EEE6213 Software Assignment.
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
EEE6213 Software Assignment.
Learning Efficiency of a neuromorphic device in an Artificial Neural Network (ANN).
Goal: To emulate the online learning/offline classification capability of a 2-layer multilayer perceptron (MLP) neural network that is based on emerging non-volatile memory (eNVM). The task is based on image recognition that will rely on the MNIST handwritten dataset.
Objectives:
• To estimate the system-level performance of 4 reference analog synaptic devices from the literature [2-5].
• To evaluate the learning accuracy using different training algorithms.
• To evaluate circuit-level performance metrics, such as chip area, latency, dynamic energy and leakage power.
Device Data:
• The users will need weight update characteristics (conductance vs. # pulse), provided in the tables for each device at the end of this document.
• Device parameters such as the number of levels, weight update nonlinearity, device- to-device variation, and cycle-to-cycle variations (also in the tables)
System Requirements:
• The neurosim tool that you will use runs in linux with required system dependencies installed. These include GCC, GNU make, GNU C libraries (glibc).
• 16 GB of RAM recommended (but not necessary). You can run your simulations overnight on your allocated PCs.
• Intel i5/ i7 recommended.
Software tool Neurosim (https://github.com/neurosim/MLP_NeuroSim_V3.0, [1]):
• NeuroSim is a software that provides a flexible interface between the neuromorphic hardware used for implementing the Neural Network, and Neural Network algorithms.
• With NeuroSim,an integrated framework can be built with a hierarchical organization, that can be broken down into three levels:
1. The device level (type of synaptic device such as a Resistive Random Access Memory (ReRAM) or a Ferro-electric FET (FeFET)
2.The circuit level (Circuit in which the device is embedded, either a crossbar or pseudo-crossbar array architecture)
3. The algorithm (the Neural Network topology for example, a 2-layer multi layer perceptron (MLP))
• NeuroSim provides a dual solution: It evaluates the learning accuracy of the Neural Network (NN) algorithm as well as benchmarks different neuro-inspired architectures at the algorithm runtime.
Multilayer Perceptron (MLP):
• A basic 2-layer Multilayer Perceptron Neural Network consists of an input layer, hidden layer and an output layer.
• The leftmost layer in this network is the input layer, and the neurons within the layer are called input neurons.
• The rightmost or output layer contains the output neurons, or, as in this case, a single output neuron.
• The middle layer is called a hidden layer, since the neurons in this layer are neither inputs nor outputs.
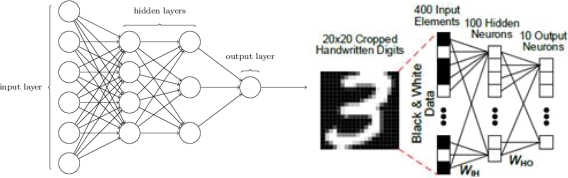
Figure 1. Principle of a Multilayer Perceptron [ Figure taken from Neurosim manual V3, https://github.com/neurosim/MLP_NeuroSim_V3.0]
• The design of the input and output layers in a network is quite straightforward. Take for example a task, to determine whether a handwritten image depicts a “3” or not. A natural way to design the network would be to encode the intensities of the image pixels into the input neurons. If the image is a 20 by 20 greyscale image, then we'd have 20x20=400 input neurons, with the intensities scaled appropriately between 0 and 1.
• The output layer will contain just a single neuron, with output values of less than 0.5 indicating "input image is not a 3", and values greater than 0.5 indicate "input image is a 3 ".
• The design of hidden layers is more heuristic in nature.
MNIST data
• The widely known MNIST dataset comes in two parts.
(i)The first part contains 60,000 images to be used as training data. These images are scanned handwriting samples from 250 people,half of whom were US Census Bureau employees, and half of whom were high school students. The images are greyscale and 20 by 20 (cropped) pixels in size.
(ii)The second part is 10,000 images to be used as test data. Again, these are 20 by 20 greyscale images.
• To make this a good test of performance, the test data was taken from a different set of 250 people than the original training data.

Figure 2. A sample of MNIST Data [http://yann.lecun.com/exdb/mnist/]
Weight Storage and Implementation of a Neural Network using a Memristor
• Neuromorphic hardware comes into play to store the weights of the NN described above. Weights are represented using multi-level conductance states of the memristor device.
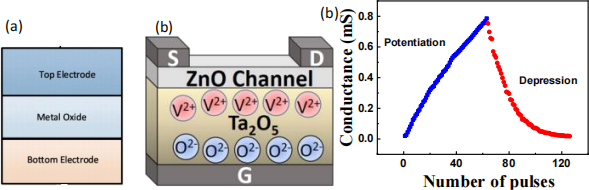
Figure 3 reproduced from Ref [2]. (a) Schematic illustration of a two terminal memristor device. (b) Schematic of a Ta2O5/ZnO solid electrolyte gate thin film transistor (SE-FET) a three terminal memristor device and (c) Measured conductance value of SE-FET for identical pulse-schemes ± 1V/60ms for Potentiation as well as depression characteristics.
•
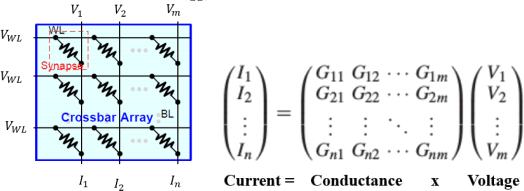
Figure 4. A crossbar array showing the connections of memristors and the corresponding matrix multiplication [Figure taken from Neurosim manual V3, https://github.com/neurosim/MLP_NeuroSim_V3.0].
• In the back-propagation phase, ie, the phase where the error in the output gets fed back into the input, as in supervised learning), the weight update values (ΔW) are translated to the number of long term potentiation (LTP) or long term depresssion (LTD) write pulses within NeuroSim. These use the behaviour of the conductance change with number of pulses for that particular device.
• The calculated number of write pulses are then applied to the synaptic array to update the weights to the desired value of conductance.
• The weight update curve is specific to each device and depends on the device properties. Ideally, the amount of weight increase (or long-term potentiation, LTP) and weight decrease (or long-term depression, LTD) should be linearly proportional to the number of write pulses.
• Weights are updated at each epoch in the hardware during training, and then the saved weights can be used subsequently at the time for classification. One Epoch is when an ENTIRE dataset is passed forward and backward through the neural network only once.
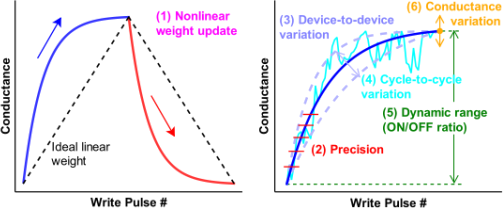
Figure 5. Conductance vs Write Pulse [Figure taken from Neurosim manual V3, https://github.com/neurosim/MLP_NeuroSim_V3.0].
Procedure:
1) Select the synaptic device type in main.cpp
• Firstly, select the synaptic device type for the two synaptic cores, (input to hidden and hidden to output), corresponding to two arrays.
• Available device types are RealDevice, IdealDevice, MeasuredDevice, DigitalNVM and SRAM.
• The default configuration is RealDevice for both synaptic cores, as shown below in main.cpp:
arrayIH->Initialization
arrayHO->Initialization

Figure 6. Screenshot of main.cpp file showing device type initialization for inputs to both the hidden and hidden to output layers.
2) Modify the device parameters in Cell.cpp
• After selecting the synaptic device type, the users may wish to modify the device parameters in the corresponding synaptic device class in the file Cell.cpp
.
• Device parameters such as number of conductance state, Nonlinearity (weight increase/decrease), max conductance, min conductance, weight increase/decrease pulse, cycle-to-cycle variation.

Figure 7. Screenshot of main.cpp file showing various device parameters.
3) Modify the network and hardware parameters in Param.cpp
• Users may wish to modify the network and hardware parameters in Param.cpp.
• For the network side, numMnistTrainImages and numMnistTestImages are the number of images in MNIST during training and testing respectively, numTrainImagesPerEpoch means the number of training images per epoch,
• In addition,nInput, nHide and nOutput are the number of neurons in the input, hidden and output layers in the 2-layer MLP neural network, respectively.
4) The users can also use different training algorithms [Neurosim manual]
• List of training algorithm available in Neurosim tool.
i. “SGD”: stochastic gradient descent
ii. “Momentum”: the momentum method.
iii. “Adagrad”: the self-adaptive gradient descent method.
iv. “RMSprop”. It is an unpublished adaptive learning rate method proposed by Geoffrey Hinton .
v. “Adam” : Adaptive Moment Estimation.
• This feature can be specified by changing the parameter “optimization_type” under param.cpp. (filename in neurosim tool).

Figure 8. Screenshot of Param.cpp file showing various algorithm parameters.
5) Compilation of the program
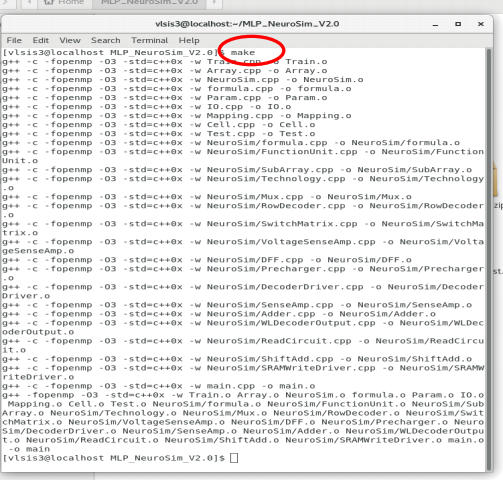
• Whenever any change is made in the files, the codes has to be recompiled by using the make command as stated in Installation and Usage (Linux) section.
• If the compilation is successful, the following screenshot can be expected: 6) Run the program
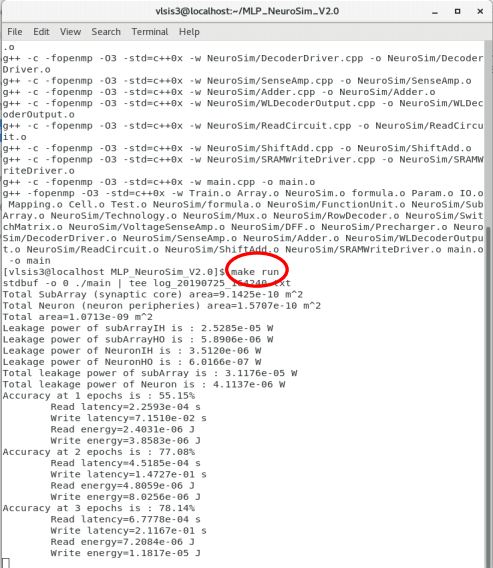
Then, use make run to run the program. The program will print out the results at every epoch during the simulation.
• With the default value of totalNumEpochs=125 and
numTrainImagesPerEpoch=8000 for a total of 1 million MNIST images, the simulation will approximately take about 1 hour with an Intel i7 CPU and 32 GB RAM.
A summary of useful commands is provided below. It is recommended to execute these commands under the tool’s directory:
|
Command |
Description |
|
make |
Compiles the codes and builds the “main” program |
|
make clean |
Cleans up the directory by removing the object files and the “main” executable |
|
make run |
Run simulation (after make), and the results will be saved to a log file (filename appended with the current time info). This command does not work if “stdbuf” is not found. |
Device data set1:
|
Analog eNVM synapses |
Ag:a-Si [3] |
|
# of conductance states |
97 |
|
Nonlinearity (weight increase/decrease) |
2.4/-4.88 |
|
maxConductance |
3.84e-8 |
|
minConductance |
3.07e-9 |
|
Weight increase pulse |
3.2V/300μs |
|
Weight decrease pulse |
-2.8V/300μs |
|
Cycle-to-cycle variation |
0.035 |
Table 1: Device data set needed for your simulations from [3]
Device data set 2:
|
Analog eNVM synapses |
TaOx/TiO2 [4] |
|
# of conductance states |
102 |
|
Nonlinearity (weight increase/decrease) |
1.85/- 1.79 |
|
maxConductance |
2.00e-7 |
|
minConductance |
1.00e-7 |
|
Weight increase pulse |
3V/40ms |
|
Weight decrease pulse |
-3V/10ms |
|
Cycle-to-cycle variation |
0.001 |
Table 1: Device data set needed for your simulations from [4]
Device data set 3:
|
Analog eNVM synapses |
PCMO [5] |
|
# of conductance states |
50 |
|
Nonlinearity (weight increase/decrease) |
3.68/-6.76 |
|
maxConductance |
4.34e-8 |
|
minConductance |
6.35e-9 |
|
Weight increase pulse |
-2V/1ms |
|
Weight decrease pulse |
2V/1ms |
|
Cycle-to-cycle variation |
0.001 |
Table 3: Device data set needed for your simulations from [5]
Device data set 4:
|
Analog eNVM synapses |
AlOx/HfO2 [6] |
|
# of conductance states |
40 |
|
Nonlinearity (weight increase/decrease) |
1.94/-0.61 |
|
maxConductance |
5.91e-5 |
|
minConductance |
1.33e-5 |
|
Weight increase pulse |
0.9V/100μs |
|
Weight decrease pulse |
- 1V/100μs |
|
Cycle-to-cycle variation |
0.05 |
Table 4: Device data set needed for your simulations from [6]
References:
[1] P. Y. Chen, X.Peng, S.Yu, “NeuroSim+: An integrated device-to-algorithm framework for benchmarking synaptic devices and array architectures”, IEEE International Electron
Devices meeting, 2017, USA.
[2]. P. Balakrishna Pillai and M. M. De Souza, “Nanoionics-Based Three-Terminal Synaptic Device Using Zinc Oxide,” ACSAppl. Mater. Interfaces, vol. 9,no. 2,pp. 1609– 1618, 2017. [3]. S. H. Jo, et al. "Nanoscale memristor device as synapse in neuromorphic systems." Nano Letters, 10.4 (2010): 1297- 1301.
[4]. W. Wu, et al. "A methodology to improve linearity of analog RRAM for neuromorphic computing." IEEE Symposium on VLSI Technology, 2018.
[5]. S. Park, et al. "Neuromorphic speech systems using advanced ReRAM-based synapse." IEEE International Electron Devices Meeting, 2013.
[6]. J. Woo, et al. "Improved synaptic behavior under identical pulses using AlOx/HfO2
bilayer RRAM array for neuromorphic systems." IEEE Electron Device Letters, 37.8 (2016): 994-997.
Acknowledgement:
[1] Support of Ankit Gaurav, X. Song, S. K. Manhas and M. M. De Souza, via SPARC
project “Non-filamentary three-Terminal Memristor Architecture for Bio-mimetic and Logic Design” funded by DST, India.
[2]Prof. ShimengYu, Georgia Institute of Technology for support with Neurosim+ tool.
2024-01-12
Learning Efficiency of a neuromorphic device in an Artificial Neural Network (ANN).