INT411: Reinforcement Learning Fall Semester Lab 4: Policy Gradient
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
INT411: Reinforcement Learning
Fall Semester
Lab 4: Policy Gradient
4.1 Objectives
• Understand the knowledge on policy gradient and its variant.
• Implement the policy gradient and its variant on the cliff walking problem under the framework of pytorch .
4.2 Problem Statements
Consider the gridworld shown below. This is a standard undiscounted, episodic task, with start and goal states, and the usual actions causing movement up, down, right, and left. Reward is -1 on all transitions except those into the region marked ’The Cliff’ Stepping into this region incurs a reward of -100 and sends the agent instantly back to the start.

Figure 4.1: Cliff Walking Example
The gym library is a collection of test problems (environments) that you can use to work out your rein-forcement learning algorithms. These environments have a shared interface, allowing you to write general algorithms. The following code is just an implementation for the classic ’agent-environment loop’. Each timestep, the agent chooses an action, and the environment returns an observation and a reward. The episode starts by calling reset() and terminates with the true flag returned by step() .
Please follow the following url to refer to the python gridworld library:
https://github.com/podondra/gym-gridworlds
import gym
import gym_gridworlds
env = gym.make(’Cliff-v0’)
for i_episode in range(20):
observation = env.reset()
for t in range(100):
print(observation)
action = env.action_space.sample()
observation, reward, done, info = env.step(action)
if done:
print("Episode finished after {} timesteps".format(t+1))
break
env.close()
4.3 Policy Gradient Algorithm
• (20 marks) Policy network: Output policy πθ(a|s) (a discrete distribution) with two-layer mulitple-layer perceptron fθ(s) for the current state s, where the non-linear activation function is a ReLU unit.
• (10 marks) Sampling step: Through the policy network, the currect action a is sampled for the current state s.
• (20 marks) Compute reward on the entire trajectory τi = {si1, ai1, r(si1, ai1), · · · , r(siT , aiT )}:
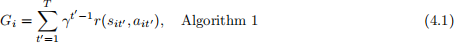
or reward with a “reward to go” way

where γ = 0.9.
• (20 marks) Calculate the loss function on τi in the following two ways

or

• (10 marks) Use Adam optimization algorithm to find the optimal parameters.
• (20 marks) Draw a figure to show the sum of rewards for each episode with the growing episodes for two algorithms (see Eqn. (4.1) and (4.2)).
4.4 Lab Report
• Write a short report which should contain a concise explanation of your implementation, results and observations.
For the score of each step, such as 15 points, the proportion of the three parts to the total score is as follows:
– Explanation of the execution of this step ( 50% ): how to design the data structure, how to design the algorithm to realize this step; how do you think about this problem
– Code and comments ( 30% ): Whether the code is correct, attach comments to help understand the code
– Results and interpretation ( 20% ): Whether the running results are correct, explain the results to a certain extent, or what you find from them. Please insert the clipped running image into your report for each step.
• Submit the report and the python source code with the suitable comments electronically into the learning mall.
• It is highly recommended to use the latex typesetting language to write reports.
• The report in pdf format and python source code of your implementation should be zipped into a single file. The naming of report is as follows:
e.g. StudentID LastName FirstName LabNumber.zip (123456789 Einstein Albert 1.zip)
4.5 Hints
Please refer to the lecture slides.
• Latex IDE: texstudio
• Python IDE: pycharm or vscode
• Use the python numpy, scipy library and matplotlib flexibly.
• Read the tutorial on pytorch
2023-12-29