4PAHPRM1 RM1 Assignment 03 2023
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
RM1 Assignment 03 2023
Submission Deadline: Submit before 10.30am Monday 4th December 2023
Question C1 [18 marks available]
Use the data file named C1 Memory Span xxxxxxxx.sav (where xxxxxxxx is your Student ID number) for this question.
A cognitive psychologist conducted a study of working memory capacity. The design and procedure for this study was identical to the Memory Span lab in CogLab with two exceptions:
(1) There were two types of stimulus: letters and digits. (There were three types of stimulus in the CogLab Memory Span lab.)
(2) For each type of stimulus, the procedure for determining a span score was run four times for each participant. For each participant, the span score recorded for each stimulus type is the average (mean) of these four ‘runs’ of the procedure.
Each participant therefore has two span scores recorded, one for letter stimuli, and one for digit stimuli.
The psychologist is interested in whether the mean span score differs between the two types of stimulus.
Your data for this study are in the SPSS data file named:
C1 Memory Span xxxxxxx.sav (where xxxxxxx is your student ID number)
Data for two variables are recorded in the data file, and have been entered in keeping with the design of the study:
Letter.span Span score (letters)
Digit.span Span score (digits)
Question C1 (continued)
[6 marks are available for parts (a) & (b) together, 1 mark is deducted for each incorrect answer]
(a) Use SPSS to obtain a 95% confidence interval for the mean span score for letter stimuli. Record the following (give each answer to 2 decimal places):
(1) The lower bound (limit) of this interval
(2) The upper bound (limit) of this interval
(b) Obtain descriptive statistics and use a t-test to examine whether the mean span score differs between the two types of stimulus
(3) The mean span score for letter stimuli (to 2 decimal places)
(4) The mean span score for digit stimuli (to 2 decimal places)
(5) The variance of the span scores for letter stimuli (to 3 decimal places)
(6) The variance of the span scores for digit stimuli (to 3 decimal places)
(7) The t-value (to 2 decimal places)
(8) The (number of) degrees of freedom
(9) The exact p-value (to 3 decimal places)
(10) Is the test statistically significant? (Yes or No)
(c) In a single sentence, provide a description of what information is conveyed by the confidence interval that you obtained in part (a). Your description should be specific to the variable that was analysed. [3 marks]
(d) In a single sentence, provide a conclusion for the t-test that you conducted in part (b). Your conclusion should be specific to the mean difference that was analysed. (You should not repeat statistics from the above table when giving your conclusion.) [3 marks]
(e) For the t-test you performed in part (b) above, write down (in words rather than symbols) the null hypothesis and a suitable (non-directional) alternate hypothesis. Your two hypotheses should be written in a way that is specific to the data of this study (i.e., include appropriate names of variables, scores, or conditions). [6 marks]
Question C2 [18 marks available]
Use the data file named C2 Vocabulary xxxxxxxx.sav (where xxxxxxxx is your Student ID number) for this question.
A researcher conducted an experiment to test claims that a newly developed smart-phone app is superior to ‘traditional’ pencil-and-paper methods as an aid to foreign language vocabulary learning. All participants in the study were learning French in their spare time; none were native speakers of the French language. Each participant was randomly assigned to one of two conditions (with equal numbers in each condition). Participants in phone-app condition were asked to download the new app onto their phone, and were set the target of using the app for 15 minutes per day for one week. Participants in the workbook condition were given a booklet to work through, and were set the target of using the booklet for 15 minutes per day for one week. Performance in a standardised test of French-language vocabulary was measured a two time points: (1) before each participant was given their learning resource (the app or the workbook), and (2) after each participant had used their learning resource for one week. Higher scores on this test represent better performance in the test. A change score was calculated for each participant, by subtracting their ‘before’ score from their ‘after’ score on the test. These change scores can be positive scores, or negative scores – depending upon whether the participant’s score increased, or decreased, from the first test to the second test.
These change scores are to be analysed, and compared between conditions, in order to examine the claim being tested (that the phone-app is superior to the workbook as an aid to vocabulary learning). They have been entered in an appropriate format into an SPSS data file.
Your data for this study are in the SPSS data file named:
C2 Vocabulary xxxxxxx.sav (where xxxxxxx is your student ID number)
The file contains data for two variables:
Resource _condition Type of learning resource used [‘1’ = phone-app; ‘2’ = workbook]
Vocabulary_change Change score for the vocabulary test
Your task is to analyse and report the data, reporting it in the form of a Results section for a psychology research report. Your Results section should include the descriptive statistics that are relevant to the investigation of the mean difference in change scores between the conditions, as well as the results of an appropriate t-test. Marks are awarded for the appropriateness of the content, clarity and structure of your Results section; as well as for the suitable use of reporting conventions in your Results section.
Question C3 [21 marks available]
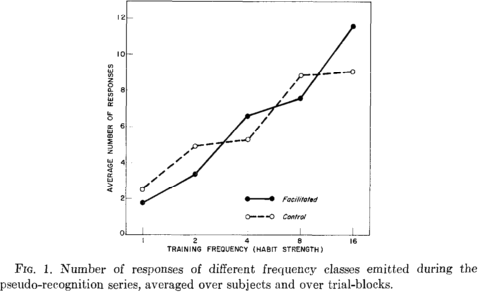
The extract on the final pages of this Worksheet contains a copy of the Method from Zajonc and Sales (1966). The first figure and the first few lines from the Results section are also shown, so that you can see how the data were analysed. Line numbers have been added for reference purposes.
For the purposes of this question (C3), you may regard both the audience condition (control vs. facilitation) and the training frequency (‘habit strength’) as independent variables in the experiment. The dependent variable was the number of responses made on the pseudo-recognition trials of the pseudo-recognition test.
Your task is to read the extract, and to identify three different features of the design that serve to control for (i.e., limit the potential for) confounding variables in this study.
For each feature that you identify:
(A) State what feature you have identified, giving the line number(s) where Zajonc and Sales (1966) mention this feature.
(B) Briefly (but clearly) describe the nature of the confounding that could have occurred if this feature had not been included in the design. (You may use an example of a potential confounding variable as part of this answer.)
(C) Briefly (but clearly) explain how the design feature controls for (or limits the potential for) a confounding variable.
You should aim to identify three different features. That is, the best answers will not simply comment on the same feature three times with three separate examples of how this feature served to control for confounding variables. If your features are too similar to each other, you will not be able to achieve full marks.
Write separate answers for each feature that you identify. For each feature (‘1’, ‘2’ or ‘3’ below, each one described by elements A + B + C above) full marks can be obtained for a clearly written answer that is approximately 100 words in length. For each of these features, the word limit is 200 words. Write in your own words. Use quotations sparingly; and any direct quotations that you do use from the extract should be indicated in this format: “The data in this graph represent the subjects’ responses on the 124 pseudo-recognition trials” (lines 80-81).
(i) Feature 1 (ii) Feature 2 (iii) Feature 3
[C3: 7 marks are available for each feature, making a total 21 marks for Question C3]
Extract from Zajonc and Sales (1966)
METHOD
Subjects
The subjects were 39 male students drawn from the University of Michigan subject pool. Twenty were assigned at random to one condition (Control) and 19 to another (Facilitation): Five subjects in the first condition and four in the second were discarded for failing to learn more than three response words. The subjects’ ages ranged from 18 to 24. Each subject was paid $1.25 for participating in the experiment.
Stimulus Materials
The verbal stimuli were ten of the “Turkish words” (seven-letter nonsense words) used in the recognition studies of Solomon and Postman (1952) and Zajonc and Nieuwenhuyse (1964). Slight changes in some spellings were made to facilitate pronunciation. The ten words were printed in large black letters on white paper and then photographed. These photographs, each 4 × 6 inches, were used in the training session. Black-and-white 2 × 2 inch slides, made from the photographs, were used in the testing session.
Procedure
Training procedure. The ten stimulus words were divided into five training-frequency classes (1, 2, 4, 8, and 16), each including two words. The training frequencies and words were counterbalanced so that each word was used in every frequency class equally often. Each counterbalanced order was given to six subjects, three in each condition.
Subjects were run individually. Upon entering the laboratory the experimenter instructed the subject that the experiment consisted of two parts, the first being concerned with learning to pronounce foreign words. Without saying anything about the second part, the experimenter proceeded with the training. For each subject a random order of stimulus presentation was previously arranged. The entire training session consisted of 62 presentations (two verbal stimuli in each of the five frequency classes). On each presentation the experimenter would show the stimulus, pronounce it aloud, and then have the subject repeat it once. The subject’s response was neither reinforced nor corrected. An interval of approximately four seconds separated the presentations.
Pseudo-recognition test. After the completion of training the experimenter told the subject that the second half of the experiment dealt with subliminal perception. The subject was told that the foreign words he had just learned to pronounce would be flashed upon a small screen and that the speeds and illumination at which they would be flashed would on most trials make their recognition impossible. The subject’s task, however, would be to say what word was shown on each presentation, even when there was very little to see. In these cases the subject, was told he would simply have to guess.
For the pseudo-recognition test, the subject was left alone in his cubicle. Adjacent to this cubicle was the experimenter’s projection room, equipped with a shutter-projector and an intercom system to the subject‘s cubicle. Stimulus slides were flashed through a one-way mirror between the cubicles. The lights in the subject’s cubicle were out, although some light from the experimenter’s projection room provided dim illumination for the subject. Subjects were given to understand that the experimenter could not see them during the pseudo-recognition session.
The stimulus slides were presented in four blocks of 41 presentations each. Within each block ten randomly interspersed presentations involved showing one each of the ten verbal stimuli used in training. They were flashed at 1/10 second, with a medium diaphragm opening. The speed and diaphragm setting were selected prior to the experiment proper so that they would result in about 90% correct recognition. The remaining 31 presentations were made at 1/100 second and with an extremely small diaphragm opening. At these settings recognition, as determined in pretests, was a matter of chance. Shown on each of these 31 presentations was a slide of the same size and with a similar configuration as the ten verbal stimulus slides. However, irregular black lines were drawn on these slides in the place of letters. Five different pseudo-stimulus slides were used for this purpose, alternating randomly among the 31 pseudo-recognition presentations. There was a 10-second interval between trials. Trial blocks were also separated by a 10-second interval.
No feedback except as noted below on either the ten real slides or on the 31 pseudo-stimulus slides was given, nor was there any form of reinforcement.
Responses were recorded by the experimenter as they were made by the subject. In cases when the response was not identical or quite close to any of the ten stimulus words, the response was transcribed phonetically and a decision was made after the session concerning which word was meant by the subject. In general, errors in pronunciations were made on the second or third syllables. The ambiguous responses were therefore classified as one or the other stimulus words according to the first syllable. On three occasions a subject’s response bore no resemblance whatever to any stimulus word. In these cases the subject was told that this was not one of the foreign words he learned, and was asked to make another guess. This was the only form of feedback ever provided.
Experimental conditions. After training and after the experimenter issued instructions for the pseudo-recognition trials, subjects in the Control condition were given a copy of Time to read aloud (ostensibly, to adjust the intercom system). This interpolated activity was intended to prevent the subjects from rehearsing the nonsense words, and it took approximately 1 minute. The entire pseudo-recognition session was conducted with the subject alone in his cubicle and obviously out of the experimenter’s sight.
After having received instructions for the pseudo-recognition series, subjects in the Facilitated condition were told that two students of the experimenter had asked if they could watch the experiment and that they would be with the subject during the remainder of the session. The “students” – always strangers to the subject –were then introduced by the experimenter to the subject’s cubicle and were seated a few feet away. The students did not talk with each other or with the subject. They merely watched the subject, without, however, reacting differentially to his responses. The subjects in the Facilitated condition also were asked to read from Time for 1 minute to inhibit rehearsal.
RESULTS
The overall effect of audience on responses of different strengths is shown in Fig. 1. The data in this graph represent the subjects’ responses on the 124 pseudo-recognition trials (four blocks of 31 trials each). …
2023-12-02