CHE1147H - Data Mining in Engineering Programming assignment #5
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
Programming assignment #5
Course: CHE1147H - Data Mining in Engineering
1 Supervised learning
Here, you are going to use the features you generated in Assignment #3 to predict the clients response to a promotion campaign. This is a typical classiication problem in the retail industry, but the formulation of the problem is similar to industries such as fraud detection, marketing and manufacturing.
The clients responses are stored in the Retail_Data_Response.csv ile from Kaggle. The responses are binary: 0 for clients who responded negatively to the promotional campaign and 1 for clients who responded positively to the campaign.
You will explore solving the classiication problem with two diferent sets of features (i.e. annual and monthly) and three diferent algorithms as shown in the image below.
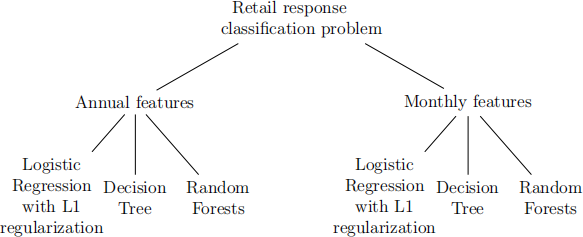
1.1 Import the monthly and annual data and join
In Assignment #3, you createdive diferent feature families that capture annual and monthly aggregations. Here, you will model the retail problem with two approaches: using annual and monthly features. Therefore, you need to create the joined tables based on the following logic:
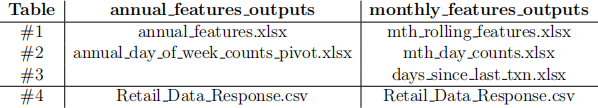
In both the annual and monthly features approach, you need to join at the end with table #4, the clients responses. This is simply a table that contains the binary response of the client to our marketing efort as described above and that is the output or label or target that makes this a supervised learning problem.
1.2 Steps for each method (10 points)
1. Separate the inputs X and the output y in two data frames.
2. Split the data in train and test set. Use a test size value of 2/3 and set the random state equal to 1147 for consistency (i.e. the course code value). Use the following names for consistency.
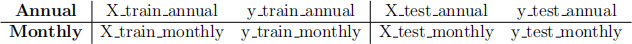
3. Pre-process (if necessary for the method).
4. Fit the training dataset and optimize the hyperparameters of the method.
5. Plot coefficient values or feature importance.
6. Plot probability distribution for test set.
7. Plot confusion matrix and ROC curves of train/test set. Calculate precision/recall.
8. Plot decision boundary for top 2 features.
1.3 Comparison of methods (10 points)
Compare the two feature engineering (annual and monthly) and the three modeling ap- proaches (L1 log-reg, tree, forests) in terms of the outcomes of steps 5-8. Which combina- tion of feature engineering and modeling approach do you select as the best to deploy in a production environment and why? Tabularize your indings in steps 5-8 to summarize the results and support your decision (how to organize information with tables in Markdown).
2023-11-27