STP80110: Advanced Linear Models 1 Semester 1 Assessment
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
Faculty of Engineering, Mathematics and Science
School of Computer Science & Statistics
Statistics
Semester 1 Assessment
STP80110: Advanced Linear Models 1
Exercise 1
In the simple linear regression model, show that the coefficient of determination R2 can be expressed by the formula

where

with 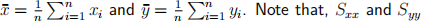 are similarly defined, see Session 1. [10 marks]
are similarly defined, see Session 1. [10 marks]
Exercise 2
In the file nyc. csv, we can find information about restaurants on Fifth Avenue in New York, including ratings and prices.
Specifically, the file lists the values of the following variables: Y = Price, X1 = Food, X2 = Decor, X3 = Service and X4 = East. The variables X1 , X2 , X3 represent customer rating between 0 and 30. The variable X4 is a binary variable taking the value 1 when the restaurant is located at the East side of the Avenue and 0 when it is not.
Question A Using R, find the least squares line of best fit for the regression of the variable Y =Price on X1 =Food. [3 marks]
Question B Using R, present the above line in the scatter plot of the data for the variables (X1 , Y) and comment on the fit graphically and by using R2 . [3 marks]
Question C Using R, fit the multiple linear regression model, using as predictors all the variables Xj , j = 1, . . . , 4 and comment extensively on the obtained equation. [6 marks]
Question D Using R, compare the multiple linear regression model you obtained with the simple linear regression model in (A) using the appropriate measure(s). [3 marks]
Exercise 3
The dataset “hate crimes.csv” contain information on a number of variables that may be linked to hate crimes recorded in 2016 in the USA. These variables are the following:
❼ state: USA State name;
❼ median household income: Median household income, as of 2016;

❼ share unemployed seasonal: Share of the population that is unemployed
 (seasonally adjusted), as of Sept. 2016;
(seasonally adjusted), as of Sept. 2016;
❼ share population in metro
 areas: Share of the population that lives in metropolitan areas, as of 2015;
areas: Share of the population that lives in metropolitan areas, as of 2015;
❼ share population with high school degree: Share of adults 25 and



 older with a high-school degree, as of 2009;
older with a high-school degree, as of 2009;
❼ share non citizen: Share of the population that are not U.S
 . citizens, as of 2015;
. citizens, as of 2015;
❼ share white poverty: Share of white residents who are living in poverty,
 as of 2015;
as of 2015;
❼ gini index: Gini Index values, as 2015;
❼ share non white: Share of the population that is not white, as of 2015;

❼ share voters voted trump: Share of 2016 U.S. presidential voters who

 voted for Donald Trump;
voted for Donald Trump;
❼ hate crimes per 100k

 splc: Hate crimes per 100,000 people (Southern Poverty Law Center), as of 2016;
splc: Hate crimes per 100,000 people (Southern Poverty Law Center), as of 2016;
❼ avg hatecrimes per 100k fbi: Average annual hate crimes per 100,000


 people in the period 2010-2015 (FBI).
people in the period 2010-2015 (FBI).
The data can be imported in R by running: read. csv("hate crimes. csv") .
.
Consider 3 linear regression models for the response variable hate crimes per 100k splc:



❼ Model 1: include all other variables (excluding state) as explanatory variables;
❼ Model 2: include the first 3 principal components computed on the remaining variables (excluding state) as explanatory variables;
❼ Model 3: include the first 5 principal components computed on the remaining variables (excluding state) as explanatory variables;
data h <- read. csv("hate crimes. csv")

# are there missing values?
row. nas <- colSums( apply(data h, 1, is. na) )
data h2 <- data h[-which(row. nas>0), ]
 # remove rows with missing values
# remove rows with missing values
data h3 <- data h2[,-1] #
 remove the variable state # model 1
remove the variable state # model 1
mod1 <- lm( hate crimes per 100k

 splc ~ ., data = data h3)
splc ~ ., data = data h3) # computing principal components
# computing principal components
pca2 <- prcomp(data h3[, -10] ) # compute the PCs
compute the PCs
pcs2 <- pca2$x # extracting the principal components # model 2
mod2 <- lm( data h3$hate crimes per 100k splc



 ~ pcs2[,1:3]) # model 3
~ pcs2[,1:3]) # model 3
mod3 <- lm( data h3$hate crimes per 100k splc



 ~ pcs2[,1:5]) # let’s have a look at the outputs
~ pcs2[,1:5]) # let’s have a look at the outputs
summary(mod1)
summary(mod2)
summary(mod3)
1. Briefly comment on the outputs from the 3 models and compare them in terms of goodness of fit. [5 marks]
2. Would you be satisfied with choosing one of the above models or would you explore other options? Explain. [6 marks]
Exercise 4
1. Consider Model 3 from Exercise 1. Perform an hypothesis test to test if the slope coefficient associated to the second principal component is different from 0. Report all calculations. Compare your results with the information from the output of Model 3 available in R. [7 marks]
2. Consider Model 3 from Exercise 1. What are the expectations on the VIF values associated to the explanatory variables here? Without analytically computing them, report what you think the VIF values are going to be and explain the reasoning behind it. [7 marks]
Exercise 5 An exponential distribution, with rate parameter θ, has probability distribution function

Question A Express f(y;θ) in exponential family form, such that
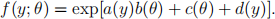
Clearly identify the functions a,b,c and d.
Question B Is the exponential family form canonical in this case? Explain your answer. [2 marks]
Question C Using the properties of exponential families (or otherwise), show that 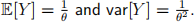 [3 marks]
[3 marks]
Question D For each data point y, we also observe an associated covariate x. It is proposed to model this relationship using a negative inverse link function 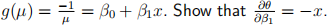 [2 marks]
[2 marks]
Exercise 6 Size measurements for adult foraging penguins observed on islands in the Palmer Archipelago near Palmer Station, Antarctica were collected. Data recording bill length (mm), bill depth (mm), flipper length (mm), and body mass (g) for n = 333 penguins were analysed. The sex of each penguin was also collected, with a value of 1 denoting a male penguin, and a value of 0 denoting a female. Your goal is to predict a penguin’s sex using the variables in the data. The dataset is ‘penguin.csv’. You will need to use this data to answer the questions below.
Question A Perform an initial assessment of the data and write a brief summary (100-200 words). You may include one figure to accompany this assessment. You should refer to this figure in your summary. [2 marks]
Question B Fit simple logistic regression model to the data using the body mass variable only. Summarise and interpret the key outputs of this analysis (200-300 words). Is body mass useful in predicting the sex of a penguin? You may include up to two figures to accompany your summary, which you should refer to explicitly. [5 marks]
Question C A colleague fits two models to the data. Model A uses body mass only. Model B uses bill length only. They report the estimated regression coefficients for each model as being β body mass= 0.0012 and β bill length= 0.14 respectively. Based on these estimates, your colleague concludes that bill length is a more useful predictor than body mass, on the basis that the latter estimate is larger.
1. Do you agree with the colleague? Explain your reasoning. [2 marks]
2. Briefly describe a method you would use to assess the relative importance of each variable. (Calculations not necessary). [2 marks]
Question D Describe two further regression approaches that you would consider taking for this data. Discuss the key considerations involved in each approach and why you think it would be useful in this case. [5 marks]
Exercise 7
Consider the following output of the“glm” function in R:
Model 1

Answer the following questions and include explanations and derivations.
Question A. What is the value of the log-likelihood for the fitted model? [4 marks]
Question B. How many parameters does the model above have? [4 marks]
In order to improve the fit, we consider the following model:
Model 2

Question D. What is the difference between Model 1 and Model 2? Is Model 2 better than Model 1? Justify your answer! [4 marks]
Exercise 8
Consider the following output of the“glm” function in R:

Answer the following questions and include explanations and derivations.
Question A. How many observations (that is number of rows) does the data frame ”datatrain1” have? [2 marks]
Question B. What is the value of the log-likelihood for the fitted model? [4 marks]
Question C. What is the meaning of “null-deviance”? [3 marks]
Question D. What is the p-value of the anova deviance-based hypothesis test that compares the null model and the current model? How is the p-value computed? (report the R code, one line of code) [4 marks]
2023-11-29