COMP90049, Introduction to Machine Learning
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
COMP90049, Introduction to Machine Learning, Semester 2 2021
Assignment 3: Sentiment Classification of Tweets
1 Overview
In this assignment, you will develop and critically analyse sentiment classification of Tweets. That is, given a tweet, your model(s) will produce a prediction of the sentiment that is present in the tweet. You will be provided with a data set of tweets that have been annotated with the positive, negative, and neutral sentiments. The assessment provides you with an opportunity to reflect on concepts in machine learning in the context of an open-ended research problem, and to strengthen your skills in data analysis and problem solving.
The goal of this assignment is to critically assess the effectiveness of various Machine Learning classifica-tion algorithms on the problem of determining a tweet’s sentiment, and to express the knowledge that you have gained in a technical report. The technical side of this project will involve applying appropriate ma-chine learning algorithms to the data to solve the task. There will be a Kaggle in-class competition where you can compare the performance of your algorithms against your classmates.
The focus of the project will be the report, formatted as a short research paper. In the report, you will demonstrate the knowledge that you have gained, in a manner that is accessible to a reasonably informed reader.
2 Deliverables
Stage I: Model development, testing, and report writing (by October 8 5pm):
1. One or more programs, written in Python, including all the code necessary to reproduce the results in your report (including model implementation, label prediction, and evaluation). You should also include a README file that briefly details your implementation. Your name and student ID should not appear anywhere in the code and the readme file including the metadata (filename, etc.). Submitted through Canvas.
2. An anonymous written report, of 2000 words (±10%) excluding reference list. Your name and student ID should not appear anywhere in the report, including the metadata (filename, etc.). Submitted through Canvas/Turnitin.
3. Sentiment predictions for the test set of tweets submitted to the Kaggle in-class competition described in Sec 6.
Stage II Peer reviews (by October 13th):
1. Reviews of two reports written by your classmates, of 200-400 words each.
3 Data Sets
You are provided with a labelled training set of Tweets, a labelled development set which you can use for model selection and tuning, and an unlabeled test set which will be used for final evaluation in the Kaggle in-class competition. Train, test and development sets are provided for each of the representations explained below. Each row in the data files contains the sentiment, tweet ID, and the tweet representation as comma-separated values.
Class Labels
In the provided data set, each tweet is labelled with one of three possible sentiments (i.e., class labels), where pos, neg, and neu denote positive, negative, and neutral sentiments:

Features
To aid in your initial experiments, we have applied some feature engineering to the raw tweets. You may use any subset of the representations described below in your experiments, and you may also extract your own features from the tweets if you wish. The provided representations are
1. full The raw tweets represented as a single string, e.g.,
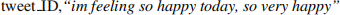
2. count stands for “Bag of Words”. We (1) filtered the words in the data set, removing very frequent and very infrequent words; and (2) mapped each word to a unique ID. The resulting mapping from remaining word strings to their ID is provided in vocab.txt. And (3), we represent each tweet as a list of (ID, word count) tuples. E.g., assuming the following mapping (word:ID): {im:0, feeling:1, so:2, happy:3, today:4, very:5}

3. tfidf Same as “count” except that instead of word counts, we provide the tfidf value as a measure of feature importance. E.g.,
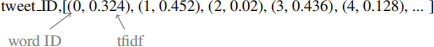
You can learn more about tfidf in Schutze et al. (2008).
4. glove100 We mapped each word to a 100-dimensional Glove “embedding vector”. These vectors were trained to capture the meaning of each word. We then summed the vectors of each word in a tweet to obtain a single 100-dimensional representation of the tweet. E.g.,
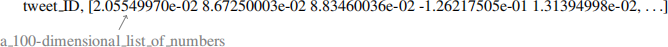
You can refer to Pennington et al. (2014) for more information about GloVe.
4 Tasks
Stage I
1. Feature Engineering (optional)
The process of engineering, or selecting features that are useful for discriminating among your target class set is inherently poorly-defined. Most machine learning assumes that the attributes are simply given, with no indication from where they came. The question as to which features are the best ones to use is ultimately an empirical one: just use the set that allows you to correctly classify the data.
In practice, the researcher uses their knowledge about the problem to select and construct “good” features. What aspects of a tweet itself might indicate a tweet’s sentiment? You can find ideas in published papers, e.g., Go et al. (2009).
We have discussed three types of attributes in this subject: categorical, ordinal, and numerical. All three types can be constructed for the given data. Some machine learning architectures prefer numerical attributes (e.g. k-NN); some work better with categorical attributes (e.g. multivariate Naive Bayes) – you will probably observe this through your experiments.
It is optional for you to engineer some attributes based on the full Tweets dataset (and possibly use them instead of – or along with – the feature representations provided by us). Or, you may simply select features from the ones we generated for you (count, tfidf, and glove100).
2. Machine Learning
Various machine learning techniques have been (and will be) discussed in this subject (Naive Bayes, Logistic Regression, 0-R, etc.); many more exist. You are strongly encouraged to make use of existing libraries in your attempts at this project (such as sklearn or scipy, etc. ).
The objective of your learners will be to predict the classes of unseen data. We will use a holdout strategy: the data collection has been split into three parts: a training set, a development set, and a test set. This data will be available on the LMS.
1. The training phase will involve training your classifier and parameter tuning where required.
2. The development phase is where you observe the performance of the classifier. The development data is labelled: you should run the classifier that you built in the training phase on this data to calculate one or more evaluation metrics to discuss and compare in your report, using tables/diagrams.
3. The testing phase: The test data is unlabeled; you should use your preferred model to produce a pre-diction for each test instance, and submit your predictions to Kaggle website; we will use this output to confirm the observations of your approach.
To give you the possibility of evaluating your models on the test set, we will be setting up a Kaggle In-Class competition. You can submit results on the test set there, and get immediate feedback on your systems performance. There is a Leaderboard, that will allow you to see how well you are doing as compared to other classmates participating on-line.
You should minimally implement and analyse in your report one baseline, and at least two different machine learning models. N.B. We are more interested in your critical analysis of methods and results, than the raw performance of your models.
3. Report
You will submit an anonymised report of 2000 words in length (±10%), excluding reference list. The report should follow the structure of a short research paper, as will be discussed in the guest lecture on Academic Writing. It should describe your approach and observations, both in engineering (optional) features, and the machine learning algorithms you tried. Its main aim is to provide the reader with knowledge about the problem, in particular, critical analysis of your results and discoveries (or maybe some that you havent!). The internal structure of well-known classifiers (discussed in the subject) should be discussed if it is important for connecting the theory to your practical observations.
● Introduction: a short description of the problem and data set
● Literature review: a short summary of some related literature, including the data set reference and at least two additional relevant research papers of your choice. One option is Agarwal et al. (2011), as well as papers cited there.
● Method: Identify the newly engineered feature(s), and the rationale behind including them (Optional). Explain the methods and evaluation metric(s) you have used (and why you have used them)
● Results: Present the results, in terms of evaluation metric(s) and, ideally, illustrative examples
● Discussion / Critical Analysis: which must cover the following aspects with greater focus on contextual-ising:
1. Contextualise∗∗ the systems behavior, based on the understanding from the subject materials (the most important part of the task in this assignment)
2. Discuss any ethical issues you may find with developing a sentiment classifier given the data and evaluation used in this assignment. Your discussion may touch on data selection, user discrimina-tion, or other biases introduced in the pipeline. You may use (Dıaz et al., 2018; Yang and Eisenstein, 2017) for inspiration (and cite it appropriately if you do), or come up with your own ideas.
● Conclusion: Clearly demonstrate your identified knowledge about the problem
● A bibliography, which includes (Vadicamo et al., 2017; Go et al., 2009), as well as references to any other related work you used in your project. You are encouraged to use the APA 7 citation style, but may use different styles as long as you are consistent throughout your report.
∗∗ Contextualise implies that we are more interested in seeing evidence of you having thought about the task and determined reasons for the relative performance of different methods, rather than the raw scores of the different methods you select. This is not to say that you should ignore the relative performance of different runs over the data, but rather that you should think beyond simple numbers to the reasons that underlie them.
We will provide LATEXand RTF style files that we would prefer that you use in writing the report. Reports are to be submitted in the form of a single PDF file. If a report is submitted in any format other than PDF, we reserve the right to return the report with a mark of 0.
Your name and student ID should not appear anywhere in the report, including any metadata (filename, etc.). If we find any such information, we reserve the right to return the report with a mark of 0.
Stage II
During the reviewing process, you will read two anonymous submissions by your classmates. This is to help you contemplate some other ways of approaching the Project, and to ensure that every student receives some extra feedback. You should aim to write 200-400 words total per review, responding to three ’questions’:
● Briefly summarise what the author has done in one paragraph (50-100 words)
● Indicate what you think that the author has done well, and why in one paragraph (100-200 words)
● Indicate what you think could have been improved, and why in one paragraph (50-100 words)
5 Assessment Criteria
The Project will be marked out of 30, and is worth 30% of your overall mark for the subject. The mark break-down will be:
Report Quality: (26/30 marks available)
You will produce a formal report, which is commensurate in style and structure with a (short) research paper. You must express your ideas clearly and concisely, and remain within the word limit (2000 words ±10%) ex-cluding reference list. You will include a short summary of related research. You can consult the marking rubric on the Canvas/Assignment 3 page which indicates in detailed categories what we will be looking for in the report.
Kaggle: (2/30 marks)
For submitting (at least) one set of model predictions to the Kaggle competition.
Reviews: (2/30 marks available)
You will write a review for each of two reports written by other students; you will follow the guidelines stated above.
6 Using Kaggle
The Kaggle in-class competition URL will be announced on LMS shortly. To participate do the following:
● Each student should create a Kaggle account (unless they have one already) using your Student-ID
● You may make up to 8 submissions per day. An example submission file can be found on the Kaggle site.
● Submissions will be evaluated by Kaggle for accuracy, against just 30% of the test data, forming the public leaderboard.
● Prior to competition close, you may select a final submission out of the ones submitted previously by default the submission with highest public leaderboard score is selected by Kaggle.
● After competition close, public 30% test scores will be replaced with the private leaderboard 100% test scores.
7 Assignment Policies
7.1 Terms of Data Use
The data set is derived from the resources published in Vadicamo et al. (2017) and Go et al. (2009):
Go, A., Bhayani, R., & Huang, L. (2009). Twitter sentiment classification using distant supervision. CS224N project report, Stanford, 1(12)
Vadicamo, L., Carrara, F., Cimino, A., Cresci, S., DellOrletta, F., Falchi, F., & Tesconi, M. (2017). Crossmedia learning for image sentiment analysis in the wild. In 2017 IEEE International Confer-ence on Computer Vision Workshops (ICCVW), pages 308-317.
This reference must be cited in the bibliography. We reserve the right mark of any submission lacking this reference with a 0, due to violation of the Terms of Use.
Please note that the dataset is a sample of actual data posted to the World Wide Web. As such, it may contain information that is in poor taste, or that could be construed as offensive. We would ask you, as much as possible, to look beyond this to the task at hand. If you object to these terms, please contact us ([email protected]) as soon as possible.
Changes/Updates to the Project Specifications
We will use Canvas announcements for any large-scale changes (hopefully none!) and Piazza for small clarifi-cations. Any addendums made to the Project specifications via the Canvas will supersede information contained in this version of the specifications.
Late Submission Policy
There will be no extensions granted, and no late submissions allowed to ensure a smooth peer review process. Submission will close at 5pm on October 8th. Note than this means you will also lose the Stage II marks. For students who are demonstrably unable to submit a full solution in time, we offer to reduce the weighting of the mark of this assignment towards the overall course grade (but you will still have to submit your solutions by the deadline).
Academic Misconduct
For most people, collaboration will form a natural part of the undertaking of this project. However, it is still an individual task, and so reuse of ideas or excessive influence in algorithm choice and development will be considered cheating. We highly recommend to (re)take the academic honesty training module in this subject’s Canvas. We will be checking submissions for originality and will invoke the Universitys Academic Misconduct policy where inappropriate levels of collusion or plagiarism are deemed to have taken place.
2021-10-05
Assignment 3: Sentiment Classification of Tweets