Project 4 Parallel Programming with Machine Learning
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
Project 4
Parallel Programming with Machine Learning
Prologue
In this project, you will have the opportunity to gain insight and practice in using OpenACC to accelerate machine learning algorithms. Specifically, you will be accelerating softmax regression and neural networks (NNs).
First, you will need to understand the basic principles and algorithms of softmax regression and neural networks. Then, you will work with OpenACC, a programming model for parallel computing that makes it easier for you to optimize your code to run on GPUs, thereby greatly increasing the speed of computation.
This assignment will help you understand the importance of parallel computing in machine learning, especially when working with large-scale data and complex models. You will learn how to effectively utilize hardware resources to improve the performance and efficiency of machine learning algorithms.
REMIND: Please start ASAP to avoid the peak period of cluster job submission.
Task0: Setup
Download the dataset from BB. Unzip dataset.zip to folder project4 .
The structure of working directory should look like below:
Task1: Train MNIST with softmax regression
Softmax regression (or multinomial logistic regression) is an extension of logistic regression that can handle multiclass classification problems. Softmax Regression, also known as Multinomial Logistic Regression, is an extension of Logistic Regression to the multi-class problem. The mathematical expression is as follows:
Suppose we have an input vector x ∈ Rn, and we want to classify it into one of K different classes.
For each class j, we have a weight vector wj ∈ Rn and a bias term bj.
We can compute the unnormalized log probabilities oj for x belonging to class j as follows:
zj = xT θj + bj
This gives us an output vector θ ∈ RK, where each element oj represents the unnormalized log probability of x belonging to class j.
We can then convert these unnormalized log probabilities into probabilities using the softmax function. The softmax function is defined as follows:
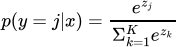
This gives us a probability vector p ∈ RK, where each element pj represents the
probability of x belonging to class j. This is the mathematical expression of softmax regression. It maps an input vector x to a probability vector p, where each element pj represents the probability of x belonging to class j.
This process is also known as softmax classification. In practice, we usually choose the class with the highest probability as the predicted class.
For a multi-class output that can take on values y ∈ {1, … , k}, the softmax loss takes as input a vector of logits z ∈ Rk, the true classy ∈ {1, … , k} returns a loss defined by:

Softmax gradient descent optimization algorithm : we need to compute the
gradients of the loss function with respect to the weights and biases, and then update the weights and biases. We can also write this in the more compact notation we
discussed in class. Namely, if we let X ∈ Rm×n denote a design matrix of some m
inputs (either the entire dataset or a minibatch), y ∈ {1, … , k}m a corresponding vector
of labels, and overloading ℓsoftmax to refer to the average softmax loss, then
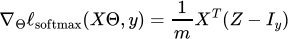
where
Z = normalize(exp(XΘ)) (normalization applied row-wise)
denotes the matrix of logits, and Iy ∈ Rm×k represents a concatenation of one-hot bases for the labels in y.
Here is the given training code in Python:
Note that for "real" implementation of softmax loss you would want to scale the logits to prevent numerical overflow, but we won't worry about that here (the rest of the
assignment will work fine even if you don't worry about this).
There are some functions inside the softmax function that you also need to fill in the details:
Function Declaration What does the function do
matrix_dot(A, B, C, m, n, k) perform a matrix multiplication operation between matrices A and B, and the result is stored in matrix C
matrix_softmax_normalize(A, m, n) apply the softmax activation function to the matrix A
vector_to_one_hot_matrix(y, Y, m, n) convert a vector y into a one-hot encoded matrix Y with dimensions m × n
matrix_minus(A, B, m, n) perform element-wise subtraction between matrices A and B, with the result stored in matrix A
matrix_dot_trans(A, B, C, n, m, k) perform a matrix multiplication between the transpose of A and B, with the result stored in matrix C
matrix_div_scalar(A, scalar, m, n) divides all elements of matrix A by the scalar value scalar
matrix_mul_scalar(A, scalar, m, n) multiply all elements of matrix A by the scalar value scalar
matrix_minus(A, B, m, n) subtracts matrix A from matrix B element-wise, , with the result stored in matrix A
softmax_regression_epoch_cpp(X, y, theta, m, n, k, lr, batch) train theta of softmax regression for 1 epoch
train_softmax(train_data, test_data, num_classes, epochs, lr, batch) train a softmax classifier
In the implementation, you are allowed to define your variables and functions to facilitate your programming.
The outcome is like below:
Task2: Accelerate softmax with OpenACC
You need to accelerate the train_softmax function and the functions inside the softmax_regression_epoch_cpp function with OpenACC.
Hint: You can accelerate the program by applying OpenACC to each function.
Task3: Train MNIST with neural network
The inference and training process of a neural network can be described by the following formulas:
1. Forward Propagation (Inference)
The forward propagation process of a neural network can be described by the following formula, where a(l) is the activation value of the l th layer W (l) is the weight of the l th layer, b(l) is the bias of the l th layer, and f is the activation function:
a(l) = f(W(l)a(l−1) + b(l))
This process starts from the input layer, through the calculation of each layer’s weights and biases, as well as the activation function, and finally obtains the predicted value of the output layer.
2. Backward Propagation (Training)
The training process of a neural network mainly updates the weights and biases through the backpropagation algorithm. First, we need to define a loss function L to measure the gap between the predicted value and the true value. Then, we
update the weights and biases by calculating the gradient of the loss function for the weights and biases:

Here, ∂ ∂ a L

Here, α is the learning rate, which controls the step size of the update.
In this project, we are going to implement a 2-layer NN with SGD.
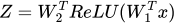
where W1 ∈ Rn×d and W2 ∈ Rd×k represent the weights of the network (which has a d- dimensional hidden unit), and where z ∈ Rk represents the logits output by the
network. We again use the softmax / cross-entropy loss, meaning that we want to solve the optimization problem.
Using the chain rule, we can derive the backpropagation updates for this network (we'll briefly cover these in class, on 9/8, but also provide the final form here for ease of implementation). Specifically, let
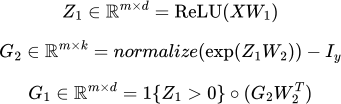
where 1{Z1 > 0} is a binary matrix with entries equal to zero or one depending on whether each term in Z1 is strictly positive and where ∘ denotes elementwise multiplication. Then the gradients of the objective are given by:
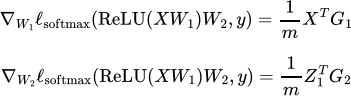
Here is the given training code in Python:
There are some new functions inside the NN function that you also need to fill in the details:
|
Function Declaration |
What does the function do |
|
matrix_trans_dot(A, B, C, m, n, k)
|
perform a matrix multiplication between A and the transpose of B, with the result stored in matrix C |
|
matrix_mul(A, B, size) |
multiply matrix A from matrix B element- wise, with the result stored in matrix A |
|
nn_epoch_cpp(X, y, W1, W2, m, n, l, k, lr, batch) |
train the 2-layer NN for 1 epoch |
|
train_nn(train_data, test_data, num_classes, hidden_dim, epochs, lr, batch) |
train a 2-layer NN classifier |
The outcome is like below:
Task4: Accelerate neural network with OpenACC
You need to accelerate the train_nn function and the functions inside the nn_epoch_cpp function with OpenACC.
Since the calculating precisions on CPU and GPU platforms are different, there is a tiny gap between the outcome of sequential and OpenACC programs. Here is the sample output of OpenACC:
Hint: You can accelerate the program by applying OpenACC to each function.
Extra Credit: Extend Neural Network to
Convolutional Neural Network with OpenACC
You need to implement and accelerate the train_cnn function and the functions inside the cnn_epoch_cpp function with OpenACC. You can use any hyperparameters and
filters as you like. Note that your performance of CNN should be better in accuracy than the previous 2-layer NN.
Hint: You can accelerate the program by applying OpenACC to each function. Filters in static when compiling may help a lot in time performance.
How to Execute the Program
Execute the bash script.
Baseline
|
Softmax Sequential |
softmax OpenACC |
NN Sequential |
NN OpenACC |
|
9767 ms |
1066 ms |
683586 ms |
68563 ms |
NOTICE: the outcome of the classifier in training (including loss and error) should be the same as the sample outcome number by number.
Requirements & Grading Policy
![]() Machine Learning (50%)
Machine Learning (50%)
![]() Task1: Train MNIST with softmax regression (10%)
Task1: Train MNIST with softmax regression (10%)
![]() Task2: Accelerate softmax with OpenACC (20%)
Task2: Accelerate softmax with OpenACC (20%)
![]() Task3: Train MNIST with neural network (10%)
Task3: Train MNIST with neural network (10%)
![]() Task4: Accelerate neural network with OpenACC (10%)
Task4: Accelerate neural network with OpenACC (10%)
Your programs should be able to compile & execute to get the expected computation result to get the full grade in this part.
![]() Performance of Your Program (30%)
Performance of Your Program (30%)
![]() 7.5% for each Task
7.5% for each Task
Try your best to do optimization on your parallel programs for higher speedup. If your programs show similar performance to the baseline performance, then you can get the full mark for this part. Points will be deducted if your parallel programs perform poorly while no justification can be found in the report.
![]() One Report in PDF (20%, No Page Limit)
One Report in PDF (20%, No Page Limit)
![]() Regular Report (10%)
Regular Report (10%)
The report does not have to be very long and beautiful to help you get a good grade, but you need to include what you have done and what you have
learned in this project. The following components should be included in the report:
![]() How to compile and execute your program to get the expected output on the cluster.
How to compile and execute your program to get the expected output on the cluster.
![]() Explain clearly how you designed and implemented each algorithm
Explain clearly how you designed and implemented each algorithm
![]() Show the experiment results you get, and do some numerical analysis, such as calculating the speedup and efficiency, demonstrated with tables and figures.
Show the experiment results you get, and do some numerical analysis, such as calculating the speedup and efficiency, demonstrated with tables and figures.
![]() What kinds of optimizations have you tried to speed up your parallel program, and how do they work?
What kinds of optimizations have you tried to speed up your parallel program, and how do they work?
![]() Any interesting discoveries you found during the experiment?
Any interesting discoveries you found during the experiment?
![]() Profiling OpenACC with nsys (10%)
Profiling OpenACC with nsys (10%)
You are required to practice profiling OpenACC programs with nsys as we
explained in the Instruction of profiling tools with perf and nsys. The command line profiling of nsys is mandatory while the GUI Nsight System is optional.
![]() Extra Credits (10%)
Extra Credits (10%)
![]() Implement CNN (5%)
Implement CNN (5%)
![]() Accelerate CNN with OpenACC (5%)
Accelerate CNN with OpenACC (5%)
Extra optimizations or interesting discoveries in the first three tasks may also earn you some extra credits.
The Extra Credit Policy
According to the professor, the extra credits in this project cannot be added to other projects to make them full marks. The credits are the honor you received from the professor and the teaching staff, and the professor may help raise you to a higher grade level if you are at the boundary of two grade levels and he thinks you deserve a better grade with your extra credits. For example, if you are among the top students with B+ grade, and get enough extra credits, the professor may raise you to A- grade. Furthermore, the professor will invite a few students with high extra credits to have dinner with him.
Grading Policy for Late Submission
1. late submission for less than 10 minutes after the DDL is tolerated for possible issues during submission.
2. 10 Points deduction for each day after the DDL (11 minutes late will be considered as one day, so be careful)
3. Zero points if you submitted your project late for more than two days
File Structure to Submit on BlackBoard
<Your StudentID>.pdf # Report
<Your StudentID>.zip # Codes
|
├── |
sbatch.sh |
|
├── |
src |
|
│ |
├── nn_classifier.cpp |
|
│ |
├── nn_classifier_openacc.cpp |
|
│ |
├── simple_ml_ext.cpp |
|
│ |
├── simple_ml_ext.hpp |
|
│ |
├── simple_ml_openacc.cpp |
|
│ |
├── simple_ml_openacc.hpp |
|
│ |
├── softmax_classifier.cpp |
|
│ |
└── softmax_classifier_openacc.cpp |
|
└ |
test.sh |
5 directories, 20 files
2023-12-07