IMAT3104 DATABASE MANAGEMENT AND PROGRAMMING NOSQL 2023/24
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
IMAT3104 DATABASE MANAGEMENT AND PROGRAMMING NOSQL
MongoDB Coursework 2023/24
1.0 INTRODUCTION
This is an individual assignment, which gives you an opportunity to demonstrate your knowledge of NoSQL and your ability to implement, query and design a MongoDB document database. You will be awarded marks for what is achieved. This assignment is worth 50% of the overall module mark.
2.0 CONNECT, EXTRACT, TRANSFORM AND LOAD DATA (CETL) [10 marks]
2.1 Connecting to DMU MongoDB server.
Connect to MongoDB server using MongoDB Compass with the following credentials. Please note that the username and password are in lowercase.
|
Host |
mongodb.dmu.ac.uk |
|
Username |
pnumber |
|
Password |
Check LearningZone under My Grades |
|
Authentication Database |
admin |
Note: At the moment, you can only connect to the MongoDB server while on university network. This means either you are on the University lab machines or you connect via Horizon. If you wish to work on your PC, you have to complete the CETL then move to your PC and import the personalized datasets.
2.2 Getting your personalized data.
You are assigned a specific dataset to work on the labs. This means, the results you will get from your queries will be different from other students. Check LearningZone for AssignedCourseworkGroup.xlsx
1. Extract all products matching your assigned_group from products collection into a new collection named products in pxxxxxxx_db.
2. Extract all matching reviews of products in pxxxxxxx_db to a collection named reviews in pxxxxxxx_db.
3. Extract all matching genres of products in pxxxxxxx_db to a collection named genres in pxxxxxxx_db
4. Extract all matching authors of products in pxxxxxxx_db to a collection named authors in pxxxxxxx_db.
Export all your collections to your local machine. Disconnect from the DMU MongoDB server and connect to localhost server. For those that would want to continue the assessment on their PC, this is the time to move back to your PC!
2.2 Understanding the data.
Study all the collections and answer the following:
1. What is/are the unique/identifying key(s) of the documents of each collection? [4 marks]
2. Study the collections briefly with their fields and values. [6 marks]
a. Identify issues and anomalies you have seen such as invalid data, empty fields, etc.?
b. Identify examples and how you intend to address them. You do not need to solve the issues here. Complete the table below based on 2(a) and 2(b).
|
Collection |
Field |
Anomaly |
Examples |
Solution Plan |
|
|
|
|
|
|
3.0 CLEANING THE COLLECTIONS [15 marks]
Have a quick look at the collections on MongoDB Compass, you will realise that some of the data was only scrapped from the internet and incomplete or not in proper format. Remember, in Section 2.2, you identified some anomalies on the dataset. For each anomaly that happens to be in your personalized dataset:
1. Provide for a minimum of four (4) anomalies. [8 marks]
a. Take screenshots of sample documents with the anomaly before it is corrected.
b. Show the query/queries used to address this anomaly.
c. Take screenshots of samples of documents after the anomaly has been corrected.
2. Create a new field (if it does not exist) named date in the format YYYY-MM-DD that merges publication_day, publication_month, and publication_year for documents where such fields exist. You can use the $exists operator. [2 mark]
3. Create another field in the products collection unix_publication_date that converts date in all documents with the field to Unix format. [2 mark]
4. Convert the price field to double format and in 2 decimal places. [3 marks]
4.0 QUERYING THE COLLECTIONS [30 marks]
Write the following queries (Q1 to Q10) against the collections that you personalised and loaded you’re your local MongoDB. For each query, submit the MongoDB command in plain text, AND present it with its results as a screenshot showing the command and the documents returned. For example:
//Q1001. Find the details of the product identified as " B001KTEBOG ".
db.products.find({product_id: 12345678})
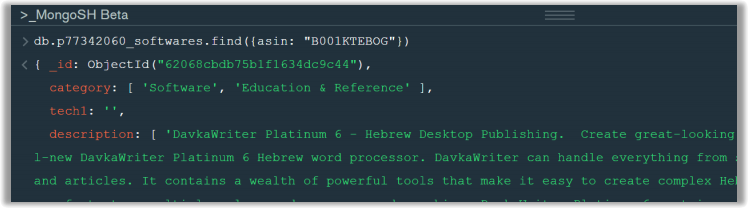
If a lot of documents are returned, show the first set of documents that are displayed. Ensure that what is displayed answers the requirements and demonstrates that the query is correct. You must do this to gain all the marks available for a question.
Q1. Find top 3 products with highest average rating above 3.5 and are not e-books. Display only product_id, title, price, product_type and average rating. [3 marks]
Q2. Who is the most famous reviewer in your dataset? Most famous reviewer have the highest number of 5-rated reviews in your datasets. Display the user_id, average rating, average n_votes, total n_comments and total number of reviews written by this reviewer. [4 marks]
Q3. Update all reviews written by the most famous reviewer from Q2 by adding a new field named most_famous and set its value to true. [2 mark]
Q4. Using reviews and products collections, find the title, product_type and price of 3 most expensive products
|
reviewed by the most famous reviewer. No other product details are required. |
[6 marks] |
|
Q5. Retrieve the average price for each product_type. |
[2 mark] |
|
Q6. Find the product type with the highest average price. |
[1 mark] |
|
Q7. Find the top-5 products with most genres. |
[3 marks] |
|
Q8. Which author published the most products? |
[2 mark] |
|
Q9. Determine the top 5 genres with highest appearance in your dataset |
[3 marks] |
Q10. Calculate the price range (difference between maximum and minimum prices) for each product type in the collection. [4 marks]
5.0 IMPLEMENT AND EXPLAIN INDEX FOR THE DATABASE [10 marks]
1. Identify the chosen query from Section 4 and explain/justify your choice of index. Why do you think indexing could improve the query? [3 marks]
2. Implement one index that would improve the querying of the database based on one of the queries (Q1-Q10) in Section 4. [1 mark]
3. Present the execution plan of the selected query before the index and after the index has been created. Compare and discuss the execution plans to support your choice and summarise your findings. [7 marks]
6.0 RE-DESIGN THE DATABASE USING AGGREGATE DATA MODELLING [25 marks]
Write code in MongoDB to automatically embed the details of authors from authors collection and genres from genres collection with their corresponding product in the products collection. This is an aggregate data modelling (ADM) question. Therefore, the books collection will contain the product data, authors data and genre data in a single collection of products. This requires the following tasks:
1. Make new copy of the pxxxxxx_products collection and name it pxxxxxx_products_adm. [1 mark]
2. Embed all the authors and genres of products into their corresponding product using the new pxxxxxx_ products _adm collection. [6 marks]
3. To verify that the changes to the new products collection were successful, display the title, authors, and genre of the products with highest number of genres. [2 mark]
4. Note that there is no longer need to reference the product_id inside each genre or author_id inside each product now that they are part of the book in pxxxxxx_ product_adm collection. Show that these are removed from the pxxxxxx_ product_adm collection only. [3 marks]
5. Using $lookup operator, fetch the complete information of 50% of books with their authors and genres using pxxxxxxx_products collection. Track the execution plan of the query. [3 marks]
6. Using the pxxxxxx_ product_adm collection, fetch the same information as above. Track the execution plan of the query. [3 marks]
7. Compare the performance results of 7(5) & 7(6) above and write a brief discussion about the results explaining why the may differ. [5 marks]
All tasks must each be fully automated by writing code. Note that some tasks may take many seconds or minutes to execute depending on the machine.
7.0 WEEKLY JOURNALS [10 marks]
Report 4 journal submissions from week 5 by completing the table below:
|
Week No |
Status/Reason |
|
5 |
For example (Submitted on time) |
|
6 |
For example (Late submission due to xyz) |
|
8 |
For example (No submission due to abc) |
|
9 |
For example (Submitted on time) |
8.0 DELIVERABLES
1. You are required to upload your answers to the questions into Turnitin on Blackboard as one PDF file. Do NOT submit any JSON file.
2. Add your P number to your filename.
3. Your file must be in a readable format so the NoSQL code in plaintext can be copied and executed from it.
9.0 CLOSING COMMENTS
1. This is an individual assignment. Do not negotiate with others to clarify what is required. By uploading your work to LearningZone, you will be declaring that the work you submit is your own and not plagiarised in anyway.
2. Tutors are prepared to offer help with the part of the assignment where there is clear evidence that you have made a substantial attempt but have become stuck.
3. Mark totals are shown alongside each question. Your tutor will need to able to execute your NoSQL code in MongoSH to check for correctness. Marks will be awarded for correctness and presentation.
4. Marks will typically be deducted if information is erroneous, missing, irrelevant or difficult to ascertain. Marks can also be deducted if the answer is particularly inefficient. Therefore, partial marks are available if an answer is partially corrector partially presented.
5. There is often more than one way to answer a question and so it is possible to gain full marks for an answer even if it is different from the markers' specimen set of answers. However, if these answers do not follow the examples and exercisestaughton the module, they maybe inferior in some way and so consequently marks maybe deducted. Note that some questions hint at the most appropriate method to use.
10. REFERENCES
R. He, J. McAuley. "Modeling the visual evolution of fashion trends with one-class collaborative filtering". WWW,
2016.
J. McAuley, C. Targett, J. Shi, "A. van den Hengel. Image-based recommendations on styles and substitutes". SIGIR,
2015.
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
2024-02-22