RBE306TC Computer Vision Systems
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
RBE306TC Computer Vision Systems
Assignment
Before you dive into this Exercise 1 to Exercise 3, please check the following OpenCV functions in Python Coding Platform for example:
imread, shape, imshow, imwrite, imnoise, resize, calcHist, equalizeHist, etc.
Some other Python built-in functions, or functions in Scipy package may also be used. Please refer to online resources.
Hint: read the descriptions about each of the previous functions and any other function you might use. You may find descriptive sections of Algorithms(s) in some of the Python functions.
Exercise 1 (20%)
In this task, we use the monochrome image Lenna (i.e., lenna512.bmp) with the following tasks. Let’s regard this reference image Lenna as IM.
• (a). Add Gaussian white noise with 0 mean and variance 10 to the image IM and display the noisy image. We name it as IM_WN. Please write one function to generate this image instead of calling Matlab function directly (4%).
• (b). Add salt & pepper noise with noise density 10% to the image IM and display the noisy image. We name it as IM_SP. Please write one function to generate this image instead of calling Matlab function directly (4%).
• (c). Display the histograms of all the previous images and compare them with the histogram of the reference image, comments and briefly explain your finding (4%).
• (d). Use the command histeq to enhance the image constrast
(lenna512_low_dynamic_range.bmp) and display the enhanced image (4%).
• (e). Moreover, display the histograms of both original image and enhanced image, and explain your finding in the assignment (4%).
Exercise 2 (25%)
Recall salt & pepper images generated in Task 1 IM_SP based on the IM.
• (a). Apply the median filter with a 3 × 3 window and a 5 × 5 window on the image IM_SP respectively. Display and evaluate the PSNR of the obtained images. For each window size, comment on how effectively the noise is reduced while sharp edges and features in the image are preserved (8%).
• (b). Use the average filter (mean filter) 3 × 3 to filter the image IM_SP. Compute the PSNR and display the filtered image (8%).
• (c). As you experimented with the mean and median algorithms what different property did you notice? Was the average or median filter better and why (9%)?
Exercise 3 (55%)
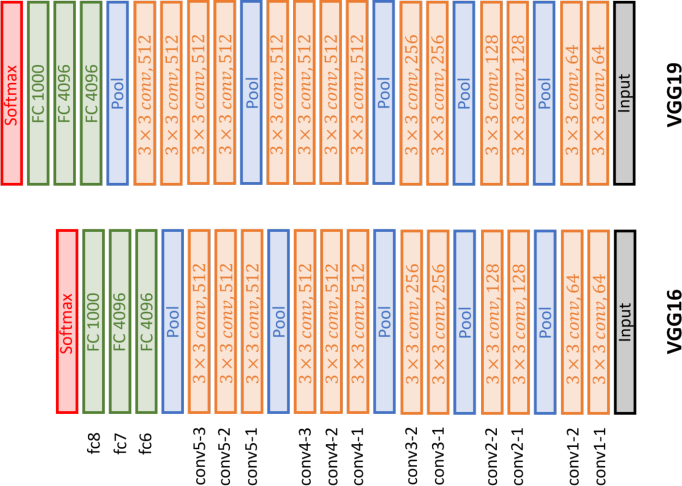
In this exercise, you will be asked to build a VGG-16 and VGG-19 (see the following architecture) to train a classifier on cifar10 dataset. based on the python + PyTorch codes implemented in Lab 4 for LeNet.
*The CIFAR-10 dataset consists of 60000 32x32 colour images in 10 classes, with 6000 images per class. There are 50000 training images and 10000 test images. The dataset is divided into five training batches and one test batch, each with 10000 images. The test batch contains exactly 1000 randomly-selected images from each class. The training batches contain the remaining images in random order, but some training batches may contain more images from one class than another. Between them, the training batches contain exactly 5000 images from each class.

Here are the classes in the dataset, as well as 10 random images from each.
Please be advised that the training of this model should be on the school server with the username and password provided in the Lab 5.
During the training, please take care of the following:
• (a). Choose proper data pre-processing techniques such as crop, resize, normalisation, etc.; Please indicate what pre-processing techniques you have used and demonstrate what difference you have noticed (8%).
• (b). Choose proper data augmentation strategies such as flip, rotation, translation, scale, crop, random contrast, gaussian noise, etc. Please discuss what are those strategies with pictures and demonstrate whether you have seen any difference in both training and testing; If so, what are they? If not, list a few reasons (8%).
• (c). Choose proper optimiser among Stochastic Gradient Descent (SGD), Adaptive Moment Estimation (Adam), etc. See PyTorch official document to find what optimiser options that you may use. Please see what difference with different optimisers and try to explain why (8%).
• (d). Please choose a proper epoch number to avoid overfitting issue. Please plot validation error to demonstrate no overfitting is seen (7%).
• (e). Please complete inference code to perform testing on the whole testing set (8%).
• (f). Please try to compare performance difference in prediction power of both models (VGG-16 and VGG-19); Please also demonstrate what similarities and difference you have found and possible reasons that due to these similarities and differences (8%).
• (g). Please demonstrate whether VGG-16 and VGG-19 are suitable for the given task and specify reasons contributing to your conclusions (8%).
Assignment Submission:
Submit your answers to the exercise above which should contain concise descriptions of your results and observations. Please include listings of the Matlab / Python scripts that you have written. Describe each of the images that you were asked to display.
Answer each question completely:
• Do not attach the code at the end of the assignment. Please only past the useful code under each question;
• The results maybe contain some figures, please add some index and title of each figure;
• Electrical version to LMO with a rar/zip of all files
• Rar file name: RBE306TC-Assignment-FirstnameFAMILYNAME-studentID.rar
• One file with same file name of Rar File: Report (with studentID, name, Lab title on the homepage)
• One folder: codes and other materials. (Examiners are able to run your codes directly)
Marking Scheme:
• 80%-100% Essentially complete and correct work including proper pieces of functional codes, necessary of illustrations, and clear demonstrations.
• 60%-79% Shows understanding, but contains a small number of errors or gaps.
• 40%-59% Clear evidence of a serious attempt at the work, showing some understanding, but with important gaps.
• 20%-39% Scrappy work, bare evidence of understanding or significant work omitted.
• <20% No understanding or little real attempt made.
2023-11-30