ADTs II & Data Structures
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
Chapter 11. ADTs II & Data Structures
A more complex list, (0 (1 2) 3 4 5) would be stored as :
[*|*] - - - >[*|*] - - - - - - - - - - - - - - - - - - >[*|*] - - - >[*|*] - - - >[*|*] - - - > NIL
| | | | |
v v v v v
0 [*|*] - - - >[*|*] - - - > NIL 3 4 5
| |
v v
1 2
The atomic elements (the integers) are stored as ‘leaf’ nodes with both car and cdr pointers set to NULL. The data structure used to store the atom and also car and cdr pointers is known as a cons (short for constructor), due the to process by which we build lists.
So, here, we’re interested in recreating this data structure, allowing the user to build lists (the cons operation), extract the head and remainder of lists (the car and cdr operations) and other associated functions such as copying a list or counting the number of elements in it.
Exercise 11.4.1 Use a dynamic/linkedlist style approach to implement a car/cdr ADT. Write the source files Linked/specific.h and Linked/linked.c, so that they compile against my lisp.h and testlisp.c files and run successfully using my Makefile.The basic operations are :
lisp* lisp_atom(const atomtype a);
lisp* lisp_cons(const lisp* l1, const lisp* l2);
lisp* lisp_car(const lisp* l);
lisp* lisp_cdr(const lisp* l);
atomtype lisp_getval(const lisp* l);
bool lisp_isatomic(const lisp* l);
lisp* lisp_copy(const lisp* l);
int lisp_length(const lisp* l);
void lisp_tostring(const lisp* l, char* str);
void lisp_free(lisp** l);
This is worth 90% of the marks. Additional functions you can implement, worth 10%, are :
lisp* lisp_fromstring(const char* str);
lisp* lisp_list(const int n, ...);
void lisp_reduce(void (*func)(lisp* l, atomtype* n), lisp* l, atomtype* acc);
and are Exensions worth 10% of the marks.
Even if you don’t get these extensions (or other functions) to work correctly, make sure the code still compiles by writing ‘dummy’ functions as placeholders, even if some of the assertions fail. ■
11.5 Binary Sparse Arrays
Using dynamic arrays is often a compromise between resizing the array too frequently (e.g. every time the memory required is fractionally too small) or else creating a great deal of ‘spare’ memory, just in case it is needed later. It is common for such dynamic arrays to double the available memory every time an index is accessed out-of-bounds.
Here we create the Binary Sparse Array (BSA) which aims to be memory efficient for small arrays, releasing new memory at an exponential rate as the array grows. Using a BSA ensures that no data is ever copied (e.g. via remalloc) nor too much unused memory created early. The price we pay for this memory efficient is a slightly more complex calculation for the address of the index required.
Another data structure, the Hashed Array Tree (HAT) has similar goals, but is very different in practice and requires copying of data and resizing.
www https://en.wikipedia.org/wiki/Hashed_array_tree
Here, the BSA structure consists of a (fixed-size) row pointer table, each cell of which enables access to a 1D row of data. These rows are of a known size, each of which is increasingly large as we go down the table, as shown in Figure 11.1
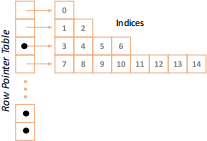
Figure 11.1: The Binary Sparse Array. A (vertical fixed-size) table allows access to each row. The rows are size 1 for the first, size 2 for the second, size 4 for third i.e. for row k it’s size is 2k .
However, the space allocation for each row is only done as-and-when required. After creating an empty BSA, and inserting values into index two and 12, then only rows one and three will have been allocated, as shown in Figure 11.2.
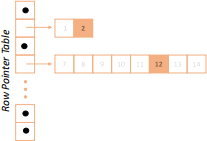
Figure 11.2: A Binary Sparse Array, showing values inserted into index 2 and 12 (shaded cells). Other rows are currently unallocated.
If the only element in a row is deleted, then the entire row is freed up, as shown in Figure 11.3 where the last element in row three is removed (index 12).

Figure 11.3: Deletion in a BSA can result in entire rows being freed up.
Exercise 11.5.1 Write an ADT to implement the bsa.h interface given. Write the source files Alloc/specific.h and Alloc/alloc.c such that the driver files driver.c,isfactorial.c, sieve.c and fibmemo.c work correctly. Ensure that this all works with my Makefile which must be used unaltered. The basic operations are :
bsa* bsa_init(void);
bool bsa_set(bsa* b, int indx, int d);
int* bsa_get(bsa* b, int indx);
bool bsa_delete(bsa* b, int indx);
int bsa_maxindex(bsa* b);
bool bsa_free(bsa* b);
The function bsa_set() allows an integer to be written to a particular index. If it is the first integer to be written into the row, then the space for this will need to be allocated. bsa_get() returns a pointer to the integer stored in an index if it has been set, and NULL if it is a cell that is not in use, hasn’t been written to, deleted, or past the end the maximum index used.
The functions bsa_delete() ‘removes’ an integer from an index (maybe setting a Boolean flag to show if it’s in use or not), and if it was the only cell being used on that row, the entire row is freed.
Additional functionality includes :
bool bsa_tostring(bsa* b, char* str);
void bsa_foreach(void (*func)(int* p, int* n), bsa* b, int* acc);
bsa_tostring() allows a character based version of the BSA to be produced with each row inside {} brackets. The function bsa_foreach allows a user-defined function to be passed which is performed on each element in turn.
• The row pointer table is of a fixed size, and never gets deleted until the final call to bsa_free().
• You will never use realloc for the BSA - rows are created as required using e.g. calloc() of a fixed size, and freed as required.
• Do not use the maths library in this assignment (my Makefile doesn’t) - use bit manipu-lation if required rather than e.g. log2().
• Even if you don’t get all the functions to work correctly, make sure the code still compiles by writing ‘dummy’ functions as placeholders, even if some of the assertions fail.
This is worth 90% of the marks.
The manner in which you’ve been asked to implement the functionality above is very specific. However, exactly the same functionality (getting/setting etc.) could be implemented in very different ways (linked lists, 1D dynamic arrays, trees, hashing etc.). As an extension, write a ‘rival’ version to implement the core functionality of these functions without it necessarily being a BSA. This should still ensure that fibmemo, sieve and isfactorial can be compiled against it. This means you can ignore bsa_tostring() since this gives something very specific to the ‘shape’ of the BSA data structure. Again, use an unchanged version of my Makefile to achieve this. These files will be Extension/specific.h and Extension/extension.c.
If you do this, submit extension.txt which details what you have done, the motivation for it, and how well it works in practice (or not), and comparing it with the original BSA. This discussion (a few hundred words at most) is as (if not more) important than the code itself. This worth 10% of the marks. ■
2023-12-02