Assignment 2 Autocomplete Lookup
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
Introduction
Autocomplete
Autocomplete highly enhances user experience for two reasons: it minimises the number of
keystrokes needed to specify a string input, while at the same time helps users with a suggestion of useful closely related inputs. Autocomplete typically wants to suggest the most likely strings that
share the preix speciied so far. Typically the preix is extended every time a new keyboard event is triggered, hinting that any successful autocomplete function should be as fast as the average human typist. Surveys suggest that the average person types 200 characters per minute, which means that ideally our autocomplete algorithm should not take longer than 0.3 seconds to suggest the correct autocompletion candidates. If autocomplete takes much longer, users will dislike our solution.
Another important aspect is that more than one candidate should be suggested according to their likelihood. If we fail suggesting the correct autocompletions users will not like our implementation either.
Autocomplete can be e![]() ciently implemented using a radix tree, which is a concrete data structure
ciently implemented using a radix tree, which is a concrete data structure
that stores and supports lookup of keys. Note that radix trees are like binary search trees but may
have more complex rules for children (e.g. branching is based on bit-level comparison of the strings, rather than full string comparisons). Radix trees are used as an associative data structure (trie), where each node does not store the full key (stores part of the key). The position of the node in the tree
deines the key associated with the node, where all its equal subtree descendants share the same key preix. A key can have an associated weight to indicate its likelihood.
Autocompletion can be implemented in C using a number of abstract data structures and underlying concrete data structures. Any implementation must support the operations:
![]() insert a new item < key, data > into a tree and
insert a new item < key, data > into a tree and
![]() find_and_traverse the tree given a preix, and return (or print) a list of pairs < key, data > where all keys share the same preix.
find_and_traverse the tree given a preix, and return (or print) a list of pairs < key, data > where all keys share the same preix.
In getting an understanding of the theory behind the new data structure used in stage 3, you may ind the original paper useful: PATRICIA—Practical Algorithm To Retrieve Information Coded in
Alphanumeric (Morrison, 1968).
Radix Trees
Though there are more compact ways to implement the radix tree data structure (e.g. the table
structure described in the original paper will allow the same functionality, but requires less data to be stored), the approach we recommend is a linked data structure made up of nodes. These nodes will contain:
![]() An integer representing the number of bits which are a common preix to all entries in the chain. If there are no common bits, this will be 0.
An integer representing the number of bits which are a common preix to all entries in the chain. If there are no common bits, this will be 0.
![]() A dynamically allocated array of character values, this will contain the entire common preix.
A dynamically allocated array of character values, this will contain the entire common preix.
![]() One pointer to a node called branchA , this covers the branching structure when the bit following the common preix is 0.
One pointer to a node called branchA , this covers the branching structure when the bit following the common preix is 0.
![]() One pointer to a node called branchB , this covers the branching structure when the bit following the common preix is 1.
One pointer to a node called branchB , this covers the branching structure when the bit following the common preix is 1.
![]() One pointer to a list of associated data items.
One pointer to a list of associated data items.
This particular approach assumes a unique termination character is also part of the string (we will use the character where all bits of the character are 0 ( \0 ) for this character).
With this approach, we keep track of the number of bits we have processed through, adding the preixes of those bits to the key constructed so far.
To check if the key has been completed, after processing the bits in the current node, the number of bits seen can be checked to see if it is a multiple of 8 and the inal character can be checked to see if it contains a \0 (both conditions are necessary).
To treat the searched key as a preix, the terminating character is ignored, with all descendant nodes of the matching preix position traversed and the associated values of all completed keys returned.
Your Task
Your task involves two new stages and a report. The irst new stage is Stage 2, which implements
Autocomplete behaviour using a sorted array as the concrete implementation. Then the second new stage will be Stage 3, which uses a radix tree. After completing the two new stages, you will compare their performance in a report. For the report, you will need to devise and carry out a process which makes use of what you have learned in the subject so far.
For the two new stages, your output to the output ile will be the same format as Assignment 1, but the output to the terminal will change. To support your analysis, this output is recommended to be the number of bits compared, the number of characters compared and the number of whole strings compared.
Implementation Details
Example Radix Tree Insertions
The irst insertion is conceptually very simple. The radix tree is initially empty, so the preix
comprises the entire key. The diagram below shows the data structure, with the letters shown to illustrate what the binary values tell us about the key.

Work needs to be done when the second key is added. If we add "Arbory Bar and Eatery" to the radix tree, the two difer in the irst character. D has binary representation 0b01000100, and A has binary representation 0b01000001, so the irst 5 bits (0b01000) are a shared preix.
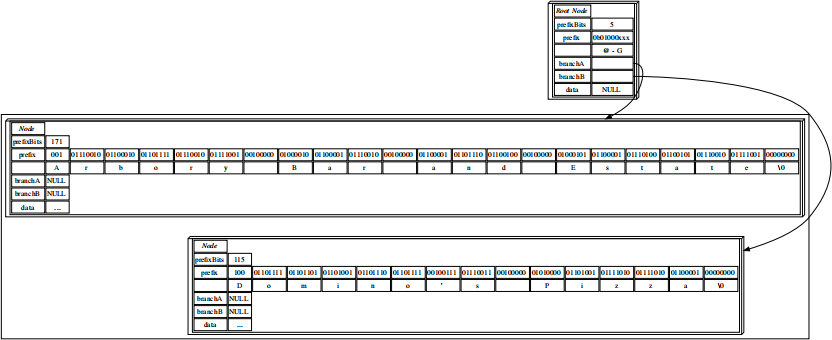
Note in this case that the separation of bits is just for visual clarity, the irst byte in the "Domino's Pizza" terminal's preix would contain 100 01101.
The inal type of insertion is the duplicate. For this type of insertion, you should add the new record to the end (or start) of the data list - the conceptually simplest way to do this is to have a function
which searches for the full key in the radix tree to ind the associated node, and then if found, to add the new data to the end of that list. This approach keeps the add logic simple - it would be possible to combine these for e![]() ciency and code deduplication reasons, but we are most concerned with search performance.
ciency and code deduplication reasons, but we are most concerned with search performance.
Tips
To implement the Radix Tree, a recommended approach is to write two functions, one to get a
particular bit from a given character (e.g. getBit(key, n) ) and a second to extract a stem from a given key (e.g. splitStem(key, start, length) ) which extracts a certain number of bits from a given key. Since the earliest bit in a character is the largest value (i.e. 0b10000000 = 128 ), this
process is otherwise error prone.
A few operators you may not be aware of for working on bits in numbers which may be useful are shown in the following table.

Stage 2 - Sorted Array Autocomplete
In Stage 2, you will implement the insert and find_and_traverse operations using a sorted array as the concrete data structure. After constructing the sorted array using repeated insert operations, you can then use find_and_traverse to ind a key matching the preix by using a binary search, you should then linearly search around this location to ind adjacent values which also match the preix until you have found all values matching the preix.
Your Makefile should produce an executable program called dict2 . This program should take three command line arguments.
1. The irst argument will be the stage, for this part, the value will always be 2. 2. The second argument will be the ilename of the data ![]() le.
le.
3. The third argument will be the ilename of the output ![]() le.
le.
Your program should:
![]() Just as in Assignment 1, read data from the data ile speciied in the second command line argument. This may be stored unchanged from dict1 in earlier implementations.
Just as in Assignment 1, read data from the data ile speciied in the second command line argument. This may be stored unchanged from dict1 in earlier implementations.
![]() Construct a Sorted Array, sorted on the trading_name
Construct a Sorted Array, sorted on the trading_name ![]() attribute.
attribute.
![]() Accept (assumed) partial trading_name s from stdin, search using a binary search and print all records matching the preix to the output ile. You may assume that all queries will be strings terminated by a newline and will always consist of full characters. Though you can use this to allow the querying of the entire dataset, you may also assume preixes are at least one
Accept (assumed) partial trading_name s from stdin, search using a binary search and print all records matching the preix to the output ile. You may assume that all queries will be strings terminated by a newline and will always consist of full characters. Though you can use this to allow the querying of the entire dataset, you may also assume preixes are at least one
character long and will always begin with a standard ASCII letter for simplicity. Unlike the irst assignment, for this stage, your program should not output any speciic output where no records are found matching the preix.
![]() In addition to outputting the record(s) to the output ile, the number of comparisons should be output to stdout. It is recommended that this show the number of bits, bytes (characters) and strings compared.
In addition to outputting the record(s) to the output ile, the number of comparisons should be output to stdout. It is recommended that this show the number of bits, bytes (characters) and strings compared.
For testing, it may be convenient to create a ile of queries to be searched, one per line, and redirect the input from this ile. Use the UNIX operator < to redirect input from a ile.
Example Execution
An example execution of the program might be:
make -B dict2
# ./dict2 stage datafile outputfile
./dict2 2 dataset_2.csv output.txt
followed by typing in the queries, line by line, and then ending input once all keys are entered or:
make -B dict2
# ./dict2 stage datafile outputfile
./dict2 2 dataset_2.csv output.txt < queryfile
Example Output
This is an example of what might be output to the output ![]() le after two queries:
le after two queries:
McDonalds
--> census_year: 2021 || block_id: 114 || property_id: 103235 || base_property_id: 103235 || buildi --> census_year: 2020 || block_id: 65 || property_id: 109301 || base_property_id: 109301 || buildin --> census_year: 2020 || block_id: 931 || property_id: 103908 || base_property_id: 103908 || buildi Standing Room
With the following output to stdout:
McDonalds --> b472 c59 s12
Standing Room --> b232 c29 s10
Stage 3 - Radix Tree Autocomplete
In Stage 3, you will use a Radix Tree as the concrete data structure to implement your approach.
Your Makefile should now also produce an executable program called dict3 . This program should follow the same input and output format at Stage 2.
Your dict3 program should:
![]() Just as Stage 2, read in the dataset, store it in a dictionary and construct an autocomplete dictionary on the stored data.
Just as Stage 2, read in the dataset, store it in a dictionary and construct an autocomplete dictionary on the stored data.
· For Stage 3, you should store the data in a Radix Tree of order 2 as described in the example at the top of this slide and the earlier slides. This tree should be searched by comparing the next highest order bit in the preix being searched with the associated value in the preix seen so far. In order to align your solution with the provided test cases, your solution should not count the branching comparison as a bit comparison, but should count the irst bit in the preix following the branch as a bit comparison (getting this wrong may lead to minor variations). In traversing the matches, branchA should be fully explored before branchB ![]() .
.
![]() Output should be in the same format as Stage 2. For simplicity, you may make a reasonable assumption about how to count string comparisons, whether or not a string comparison
Output should be in the same format as Stage 2. For simplicity, you may make a reasonable assumption about how to count string comparisons, whether or not a string comparison
explicitly occurs. For this reason, some edge cases will deliberately not be checked.
Example Execution
An example execution of the program might be:
make -B dict3
# ./dict3 stage datafile outputfile
./dict4 3 dataset_2.csv output.txt
followed by typing in the queries, line by line, and then ending input once all keys are entered or:
make -B dict3
# ./dict3 stage datafile outputfile
./dict3 3 dataset_2.csv output.txt < queryfile
Example Output
This is an example of what might be output to the output ![]() le after two queries:
le after two queries:
McDonalds
--> census_year: 2021 || block_id: 114 || property_id: 103235 || base_property_id: 103235 || buildi --> census_year: 2020 || block_id: 65 || property_id: 109301 || base_property_id: 109301 || buildin --> census_year: 2020 || block_id: 931 || property_id: 103908 || base_property_id: 103908 || buildi Standing Room
With the following output to stdout:
McDonalds --> b74 c20 s1
Standing Room --> b45 c21 s0
Experimentation
You will run various test cases through your program to test its correctness and also to examine the number of key comparisons used when searching key preixes across diferent iles. You will report on the number of comparisons used by your Stage 2 and Stage 3 implementations for diferent data file inputs and key preixes. You will compare these results with what you expect based on theory (Big-O).
Your approach should be systematic, varying the size of the iles you use and their characteristics (e.g.
sorted/unsorted, duplicates, range of key space, length of preix, etc.), and observing how the number of key comparisons varies given diferent sizes of key preixes. Looking at statistical measures about the results of your tests may help.
UNIX programs such as sort (in particular -R ), head , tail , cat and awk may be valuable. You may also ind small C programs (or additional "Stages") useful, the test data you produce and use does not have to be restricted to the dataset provided.
Additionally, though your C code should run on Ed, you may like to run omine tests or other work outside of Ed and are welcome to do so.
You will write up your indings and submit them along with your Assignment Submission in the Assignment Submission Tab.
![]() Make sure to click the "Mark" button after uploading your report. It is often the case for results to be released and more than a handful of students to ind an unexpected 0 mark for the report due to not technically
Make sure to click the "Mark" button after uploading your report. It is often the case for results to be released and more than a handful of students to ind an unexpected 0 mark for the report due to not technically
submitting it for marking.
You are encouraged to present the information you've collected in appropriate tables and graphs. Select informative data, more is not always better.
In particular, you should present your indings clearly, in light of what you know about the data
structures used in your programs and in light of their known computational complexity. You may ind that your results are what you expected, based on theory. Alternatively, you may ind your results do not agree with theory. In either case, you should state what you expected from the theory, and if
there is a discrepancy you should suggest possible reasons. You might want to discuss space-time trade-ofs, if this is appropriate to your code and data.
You are not constrained to any particular structure in this report, but a well laid out plan with a strong structure tends to lead to the best results. A more general and helpful guiding structure is shown in
the Additional Support slide, but you may ind it valuable to keep in mind a general low:
![]() Introduction - Summary of data structures and inputs.
Introduction - Summary of data structures and inputs.
![]() Stage 2 and Stage 3:
Stage 2 and Stage 3:
- Data (data ile, number of keys, characteristics, summary statistics for relevant metrics)
- Comparison with theory
![]() Discussion
Discussion
Dataset
The sample dataset is the same as Assignment 1, but is reproduced here for completeness.
The dataset comes from the City of Melbourne Open Data website, which provides a variety of data about Melbourne that you can explore and visualise online:
https://data.melbourne.vic.gov.au/
The dataset used in this project is a subset of the Cafes and Restaurants with Seating Capacity dataset.
The processed dataset can be found in the Dataset Download slide. You aren't expected to perform this processing yourself.
The provided dataset has the following 14 ields:
census_year - The year the information was recorded for (integer)
block_id - The city block ID. (integer)
property_id - The ID of the property. (integer)
base_property_id - The ID of the building the business is in. (integer)
building_address - The address of the building. (string)
clue_small_area - The CLUE area of Melbourne that the building is in. (string)
business_address - The address of the business itself. (string)
trading_name - The name of the business. (string)
industry_code - The ID for the category of the business. (integer)
industry_description - The description of the category of the business. (string)
seating_type - The type of seating the record describes. (string)
number_of_seats - The number of seats provided of this type. (integer)
longitude - The longitude (x) of the seating location. (double)
latitude - The latitude (y) of the seating location. (double)
The ields building_address , clue_small_area , business_address , trading_name ![]() ,
,
industry_description and seating_type are strings, and could contain spaces or commas. You may assume none of these ields are more than 128 characters long. The ields census_year ![]() ,
,
block_id , property_int , base_property_id , industry_code and number_of_seats are integers, you may assume they are always speciied and present. The ields longitude and latitude ![]() are
are
double values, you should store them so that they can be printed correctly to 5 decimal places.
This data is in CSV format, with each ield separated by a comma. For the purposes of the assignment, you may assume that:
![]() the input data are well-formatted,
the input data are well-formatted,
![]() input iles are not empty,
input iles are not empty,
![]() input iles include a header,
input iles include a header,
![]() ⚠ any ield containing a comma will begin with a double quotation mark ( " ) and end with a quotation mark ( " ),
⚠ any ield containing a comma will begin with a double quotation mark ( " ) and end with a quotation mark ( " ),
![]() each ield contains at least one character,
each ield contains at least one character,
· ields always occur in the order given above, and that
![]() the maximum length of an input record (a single full line of the CSV) is 512 characters.
the maximum length of an input record (a single full line of the CSV) is 512 characters.
Where a string contains a comma, the usual CSV convention will be followed that such strings will be delimited with a quotation mark (always found at the beginning and end of the ield) — these quotes should not be preserved once the data is read into its ield. You may assume no quotes are present in the processed strings when they are stored in your dictionary.
Smaller samples of these datasets can be found in the Dataset Download slide.
Requirements
The following implementation requirements must be adhered to:
![]() You must write your implementation in the C programming language.
You must write your implementation in the C programming language.
![]() You must write your code in a modular way, so that your implementation could be used in
You must write your code in a modular way, so that your implementation could be used in
another program without extensive rewriting or copying. This means that the dictionary
operations are kept together in a separate .c ile, with its own header (.h) ile, separate from the main program, and other distinct modules are similarly separated into their own sections,
requiring as little knowledge of the internal details of each other as possible. Though note that your approach is not expected to implement object oriented principles strictly or deliberately.
![]() Your code should be easily extensible to multiple dictionaries. This means that the functions for interacting with your dictionary should take as arguments not only the values required to
Your code should be easily extensible to multiple dictionaries. This means that the functions for interacting with your dictionary should take as arguments not only the values required to
perform the operation required, but also a pointer to a particular dictionary, e.g.
search(dictionary, value) ![]() .
.
![]() Your implementation must read the input ile once only.
Your implementation must read the input ile once only.
![]() Your program should store strings in a space-e
Your program should store strings in a space-e![]() cient manner. If you are using malloc()
cient manner. If you are using malloc() ![]() to
to
create the space for a string, remember to allow space for the inal end of string character,‘ \0 ’ ( NULL ).
![]() Your program should store its data in a space-e
Your program should store its data in a space-e![]() cient manner. If you construct an index, this index should not contain information it does not need.
cient manner. If you construct an index, this index should not contain information it does not need.
![]() Your approach should be reasonably time e历cient.
Your approach should be reasonably time e历cient.
![]() A full Makeile is not provided for you. The Makeile should direct the compilation of your program. To use the Makeile, make sure it is in the same directory as your code, and type make dict2 and make dict3 to make the dictionary. You must submit your Makeile with your assignment.
A full Makeile is not provided for you. The Makeile should direct the compilation of your program. To use the Makeile, make sure it is in the same directory as your code, and type make dict2 and make dict3 to make the dictionary. You must submit your Makeile with your assignment.
Hints:
• If you haven’t used make before, try it on simple programs irst. If it doesn’t work, read the error messages carefully. A common problem in compiling multiile executables is in the included header iles. Note also that the whitespace before the command is a tab, and not multiple spaces.
• It is not a good idea to code your program as a single ile and then try to break it down into multiple iles. Start by using multiple iles, with minimal content, and make sure they are communicating with each other before starting more serious coding.
Programming Style
Below is a style guide which assignments are evaluated against. For this subject, the 80 character
limit is a guideline rather than a rule — if your code exceeds this limit, you should consider whether your code would be more readable if you instead rearranged it.
/** ***********************
* C Programming Style for Engineering Computation
* Created by Aidan Nagorcka-Smith ([email protected]) 13/03/2011
* Definitions and includes
* Definitions are in UPPER_CASE
* Includes go before definitions
* Space between includes, definitions and the main function .
* Use definitions for any constants in your program, do not just write them * in .
*
* Tabs may be set to 4-spaces or 8-spaces, depending on your editor . The code
* Below is ``gnu'' style . If your editor has ``bsd'' it will follow the 8-space
* style . Both are very standard . */
/**
* GOOD:
*/
#include
#include
#define MAX_STRING_SIZE 1000
#define DEBUG 0
int main(int argc, char **argv) {
...
/**
* BAD:
*/
/* Definitions and includes are mixed up */
#include
#define MAX_STING_SIZE 1000
/* Definitions are given names like variables */
#define debug 0
#include
/* No spacing between includes, definitions and main function*/
int main(int argc, char **argv) {
...
/** *****************************
* Variables
* Give them useful lower_case names or camelCase . Either is fine,
* as long as you are consistent and apply always the same style .
* Initialise them to something that makes sense . */
/**
* GOOD: lower_case
*/
int main(int argc, char **argv) {
int i = 0;
int num_fifties = 0;
int num_twenties = 0;
int num_tens = 0;
...
/**
* GOOD: camelCase
*/
int main(int argc, char **argv) {
int i = 0;
int numFifties = 0;
int numTwenties = 0;
int numTens = 0;
...
/**
* BAD:
*/
int main(int argc, char **argv) {
/* Variable not initialised - causes a bug because we didn't remember to
* set it before the loop */
int i;
/* Variable in all caps - we'll get confused between this and constants
*/
int NUM_FIFTIES = 0;
/* Overly abbreviated variable names make things hard . */
int nt = 0
while (i < 10) {
...
i++;
}
...
/** ********************
* Spacing:
* Space intelligently, vertically to group blocks of code that are doing a
* specific operation, or to separate variable declarations from other code .
* One tab of indentation within either a function or a loop .
* Spaces after commas .
* Space between ) and { .
* No space between the ** and the argv in the definition of the main
* function .
* When declaring a pointer variable or argument, you may place the asterisk
* adjacent to either the type or to the variable name .
* Lines at most 80 characters long .
* Closing brace goes on its own line */
/**
* GOOD:
*/
int main(int argc, char **argv) {
int i = 0;
for(i = 100; i >= 0; i--) {
if (i > 0) {
printf("%d bottles of beer, take one down and pass it around,"
" %d bottles of beer.\n", i, i - 1);
} else {
printf("%d bottles of beer, take one down and pass it around . "
" We're empty.\n", i);
}
}
return 0;
}
/**
* BAD:
*/
/* No space after commas
* Space between the ** and argv in the main function definition
* No space between the ) and { at the start of a function */ int main(int argc,char ** argv){
int i = 0;
/* No space between variable declarations and the rest of the function .
* No spaces around the boolean operators */
for(i=100;i>=0;i--) {
/* No indentation */
if (i > 0) {
/* Line too long */
printf("%d bottles of beer, take one down and pass it around, %d
bottles of beer.\n", i, i - 1);
} else {
/* Spacing for no good reason . */
printf("%d bottles of beer, take one down and pass it around . "
" We're empty.\n", i);
}
}
/* Closing brace not on its own line */
return 0;}
/** ****************
* Braces:
* Opening braces go on the same line as the loop or function name
* Closing braces go on their own line
* Closing braces go at the same indentation level as the thing they are
* closing */
/**
* GOOD:
*/
int main(int argc, char **argv) {
...
for(...) {
...
}
return 0;
}
/**
* BAD:
*/
int main(int argc, char **argv) {
...
/* Opening brace on a different line to the for loop open */
for(...)
{
...
/* Closing brace at a different indentation to the thing it's
closing
*/
}
/* Closing brace not on its own line . */
return 0;}
/** **************
* Commenting:
* Each program should have a comment explaining what it does and who created * it .
* Also comment how to run the program, including optional command line
* parameters .
* Any interesting code should have a comment to explain itself .
* We should not comment obvious things - write code that documents itself */
/**
* GOOD:
*/
/* change.c
*
* Created by Aidan Nagorcka-Smith ([email protected])
13/03/2011
*
* Print the number of each coin that would be needed to make up some change
* that is input by the user
*
* To run the program type:
* ./coins --num_coins 5 --shape_coins trapezoid --output blabla.txt
*
* To see all the input parameters, type:
* ./coins --help
* Options::
* --help &nb
2023-09-14