd
Input = 1; new state = even
Stop state = even
Commence tracing this FA from its start-state
Start state = even
Input = 1; new state = odd
Input = 0; new state = odd
Input = 1; new state = even
Input = 1; new state = odd
Input = 0; new state = odd
Input = x; illegal input: simulation terminated
Stop state = None
Commence tracing this FA from its start-state
Start state = odd
Input = 1; new state = even
Input = 0; new state = even
Input = 1; new state = odd
Input = 1; new state = even
Input = 0; new state = even
Input = 1; new state = odd
Stop state = odd
You can also try the fadivisibleby3.txt finite automaton file, which determines whether an integer (sequence of digits) is divisible by 3: it is divisible if the finite automaton stops in state rem0. It's input file fainputdivisibleby3.txt tries the number 12,435,711, which is divisible by 3 and number 823, which is not divisible by 3: dividing 823 by 3 leaves a remainder of 1. |