CS 1100 – Computer Science and Its Applications Topic 6
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
CS 1100 – Computer Science and Its Applications
Topic 6: Working With Text
How to Get Started
To get started, download the starter file from Canvas.
What to Turn in
You must submit your solution to Canvas by the due date. You will be modifying a starter workbook using Microsoft Excel. When you finish the assignment, save the file and upload the .xlsx (or .xls) file to Canvas. You must name the file
LastName-FirstName .strings
where LastName is your lastname and FirstName is your full first name.
Knowledge Needed
This assignment involves the following Excel functions and techniques:
. LAMBDA, LET, FIND, LEFT, MID, RIGHT, TRIM, NUMBERVALUE, IF, IFERROR, COUNTIFS, TEXT, VALUE, VLOOKUP, INDEX, MAP, MAX
. Predefined Excel functions that you implement in simplified form: TEXTBEFORE, TEXTAFTER, TEXTSPLIT, TAKE
. Additional Functions: UNIQUE, TRANSPOSE, SORT, SEQUENCE, XLOOKUP,XMATCH, FILTER.
. 3-D references, Formatting.
Keep![]() in
in![]() mind
mind![]() that
that![]() how
how![]() you
you![]() express
express![]() the
the![]() formulas
formulas![]() matters.
matters.![]() Spreadsheets
Spreadsheets![]() should
should![]() reflect
reflect![]() any
any![]() legal
legal![]() changes to
changes to![]() the
the![]() data
data![]() such
such![]() as
as![]() adding/removing
adding/removing![]() rows
rows![]() and
and![]() changing
changing![]() values
values![]() in
in![]() cells.
cells.![]()
All![]() formulas
formulas![]() should
should![]() be
be![]() dynamic
dynamic![]() which
which![]() spill
spill![]() correctly
correctly![]() to
to![]() the
the![]() desired
desired![]() cells.
cells.![]() You
You![]() can
can![]() test
test![]() your
your![]() formula
formula![]() by adding
by adding![]() or
or![]() deleting
deleting![]() rows
rows![]() from
from![]() the
the![]() data
data![]() set.
set.![]() Try
Try![]() to
to![]() use
use![]() a
a![]() min
min![]() mum
mum![]() number
number![]() of
of![]() formulas.
formulas.![]()
It’s![]() okay
okay![]() to
to![]() copy
copy![]() formulas
formulas![]() across
across![]() columns
columns![]() as
as![]() long
long![]() as
as![]() you
you![]() are
are![]() not
not![]() using
using![]() any
any![]() anchoring(’$’)
anchoring(’$’)![]() and
and![]() there
there![]() is
is![]() no easy
no easy![]() way
way![]() to
to![]() use
use![]() a
a![]() dynamic
dynamic![]() formula.
formula.
LAMBDAs in this assignment
Remember from assignment 5 and the syllabus that you need 3 items for each LAMBDA: Function Template, Convincing Argument Chat link, Formula Derivation Chat link.
1. LAMBDA TAKECSA simulating a simple form of TAKE
2. LAMBDA TEXTBEFORECSA simulating a simple form of TEXTBEFORE
3. LAMBDA TEXTAFTERCSA simulating a simple form of TEXTAFTER
4. LAMBDA exam_percentage_rule corrected. Use ChatGPT to find the typo by describing the grading rules in English as a specification. Then, let ChatGPT check the function against its specification.
Problem 1 App Market Intelligence (40 points)
The sales department at aoun.com received information about a list of popular apps, which is in app market data. The data came as a list of strings instead of using separate fields for name, downloads (ios or android), company who owns the app, and the current userbase.
The information provided a data description document with the structure of the data. It identifies every field that may appear and the layout, which specifies the order of the fields and how each is delimited. It also means that the field’sending or last delimiter may not appear within the field. The layout is:
App_Name ,IOS ,Android — Company
The red characters are the delimiters and these characters are the field names. Often in practice, you may see fields marked as
Required means, at a minimum, that every field must be present, meaning it is not optional. Optional fields may be missing but should be represented by its delimiter. Optional field is a field that may not have a value. Let’s look at an example. The first line of our data is
Messenger,5,8.5 - Facebook <1.2B>
Suppose the data is corrupt; the app’s name is missing. Instead the data you should look like
,5,8.5 - Facebook <1.2B>
Here,
This is an example of what’s called syntax and semantics. Syntax concerns the structure of the string: e.g., is it required, how long it can be or what characters are allowed. Semantics concerns the string’s meaning. Here, syntax says the field has to be present, meaning delimited. Semantics would say whether the string may be empty or have certain values. For example, you could specify the company must be a registered company.
The assignment:
1. Transform the data in Column A into an Excel Table, rename it AppData.
2. Introduce a named cell called k. k may have any value between 1 and the number of rows in AppData. In column C put the first k rows of table AppData by using the FILTER function.
You benefit from defining this functionality as a function because you need it twice in the assignment. Excel for Microsoft 365 also has a function for this purpose. It is called TAKE (or DROP), but you are not allowed to use it because we want you to practice writing your functions. You must write a function TAKECSA simulating a simple form of the Microsoft TAKE function without using Microsoft’s TAKE function. Refer to the TAKE function in Microsoft’s documentation. You might want to consider using FILTER or INDEX to implement TAKECSA.
3. Use helper columns to the right of column I to help extract the values for columns C through I, see Figure 1. Please use column L as the first helper column for extracting the first field.
To extract the fields, write two helper functions using LAMBDA and the name manager. Name them, TEXTBEFORECSA and TEXTAFTERCSA. The functions you are creating are modelled after Excel’s TEXTBEFORE and TEXTAFTER functions. Please review TEXTBEFORE docu-
mentation with this link. Please also review the documentation for TEXTAFTER with this link. The TEXTBEFORECSA returns text that occurs before a given character or string. It is the opposite of the TEXTAFTERCSA function.
=TEXTBEFORECSA(text,delimiter)
The TEXTBEFORE function has the following arguments:
. text The text you aresearching within. Wildcard characters, such as * and ? are not allowed.
If text is an empty string, it should return the empty text "".
. delimiter The text that marks the point before which you want to extract.
The TEXTAFTERCSA function returns text that occurs after a given character or string. It is the opposite of the TEXTBEFORECSA function.
=TEXTAFTERCSA(text,delimiter)
The TEXTAFTERCSA function has the following arguments:
. text The text you are searching within. Wildcard characters such as * and ? are not allowed in the text.
. delimiter The text that marks the point after which you want to extract.
Use the Excel Text functions such as FIND, LEFT, RIGHT, etc., to implement the two helper functions. Ensure you can handle delimiters of any length not just single character delimiters.
You will need to use both TEXTBEFORECSA and TEXTAFTERCSA for each extracted field. If you are extracting 4 columns, you will need 8 helper columns. Here, it is appropriate to use copying and pasting to the right unless you engage ChatGPT to help you do the iteration automatically
using the REDUCE function. For each extracted field, you control the behavior from the top three rows of the two columns. The first row contains the delimiter. The second row contains a comment indicating whether it is a BEFORE or AFTER column. All the work is done by the formulas in the third row using hashtag and regular references. Here is a possible snapshot where the delimiter is a comma.
,
BEFORE AFTER
=TEXTBEFORECSA(Ref_1#,Ref_2) =TEXTAFTERCSA(Ref_1#,Ref_2)
where Ref__1# refers to a dynamic array containing the data to be processed (computed the first time by TAKECSA and thereafter by TEXTAFTERCSA. Ref_2 is a reference to a delimiter cell. This 3 by 2 matrix you copy to the right until you have extracted all columns. Each time you copy to the right, the column coordinates shift by two columns to the right (e.g., column X becomes column Z). You must carefully initialize this process by bringing the initial data into a helper column. You also need to update the delimiters in the first row carefully. Please document and develop the LAMBDA functions using a separate worksheet and follow the Function Template.
4. Once your helper columns have the extracted fields, write a formula to copy the values from the appropriate helper column to fill in columns E through I.
5. Format your solution as shown in Figure 1 when k=11.
Important: As a design goal, your aim should be to develop a small number of reusable formulas that you can also reuse across problems. Points will be deducted if you have extra trailing or leading spaces in your answers.
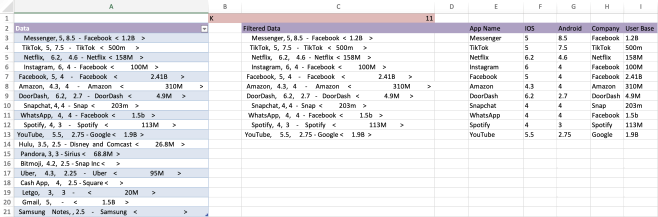
Figure 1: What your sheet for Problem 1 should look like
Problem 2 Bookstore Sales (25 points)
Important: Insert an additional empty B column to the starter file to separate the input data from the output. Then, you can use the column names used below.
A bookstore would like to determine what kinds of books were sold on a particular day. Data has been downloaded into a spreadsheet shown in the worksheet bookstore sales. The downloaded data may contain leading or trailing spaces due to a defect in the download program. In this problem, we define the syntax of the book information using the widely used EBNF notation. The following syntax rule describes each book:
BookTitle "by" AuthorName ["," FormatCode]
BookTitle is not allowed to contain by. AuthorName is not allowed to contain a comma. The square brackets indicate that FormatCode is an optional field. The presence of a comma after the AuthorName indicates that the FormatCode is in the input. The absence of a comma after the AuthorName means that the FormatCode is absent.
1. Transform the data in Column A into an Excel Table, rename it BookData.
2. Create an Excel Table named BCODES for the data below to find the Type given the format code:
|
Format Code |
Type |
|
HC |
Hardcover |
|
PB |
Paperback |
|
EB |
Ebook |
|
AB |
Audio Book |
3. In column C, extract the title of each book.
4. In column D, extract the author of each book
5. In column E, extract the format code of each book. Be sure to handle codes with leading and trailing spaces.
6. In column F, insert the type associated with the book’s format code. Format code is an optional field, which means the format code may be missing. If the field is missing, keep the cell empty for the Format Code column and put the value UNKNOWN in the Format column.
7. Generate headers for columns G through J using the Format Code column in the BCODES table. Use TRANSPOSE, and SORT to create the headers from the BCODES table as well as a LOOKUP function to retrieve the book type values from BCODES.
8. Create one formula to count (using COUNTIFS) the data for each book format in columns G through J.
9. Find the percentage of each format sold with respect to all formats (except UNKNOWN). Store the percentage at the bottom of each column (G:J). Use one dynamic formula that is NOT duplicated.
10. Format your solution as shown in Figure 2.
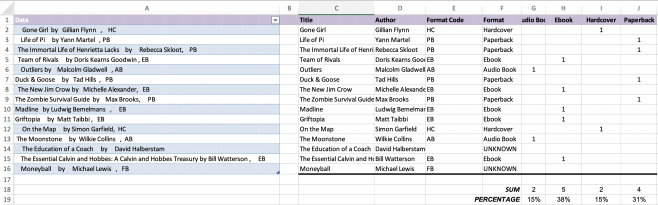
Figure 2: What your sheet for Problem 2 should look like.
Problem 3 Computing your Exam Percentage, Program Debugging, Testing and Repairing Formulas (35 points)
We work with the function exam_percentage_rule, which implements the computation of your exam percentage according to our syllabus. Implement the function using a LAMBDA:
LAMBDA(TH,E_1,E_2,M_1,M_2,LET(...))
The connection to the syllabus should be easy: TH (Take Home), E__1 (Exam 1), E__2 (Exam 2), M__1 (Makeup 1), M__2 (Makeup 2). In each exam, you can make between 0 and 100 points. I’d appreciate it if you could carefully review the relevant parts of the syllabus, which serves as specification for what needs to be implemented. Your function must use the MAX function to implement the rule regarding TH and E__1.
Could you implement the following versions of function exam_percentage_rule?
. OneStep version. The function works correctly for one student.
. Manual ManySteps version. The function works correctly for five students by dragging down the OneStep formula five rows.
. Automatic ManySteps version using MAP. Fill out the Function Recipe only for this corrected solution. The function must work correctly for any number of students. This is intended for a large MOOC class that might have 500 students. The following function “almost” solves the problem but requires a correction.
=LAMBDA(TH,E_1,E_2,M_1,M_2,LET(
COMMENT0,"Calculate exam percentage many students (weighted percentage)",
COMMENT1,"Function for make-up exam rule . make-up exam =0 means: exam not taken", override,LAMBDA(exam,mu_exam, IF(mu_exam=0,exam,mu_exam)),
exam_weights, {0.06,0.25,0.25},
TH_real,MAX(TH,E_1),
TH_real_1,MAP(TH,E_1,LAMBDA(t,e,MAX(t,e))),
TH_real_2,IF(E_1>TH,E_1,TH),
E_1_real,override(E_1,M_1),
E_2_real,override(E_2,M_2),
unweighted_exam_percentages,HSTACK(TH_real,E 1 real,E 2 real),
weighted,exam_weights*unweighted_exam_percentages,
result,BYROW(weighted,LAMBDA(row,SUM(row))),
ShowHeader,HSTACK("exam_weights","","","TH_real","E_1","E_2","weighted","","","result"), Show, IFERROR(VSTACK(
ShowHeader,
HSTACK(
IFERROR(exam_weights,"exam_weights problem"),
IFERROR(TH_real,"TH_real problem"),E 1 real,E 2 real,weighted,
IFERROR(result,"result problem"))),""),
Show))(GradeT[TH],GradeT[E_1],GradeT[E_2],GradeT[M_1],GradeT[M_2])
Our task is to write a function that computes the grade for any number of students without using dragging. In this situation, we need to look for non-spilling functions like MAX, MIN, SUM, AND, OR that are aggregators, i.e., they produce one output. We have multiple options available.
. Use the MAP function to reduce the problem to single-cell arguments.
. Rewrite the function so that it becomes spilling. For example, AND(a,b) can be rewritten as a ∗b = 1, which is spilling. TRUE has value 1 and FALSE has value 0.
. Use BYROW and HSTACK to apply the function row by row. But this has limitations.
Create a worksheet called Exam Percentages and put all three versions of the function exam_percentage_rule in it. Create the Excel table GradeT given below. For the first version use the first row of GradeT. For the second version use all 5 rows through dragging. For the third version, give all 5 rows as input.
TH E_1 E_2 M_1 M_2
100 0 85 100 100
0 100 100
50 80 90 100 100
0 50
50 100 95
Test your solution carefully. For table GradeT, the output should be:
56
56
54.8
15.5
54.75
Note that 44% are allocated for the non-exam grade.
Appendix
For problems 1 and 2, instead of using helper cells and helper columns on the right, you can also use a long LET that repeats the same steps repeatedly. It is possible to use the REDUCE function (a LAMBDA helper function provided by Excel 365) to eliminate all repetition. We will look into this later.
next_delim_1,CHOOSECOLS(delims,1),
curr_rest_1,TAKE(acc_1,,-1),
first_1,TRIM(TEXTBEFORECSA(curr_rest_1,next_delim_1)),
rest_1,TEXTAFTERCSA(curr_rest_1,next_delim_1),
acc_2,HSTACK(acc_1,next_delim_1, first_1, rest_1),
next_delim_2,CHOOSECOLS(delims,2),
curr_rest_2,TAKE(acc_2,,-1),
first_2,TRIM(TEXTBEFORECSA(curr_rest_2,next_delim_2)),
rest_2,TEXTAFTERCSA(curr_rest_2,next_delim_2),
acc_3,HSTACK(acc_2,next_delim_2, first_2, rest_2),
2024-02-17
Working With Text