COMPSCI 760 Datamining and Machine Learning Collection of exam questions
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
COMPSCI 760
COMPUTER SCIENCE
Datamining and Machine Learning
Collection of exam questions
Note:
● This exam questions bellow are collected from the past few years. While the course exists longer, till 2019 it was the only CS course devoted to data mining and machine learning, and therefore covered a lot of fundamental topics that are now part of CS361 and CS762. Therefore most of the questions in the exam till 2019 (including 2019) are not from the topics we cover now. For your convenience, we extracted all relevant questions. We provide the weight of each question (marks). All of the questions were part of exam that were 120 min long and worth 120 marks in total.
● When a question requests to explain your answer, that means you need to justify how you came up with the solution or why you made a certain choice. Be concise and clear.
● The work must be your own. You are not allowed to copy text or code or solutions. This also means you are not allowed to just copy text from the slides. Use your own words when answering the questions.
1. Probabilistic Graphical Models ( / 59)
(a) (11 points) Suppose you are asked to predict a student’s pass/fail at a computer-based exam. You should consider the following factors of the student: (1) atten-dance at the lectures; (2) understanding of the lectures; (3) result of the mid-term test; and (4) proficiency on the computer. Design a Bayesian network for the task. Describe the variables and their causal relations. Draw the graphical structure and factorize the joint probability distribution based on the structure.
(b) (6 points) What are the independence assumptions of the model above? How does D-separation work in determining these independence assumptions?
(c) (10 points) Given the following three Bayesian networks G1, G2, G3 defined on the same set of random variables {A, B, C, D, E} in Figure 1, where G2 and G3 have exactly one edge different from G1 (made bold in the figure):
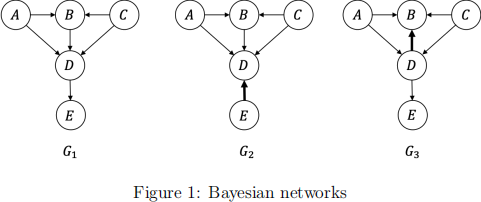
Answer the following questions:
1. Which of the variables are independent of A in G1? Are those variables also independent of A in G2 and G3, respectively?
2. Which of the variables are conditionally independent of E given D in G1? Are those variables also conditionally independent of E given D in G2 and G3, respectively?
3. Does a Markov Random Field exist such that it is a perfect map to G1? Give an example if it exists. Otherwise, explain the reason.
(d) (17 points) You are tasked with developing a Bayesian network to predict user mo-bility in Auckland. Assume we have k different locations, e.g., schools and restau-rants, and we divide the Auckland map into n × n grids, resulting in n2 small regions. Before travelling, a user U should choose a plan P, either study or enter-tainment, based on his/her preference and the day of the week D (either weekday or weekend). For instance, students often study on weekdays. The user then decides which region R to travel to based on the plan. Different users will have different preferences for regions given the same plan. The final decision of visiting a location L should depend on the user, the region (i.e., the location should fall in the region) and the time of day T. The time takes a value from one of the 24 hours.
1. (6 points) Give a Bayesian network on the variables {U, L, P, D, R, T} for the above task. Draw the graphical structure and factorise the joint probability distribution p(U, L, P, D, R, T) based on your Bayesian network.
2. (5 points) Suppose we have m users and k locations in Auckland. Write down the representation cost of your model as a function of k, m, n.
3. (6 points) List at least two problems of modelling geographical regions with the above n × n grids. Give an idea of how to better model the regions.
(e) (15 points) Answer the following questions about probabilistic inference.
1. (8 points) The Bayesian network in Figure 2 factorises p(A, B, C, D, X, Y). We want to infer the posterior distribution p(X|Y), where we need to eliminate A, B, C, D. Let all the variables be binary variables. We would like to find an elimination order that minimises the computational cost. However, finding the optimal order for variable elimination is NP-hard. Design a heuristic to select an elimination order that results in lower computation cost than random orders. Write down the elimination order and the computational cost in terms of number of multiplications.
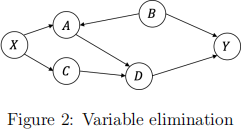
2. (7 points) Use one or two sentences to summarize how variational inference and Monte Carlo methods work, respectively. Compare these two inference techniques from at least three perspectives. For example, but not limited to, the computation cost in each iteration, convergence speed, and how they ap-proximate the true distribution.
2. Neural Networks ( / 29)
(a) (5 points) What is the main effect of using different activation functions? Discuss two activation functions which are currently commonly used functions and explain the pros and cons of both.
(b) (4 points) What are the three sets you normally break your data into? What is the purpose of each of the three sets? Which two sets is it the most important to have come from the same distribution? Why?
(c) (4 points) Explain how you can tell if you are in a high bias situation or in a high variance situation or both. Additionally, explain how you might approximate the optimal error rate and in what way that will help.
(d) (4 points) What is the main difference between underfitting and overfitting? How would you be able to tell whether these are the best results you can get on a given algorithm, or whether you have underfit or overfit?
(e) (4 points) What are simple formulas to address bias and variance issues? Explain your answer.
(f) (4 points) Why does dropout cause regularisation?
(g) (4 points) Explain what vanishing and exploding gradients are and what techniques you can use to try to avoid them.
3. Fairness in Machine Learning & Adversarial Learning ( / 51)
(a) (5 points) Is overall accuracy a good measure for model performance when we have biased datasets? Explain, and if possible, illustrate your answers using a toy exam-ple. Provide real-world applications in which this can happen (or has happened), including the source of the bias.
(b) (6 points) Explain how machine learning can end up being unfair without any ex-plicit wrongdoing? Address at least two issues at each step of the machine learning pipeline (with a real-world example or scenario that illustrates this).
(c) (6 points) What observational (statistical) criteria for measuring algorithmic fair-ness did we discuss? Explain in your words what they mean. Under what assump-tions are they defined?
(d) (4 points) In your own words, explain what are the advantages and disadvantages of the observational fairness measures in the context of automated consequential decison-making?
(e) (5 points) Which of these criteria assess fairness of model scores and which ones assess the fairness of model decisions? Does fairness in terms of model scores imply fair decisions? Justify your answer.
(f) (10 points) Propose an idea for an algorithm based on adversarial learning that could achieve fairness with respect to on of the fairness measures we discussed. What will be the input and output of this algorithm? Will you classify the proposed algorithm as a pre-processing, post-processing or in-processing (during training) approach to fairness? Explain your answers.
(g) (5 points) Briefly explain the 1-pixel attack. Are there limitations depending on specific characteristics of the data? When does it work well, when does it not work well? Could you apply the same method to non-image data sets?
(h) (5 points) Given the SVM poisoning attack discussed in class, can an evasion de-fence strategy be used to defend against this attack? Which one would you choose and how would you modify it?
(i) (5 points) Are ensemble methods more or less vulnerable to adversarial attacks? Are there certain ensemble methods that are particularly easy to attack, and if so, why? [Note: Ensembles are now covered in CS361/762, both prereqs for CS760. While we do not expect you to remember details, conceptually you should be able to answer at least the first subquestion.]
2021-10-21