COSC3500/7502 Assignment : Parallel programming techniques
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
COSC3500/7502 Assignment : Parallel programming techniques
Rubric :
Hardware :
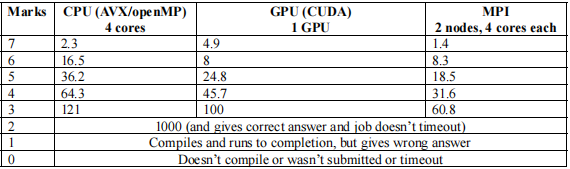
The benchmarks :
data amongst the nodes, it will already be there. However you will need to make sure that all nodes maintain a copy of the current matrix product answer, as each node will need this full matrix so it can calculate the next matrix product. That is, each node can calculate it’s own portion of the matrix multiply operation, but you will then have to make sure that all nodes end up with a full copy of the solution.
Turning on/off CPU, GPU, and/or MPI code :
The only code files you can modify for your final submission :
There are only 3 files you are allowed to change, matrixMultiply.cpp, matrixMultiplyGPU.cu, and matrixMultiplyMPI.cpp. Your functions are not allowed to use any header files or outside libraries, other than the provided header files (matrixMultiply.h, matrixMultiplyGPU.cuh, and matrixMultiplyMPI.h). Your functions must not write to stdout or to file in the final submission.
The script that will be used to assign your final grade is goslurm_COSC3500Assignment_RangpurJudgementDay. However for the love of nvidia PLEASE do not just submit all your jobs using this script, as you will overwhelm the vgpu10 nodes. Please use variations on the goslurm_COSC3500Assignment_RangpurDebug or goslurm_COSC3500Assignment_GetafixDebug scripts.
When calculating your final grade, as the final grade script will run on two nodes, with the CPU and GPU benchmarks run once on each node, the fastest node result (most favourable to you) will be used, although in practice the values tend to be almost identical and vary by less than 0.2 marks.
Software interface and the GradeBot
Assignment1_GradeBot.cpp is a remorseless marking machine. It can’t be bargained with. It can’t be reasoned with. It doesn’t feel pity, or remorse, or fear, and it absolutely will not stop, ever, until your COSC3500 assignment has been assigned a mark out of 21.
The GradeBot runs your benchmarks and assigns your marks. You can use it to get instant feedback.
./Assignment1_GradeBot {matrix dimension} {threadCount}{runBenchmarkCPU} {runBenchmarkGPU} {runBenchmarkMPI} {optionalinteger} {optional integer}…
./Assignment1_GradeBot 2048 4 1 0 1
Would run benchmarks of the 2048×2048 matrix multiply routines, using 4 threads per node for the CPU and MPI, but no GPU benchmark would be performed.
It is possible to supply an additional optional list of integer flags after the end of those 5 parameters that will be passed through to the matrixMultiply routines and can be used for debugging and tweaking.
./Assignment1_GradeBot 2048 4 1 0 1 64 128 256
Would pass the array [64 128 256] as the args parameter (argCount=3) to the matrixMultiply routines. How that array of integers is interpreted is entirely up to you, but remember they will not exist when the final JudgementDay script is called.
Text output :
The Assignment1_GradeBot will output to stdout, as well as individual text files for each benchmark on each node COSC3500Assignment_{benchmark type}_{node}.txt.
The text files will include 6 columns
Info. : {CPU|GPU|MPI}[{mpiRank},{mpiWorldSize}|{threadCount, gpuID, or mpiRank},{tota number of physical CPU cores, number of GPUs or mpiWorldSize]({hardware run on, e.g. CPU name, GPU name, or node name})
N : Matrix dimension
Matrices/second (MKL) : The number of matrix multiplies performed per second by the reference software MKL (CPU/MPI) or CUBLAS (GPU)
Matrices/second (You) : The number of matrix multiplies performed per second by your implementation.
Error : The sum of squares different between your final output matrix, and the reference implementation. Some small (<1e-7) floating point error is allowed, but larger errors are counted as a failed implementation.
Grade : The total number of marks assigned for this result.
Final Submission :
matrixMultiply.cpp
matrixMultiplyGPU.cu
matrixMultiplyMPI.cpp
Plus a zip file (within the master zip file containing the matrixMultiply files), slurm.zip, containing all your slurm job output files (slurm-xxxx.out).
If you have not implemented any of the required files (e.g. you’ve only implemented the CPU, but not the GPU, or MPI), then just submit the original blank files provided on blackboard.
The final submission must strictly have this format. Any deviation will not be forgiven by the cold uncaring scripts associated with Assignment1_GradeBot.cpp.
2023-10-05