Big Data and Machine Learning for Economics and Finance Assignment 3
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
Assignment 3
Big Data and Machine Learning for Economics and Finance
|
Submission Rules: . Provide your answers in a html document generated by RMarkdown. For each answer, provide 。 the R code, 。 the R output, 。 and your comments on the output. Comment each line of your R code as well. Give thorough explanations throughout, and sufficient mathematical descriptions and justifications whenever necessary. Please note that a document not in html and not generated by RMarkdown will not be considered as an acceptable submission and will receive nil marks. . Please note that the function set.seed() may not be used at any time in the assignment. . Please note that, when providing your answers, you may not use any extra packages other than the ones explicitly mentioned in each exercise. For example, if the question says “the only extra packages allowed are ISLR2 and boot”, then you may type library(ISLR2), and library(boot) when writing your answers to the questions in that exercise, but you may not type library(MASS) or library(any other package ) anywhere in your submission. |
This assignment contributes 33% to your final mark and it has 3 exercises in total.
Exercise 1. (20 points) For this exercise, the only extra packages allowed are ISLR2, randomForest and gbm.
1. Using the dataset Carseats from the package ISLR2, we are interested in predicting Sales given all other variables. Select among three possible models: linear regression, random forest and boosted regression trees.
2. Answer the same questions for the dataset Hitters from the package ISLR2 where we are interested in predicting Salary given all other variables.
3. Whether the results for both datasets are the same or different, try to explain that similarity or dissimilarity when it comes to the model selection outcomes.
Exercise 2. (30 points) For this exercise, no extra packages are allowed.
1. Consider the following figure:

Consider a tree with the smallest possible size that can separate the red boxes from the rest. How many terminal nodes will that tree have? Describe one example of such a tree without drawing it.
2. Consider the following dendrogram:
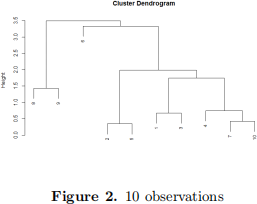
We are interested in clustering the data into four groups. What are the four groups obtained from the dendrogram? Which group contains the closest two points in the sample?
3. Consider the following scatter plot representing the data on two input variables X1 and X2 :
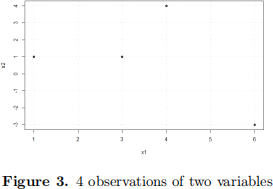
a. If we were to fit a single split tree stump to this dataset, how many possible configurations are there?
b. Going from left to right, the points are labeled (“A” , “A” , “B” and “A”) respectively and they have the weig![]() gives the best training error rate?
gives the best training error rate?
Exercise 3. (50 points) For this exercise, the only extra package allowed is ISLR2. The functions cut, glm, lm, predict, spline and splinefun are not allowed in this exercise.
The dataset Auto will be used throughout the exercise and is accessible through the ISLR2 package. We are interested in using horsepower to predict mpg.
I. Consider some continuous random variable X and some probability p. The p-quantile of X is defined as the value q such that
Pr{X < q} = p
For example, the 0.5-quantile is called the median. The 0.25, 0.5 and 0.75-quantiles are called the quartiles. The 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9-quantiles are called the deciles etc...
The R function quantile gives an empirical estimate of some arbitrary random variable's quantiles.
Building upon this knowledge, write an R function called findKnots that can be applied to horsepower to get the following answers
. findKnots(horsepower,2) yields 93.5.
. findKnots(horsepower,4) yields the three numbers 75.0, 93.5 and 126.0.
. findKnots(horsepower,10) yields the numbers 67.0, 72.0, 80.0, 88.0, 93.5, 100.0, 110.0, 140.0 and 157.7.
II. Write a function h1(x,xi) that takes a vector as first input argument and a single number as a second input argument. When applied to a grid of points x (for a particular value of xi), the R function yields a mathematical funciton whose plot is given by the following figure:
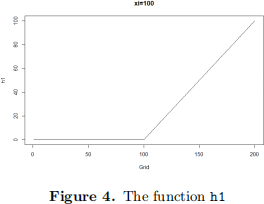
Reproduce the above figure. Describe the function mathematically and outline its importance in statistical learning.
III. Write an R function LinearSpline(x,b0,b1,b,xi) that is capable of generating figures like the following ones.
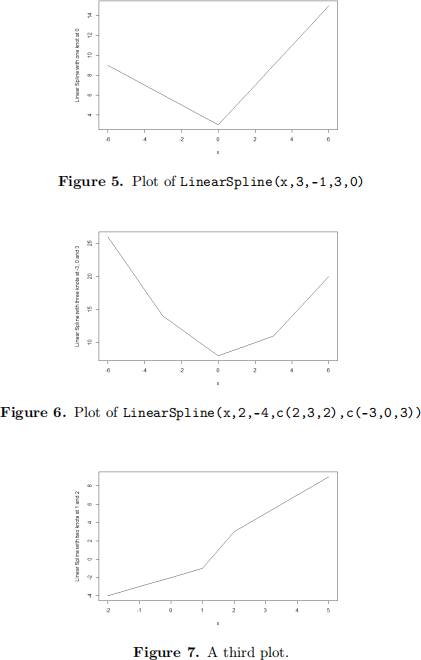
Reproduce each one of the three figures. Describe mathematically each of the func- tions in each one of the figures. In the case of the third plot, describe how it is possible to recover the function input arguments.
IV. Predict mpg by using a piecewise linear spline in horsepower at the knots 100 and 150, and then reproduce the following figure:
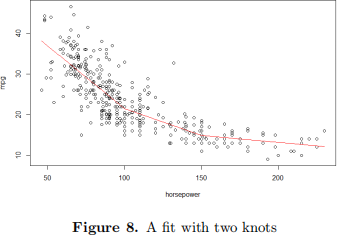
Describe mathematically how the learning algorithm work while detailing each step. What are the limitations and advantages of the such a model?
V. Using the simple validation set approach where the car model year being 76 is used for testing while all other car model years are used for training, choose the best model at prediction among the following 10 models:
1. A linear regression.
2. A linear spline with a knot at the median of horsepower.
3.
...
10. A linear spline with knots at the deciles of horsepower.
Produce a figure that has the fitof all 10 models on it. How accurate do you think the model selection is? What are the trade-offs?
VI. In case one wishes to extend the modeling strategy in the previous question to the case one has two input variables, describe at least two alternative ways of carrying out that extension. (write your answer using a maximum of 100 words)
2023-10-23