COMP3702 Artificial Intelligence
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
COMP3702 Artificial Intelligence (Semester 2, 2021)
Assignment 2: DragonGame MDP
Key information:
● Due: 4pm, Friday 24 September
● This assignment will assess your skills in developing algorithms for solving MDPs.
● Assignment 2 contributes 15% to your final grade.
● This assignment consists of two parts: (1) programming and (2) a report.
● This is an individual assignment.
● Both code and report are to be submitted via Gradescope (https://www.gradescope.com/). You can find instructions on how to register for the COMP3702 Gradescope site on Blackboard.
● Your program (Part 1, 60/100) will be graded using the Gradescope code autograder, using testcases similar to those in the support code provided at https://gitlab.com/3702-2021/a2-support.
● Your report (Part 2, 40/100) should fit the template provided, be in .pdf format and named according to the format a2-COMP3702-[SID].pdf, where SID is your student ID. Reports will be graded by the teaching team.
The DragonGame AI Environment
“Untitled Dragon Game” or simply DragonGame, is a 2.5D Platformer game in which the player must collect all of the gems in each level and reach the exit portal, making use of a jump-and-glide movement mechanic, and avoiding landing on lava tiles. DragonGame is inspired by the “Spyro the Dragon” game series from the original PlayStation. For this assignment, there are some changes to the game environment indicated in pink font. In Assignment 2, actions may have non-deterministic outcomes!
To optimally solve a level, your AI agent must find a policy (mapping from states to actions) which collects all gems and reaches the exit while incurring the minimum possible expected action cost.
Levels in DragonGame are composed of a 2D grid of tiles, where each tile contains a character representing the tile type. An example game level is shown in Figure 1.

Game state representation
Each game state is represented as a character array, representing the tiles and their position on the board. In the visualizer and interactive sessions, the tile descriptions are triples of characters, whereas in the input file these are single characters.
Levels can contain the tile types described in Table 1.
An example of performing the Walk Right action on a Super Charge tile is shown in Table 2:
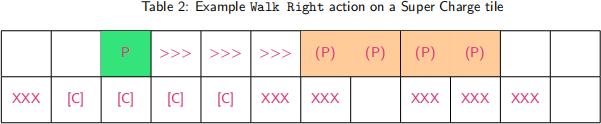
‘P’ represents the current player position, ‘>>>’ represents tiles which are skipped over, and each (P) represents a possible new position of the player.
Actions
At each time step, the player is prompted to select an action. Each action has an associated cost, representing the amount of energy used by performing that action. Each action also has requirements which must be satisfied by the current state in order for the action to be valid. The set of available actions, costs and requirements for each action are shown in Table 3.
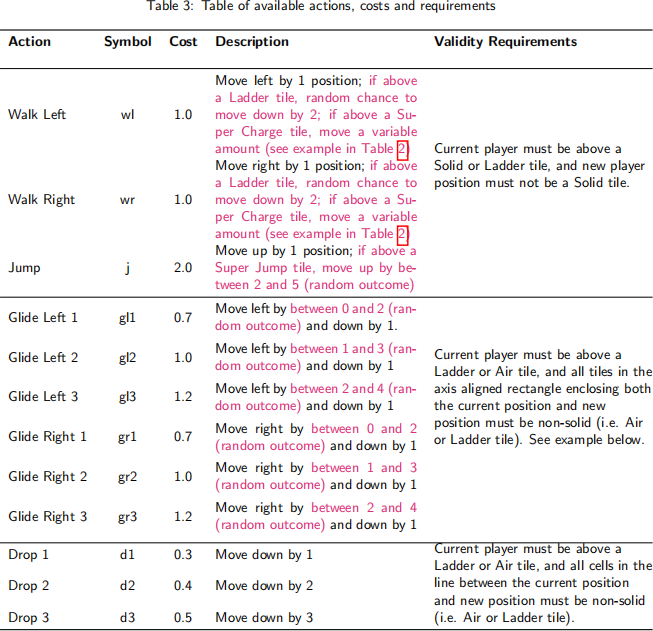
Example of glide action validity requirements for GLIDE_RIGHT_2 (‘gr2’):

Interactive mode
A good way to gain an understanding of the game is to play it. You can play the game to get a feel for how it works by launching an interactive game session from the terminal with the following command:
$ python play_game.py <input_file>.txt
where <input_file>.txt is a valid testcase file (from the support code).
In interactive mode, type the symbol for your chosen action and press enter to perform the action. Type ‘q’ and press enter to quit the game.
DragonGame as an MDP
In this assignment, you will write the components of a program to play DragonGame, with the objective of finding a high-quality solution to the problem using various sequential decision-making algorithms based on the Markov decision process (MDP) framework. This assignment will test your skills in defining a MDP for a practical problem and developing e↵ective algorithms for large MDPs.
What is provided to you
We will provide supporting code in Python only, in the form of:
1. A class representing DragonGame game map and a number of helper functions
2. A parser method to take an input file (testcase) and convert it into a DragonGame map
3. A policy visualiser
4. A simulator script to evaluate the performance of your solution
5. Testcases to test and evaluate your solution
6. A solution file template
The support code can be found at: https://gitlab.com/3702-2021/a2-support. Autograding of code will be done through Gradescope, so that you can test your submission and continue to improve it based on this feedback — you are strongly encouraged to make use of this feedback.
Your assignment task
Your task is to develop algorithms for computing paths (series of actions) for the agent (i.e. the Dragon), and to write a report on your algorithms’ performance. You will be graded on both your submitted program (Part 1, 60%) and the report (Part 2, 40%). These percentages will be scaled to the 15% course weighting for this assessment item.
The provided support code formulates DragonGame as an MDP, and your task is to submit code imple-menting the following MDP algorithms:
1. Value Iteration (VI)
2. Policy Iteration (PI)
3. Monte Carlo Tree Search (MCTS).
Individual testcases will not impose the use of a particular strategy (value iteration/policy iteration/MCTS), but the difficulty of higher level testcases will be designed to require a more advanced solution (e.g. linear algebra policy iteration or MCTS). Each testcase will specify different amounts of time available for use for offline planning and for online planning, so these can be used to encourage your choice of solution e.g. towards choosing offline or online solving for a particular testcase. You can choose which search approach to use in your code at runtime if desired (e.g. by checking the given offline time and online time, and choosing offline planning if offline time  online time, online planning otherwise).
online time, online planning otherwise).
Once you have implemented and tested the algorithms above, you are to complete the questions listed in the section “Part 2 - The Report” and submit the report to Gradescope.
More detail of what is required for the programming and report parts are given below.
Part 1 — The programming task
Your program will be graded using the Gradescope autograder, using testcases similar to those in the support code provided at https://gitlab.com/3702-2021/a2-support.
Interaction with the testcases and autograder
We now provide you with some details explaining how your code will interact with the testcases and the autograder (with special thanks to Nick Collins for his efforts making this work seamlessly).
Implement your solution using the supplied solution.py Template file. You are required to fill in the following method stubs:
● __init__(game env)
● plan_offline()
● select_action()
You can add additional helper methods and classes (either in solution.py or in files you create) if you wish. To ensure your code is handled correctly by the autograder, you should avoid using any try-except blocks in your implementation of the above methods (as this can interfere with our time-out handling). Refer to the documentation in solution.py for more details.
Grading rubric for the programming component (total marks: 60/100)
For marking, we will use 8 di↵erent testcases of ascending level of difficulty to evaluate your solution.
There will be a total of 60 code marks, consisting of:
2021-09-18