CSE 250a. Assignment 3
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
CSE 250a. Assignment 3
3.1 Inference in a chain
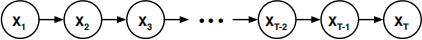
Consider the belief network shown above with random variables Xt∈ {1, 2, . . . , m}. Suppose that the CPT at each non-root node is given by the same m×m matrix; that is, for all t ≥ 1, we have:
Aij = P(Xt+1 =j|Xt =i).
(a) Prove that P(Xt+1 =j|X1 =i) = [At]ij , where At is the t th power of the matrix A.
Hint: use induction.
(b) Consider the computational complexity of this inference. Devise a simple algorithm, based on matrix-vector multiplication, that scales as O(m2t).
(c) Show alternatively that the inference can also be done in O(m3 log2 t).
(d) Suppose that the transition matrix Aij is sparse, with at most s≪m non-zero elements per row. Show that in this case the inference can be done in O(smt).
(e) Show how to compute the posterior probability P(X1 =i|XT +1 =j) in terms of the matrix A and the prior probability P(X1 =i). Hint: use Bayes rule and your answer from part (a).
3.2 More inference in a chain
Consider the simple belief network shown to the right, with nodes X0, X1, and Y1. To compute the posterior probability P(X1|Y1), we can use Bayes rule:
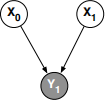
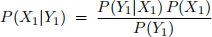
(a) Show how to compute the conditional probability P(Y1|X1) that appears in the numerator of Bayes rule from the CPTs of the belief network.
(b) Show how to compute the marginal probability P(Y1) that appears in the denominator of Bayes rule from the CPTs of the belief network.
Next you will show how to generalize these computations when the basic structure of this DAG is repeated to form a chain. Like the previous problem, this is another instance of efficient inference in polytrees.
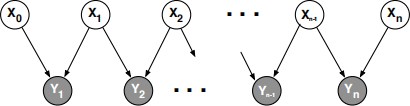
Consider how to efficiently compute the posterior probability P(Xn|Y1, Y2, . . . , Yn) in the above belief network. One approach is to derive a recursion from the conditionalized form of Bayes rule
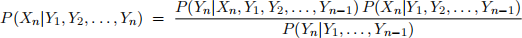
where the nodes Y1, Y2, . . . , Yn−1 are treated as background evidence. In this problem you will express the conditional probabilities on the right hand side of this equation in terms of the CPTs of the network and the probabilities P(Xn−1 =x|Y1, Y2, . . . , Yn−1), which you may assume have been computed at a previous step of the recursion. Your answers to (a) and (b) should be helpful here.
(c) Simplify the term P(Xn|Y1, Y2, . . . , Yn−1) that appears in the numerator of Bayes rule.
(d) Show how to compute the conditional probability P(Yn|Xn, Y1, Y2, . . . , Yn−1) that appears in the numerator of Bayes rule. Express your answer in terms of the CPTs of the belief network and the probabilities P(Xn−1 =x|Y1, Y2, . . . , Yn−1), which you may assume have already been computed.
(e) Show how to compute the conditional probability P(Yn|Y1, Y2, . . . , Yn−1) that appears in the de-nominator of Bayes rule. Express your answer in terms of the CPTs of the belief network and the probabilities P(Xn−1 =x|Y1, Y2, . . . , Yn−1), which you may assume have already been computed.
3.3 Node clustering and polytrees
In the figure below, circle the DAGs that are polytrees. In the other DAGs, shade two nodes that could be clustered so that the resulting DAG is a polytree.

3.4 Cutsets and polytrees
Clearly not all problems of inference are intractable in loopy belief networks. As a trivial example, consider the query P(Q|E1, E2) in the network shown below:

In this case, because E1 and E2 are the parents of Q, the query P(Q|E1, E2) can be answered directly from the conditional probability table at node Q.
As a less trivial example, consider how to compute the posterior probability P(Q|E1, E2) in the belief net-work shown below:

In this belief network, the posterior probability P(Q|E1, E2) can be correctly computed by running the polytree algorithm on the subgraph of nodes that are enclosed by the dotted rectangle:
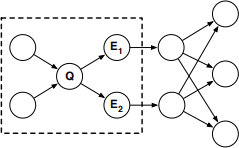
In this example, the evidence nodes d-separate the query node from the loopy parts of the network. Thus for this inference the polytree algorithm would terminate before encountering any loops.
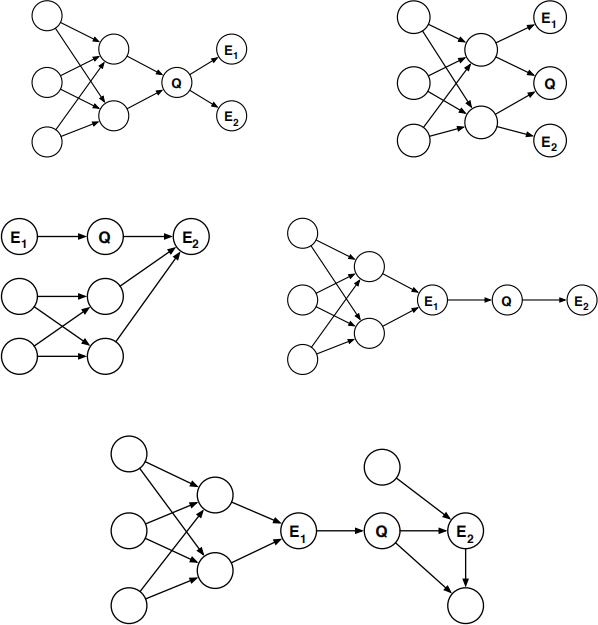
For each of the five loopy belief networks shown below, consider how to compute the posterior probability P(Q|E1, E2).
If the inference can be performed by running the polytree algorithm on a subgraph, enclose this subgraph by a dotted line as shown on the previous page. (The subgraph should be a polytree.)
On the other hand, if the inference cannot be performed in this way, shade one node in the belief network that can be instantiated to induce a polytree by the method of cutset conditioning.
3.5 Likelihood weighting
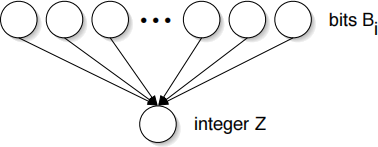
Consider the belief network shown below, with n binary random variables Bi∈ {0, 1} and an integer random variable Z. Let 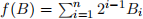 denote the nonnegative integer whose binary representation is given by BnBn−1 . . . B2B1. Suppose that each bit has prior probability P(Bi = 1) = 1/2
, and that
denote the nonnegative integer whose binary representation is given by BnBn−1 . . . B2B1. Suppose that each bit has prior probability P(Bi = 1) = 1/2
, and that
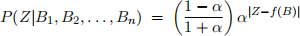
where 0 < α < 1 is a parameter measuring the amount of noise in the conversion from binary to decimal. (Larger values of α indicate greater levels of noise.)
(a) Show that the conditional distribution for binary to decimal conversion is normalized; namely, that 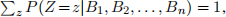 where the sum is over all integers z ∈ [−∞, +∞].
where the sum is over all integers z ∈ [−∞, +∞].
(b) Consider a network with n= 10 bits and noise level α= 0.1. Use the method of likelihood weighting to estimate the probability P(Bi = 1|Z = 128) for i ∈ {2, 5, 8, 10}.
(c) Plot your estimates in part (b) as a function of the number of samples. You should be confident from the plots that your estimates have converged to a good degree of precision (say, at least two significant digits).
(d) Submit a hard-copy printout of your source code. You may program in the language of your choice, and you may use any program at your disposal to plot the results.
3.6 Even more inference
Show how to perform the desired inference in each of the belief networks shown below. Justify briefly each step in your calculations.
(a) Markov blanket
Show how to compute the posterior probability P(B|A, C, D) in terms of the CPTs of this belief network—namely, P(A), P(B|A), P(C), and P(D|B, C).
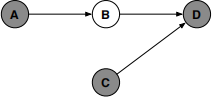
(b) Conditional independence
This belief network has conditional probability tables for P(F|A) and P(E|C) in addition to those of the previous problem. Assuming that all these tables are given, show how to compute the posterior probability P(B|A, C, D, E, F) in terms of these additional CPTs and your answer to part (a).
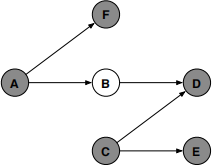
(c) More conditional independence
Assuming that all the conditional probability tables in this belief network are given, show how to compute the posterior probability P(B, E, F|A, C, D). Express your answer in terms of the CPTs of the network, as well as your earlier answers for parts (a) and (b).

3.7 More likelihood weighting
(a) Single node of evidence

Suppose that T samples 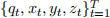 are drawn from the CPTs of the belief network shown above (with fixed evidence E = e). Show how to estimate P(Q=q|E =e) from these samples using the method of likelihood weighting. Express your answer in terms of sums over indicator functions, such as:
are drawn from the CPTs of the belief network shown above (with fixed evidence E = e). Show how to estimate P(Q=q|E =e) from these samples using the method of likelihood weighting. Express your answer in terms of sums over indicator functions, such as:
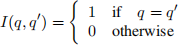
In addition, all probabilities in your answer should be expressed in terms of CPTs of the belief net-work (i.e., probabilities that do not require any additional computation).
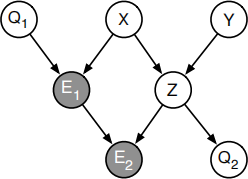
(b) Multiple nodes of evidence
Suppose that T samples 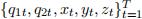 are drawn from the CPTs of the network shown below (with fixed evidence E1 =e1 and E2 =e2). Show how to estimate
are drawn from the CPTs of the network shown below (with fixed evidence E1 =e1 and E2 =e2). Show how to estimate
P(Q1 =q1, Q2 =q2|E1 =e1, E2 =e2)
from these samples using the method of likelihood weighting. Express your answer in terms of indi-cator functions and CPTs of the belief network.
2023-12-28