ECS607U Data Mining Winter Examination Period 2021
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
Winter Examination Period 2021 一 January 一 Semester A
MAIN
ECS607U Data Mining
Question 1
(a) suppose you are hired by our department as a data analyst and you are provided with the anonymised data of the previous years, students. Your irst assigned task is to develop an app that predicts whether a student will pass a module that s/he is going to take in the next semester.
(i) what kind of data mining task is this (regression, classiication, cluster- ing, association mining, outlier detection)? provide a brief justiication for your answer.
(ii) To accomplish this task, you should irst think of some useful features (predictive attributes) to collect. provide 3 example features that can be relevant for this task: one numerical feature, one nominal feature, and one ordinal feature. [10 marks 一 word limit 100]
(b) suppose you are hired as a data analyst of a hospital. As your irst task, you would like to perform a clustering of all the patients.
(i) some of the attributes of the patients are: weight, height, age, etc. You also notice that one of the features (attributes) of the patients is their blood type, which takes one of the four values of A, B, AB, O. Briely explain why you should convert this categorical feature to numerical.
(ii) You seem to have two options for numeric encoding of the blood type: one is to use the following mapping: A:0, B:1, AB:2, O:3. The other option is to use one-hot encoding. Briely describe what the one-hot encoding does in this example. In particular, provide what the encoding will be for each of the 4 values of the blood type.
(iii) provide one advantage and one disadvantage of choosing the irst encoding as opposed to the one-hot encoding. which of these two encoding schemes would you choose in this case? Briely justify your answer. [10 marks 一 word limit 150]
(c) suppose we are collecting census data about the wealth of each individual in a society. we notice that in this particular (hypothetical) society, 1% of the population owns 99% of the total wealth. Let the median (50th percentile) of the individual wealth be M and the mean (average) of the individual wealth be C. Determine which one of the following statements holds about the statistics of this particular society:
(a) M 三 C;
(b) C 三 M;
(c) It is not possible to tell; that is, given the information, all cases of M < C, M = C, and M > C are possible.
Support your answer with a brief explanation. [5 marks 一 word limit 100]
Question 2
(a) suppose we have a labelled dataset of many samples where each sample is represented by 3 numerical features f1, f2 and f1. The label denoted by target is also numerical. we would like to use this dataset to train a model that can predict the value of target for new unlabelled samples. The correlation matrix of our dataset is a 4*4 matrix given in Table 1.

If you would like a visualisation, the “pairplot” of our dataset is also provided in Figure 1.

(i) suppose you are forced to use only one of the 3 features f1, f2, or f3 along with 大arge大 to train your model. which one of them would you choose? your answer must be backed by a brief but clear reasoning.
(ii) Answer the same question if you were forced to choose only two fea- tures from f1, f2, f3 (along with target). which ones will you choose and why? [10 marks 一 word limit 100]
(b) consider a dataset of 50 samples, where each sample in the dataset has a numerical attribute f, and a binary categorical attribute c. we are given the summary statistics of this dataset grouped by c in Table2.
Table 2: The summary statistics of a dataset grouped by the (binary) categorical feature c (Q2-b).
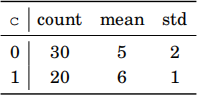
using the information of the table, compute the mean and std (standard deviation) of feature f across all samples (that is, no longer grouped by c). Make sure to provide the detail of your working. [7 marks 一 word limit 100]
(c) Recall the relation for the X2 test of independence for two categorical attributes A and B:
Let (Ai ,Bj ) denote the joint event that attribute A takes on value ai and attribute B takes on value bj , i.e. (A = ai ,B = bj ). The X2 value is computed as:

(i) Briely describe the termsoij and eij used in the formula. In particular, explain how we compute them in a given dataset.
(ii) Determine whether the following statement is correct or incorrect: “The larger the computed value of X2 , the higher the likelihood that the two categorical attributes A and B are independent”.
You should support your answer with a simple intuitive explanation using your own words (avoiding any unclear statistical jargon). [8 marks 一 word limit 100]
Question 3
(a) consider the following table of (hypothetical) weather measurements in two London boroughs on certain dates:
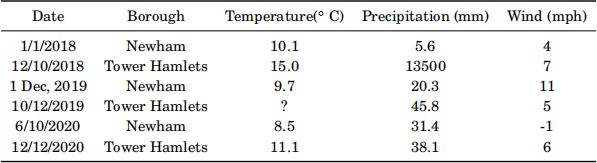
Identify 4 data cleaning issues in this dataset and describe how to take care of each. [10 marks 一 word limit 100]
(b) consider a data warehouse for an airline company which includes dimen- sions on passenger, day of the light (departure), source airport (departure), destination airport (arrival), and the ticket fee paid by a passenger.
(i) starting from the base cuboid [day, passenger, source, destination, fee], which OLAP (online analytical processing) operations should be performed in order to list the total ticket fees collected from lights departing from a speciic airport over a speciic month of a speciic year (e.g. during January of 2019 from Heathrow)?
(ii) Assuming we are interested in daily, weekly, monthly, and annual reports, compute how many cuboids does our data cube contain (in- cluding the base and the apex cuboid)? show the detail of your work. [10 marks 一 word limit 100]
(c) The dendrogram in Figure 2 (on the next page) is achieved by running an agglomerative clustering on a dataset of 10 samples. The samples are identiied by letters A through J.
(i) Referring to the igure, determine what the resulting clusters are if we want to have only 2 clusters?
(ii) Answer the same question if we wanted to have 4 clusters. [5 marks 一 word limit 50]

Question 4
(a) Consider the following dataset showing the elective modules taken by 8 hypothetical CS students:

Answer the following question accordingly. Make sure to provide your working, not just the inal answer.
(i) what is the support count (absolute support) of the itemset {ECS607, ECS640}? what is the (relative) support of the itemset {ECS610, ECS640, ECS607}?
(ii) Consider the minimum (relative) support of 0.4 and minimum coni- dence threshold of 0.7. Is the association rule {ECS640}导{ECS607} acceptable? what about {ECS607}导{ECS640}? [10 marks 一 word limit 100]
(b) The linkage graph of three webpages is depicted in Fig.3.
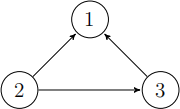
Figure 3: The linkage graph of 3 webpages (Q4-b).
(i) without any calculation, based on an intuitive argument, which page do you expect to have the highest pageRank score? which page the lowest?
(ii) Suppose we want to compute the pageRank score of these pages. Is it necessary to use a nonzero value for a?Briely explain your answer.
(iii) Taking a = 0, write down the linear system of equations governing the pageRank scores. Try to solve it if you have time and verify whether your results match your expectation in part (i) of the question. [8 marks 一 word limit 150]
(c) This question is regarding performance metrics of classiiers.
(i) suppose we want to use a binary classiier to detect a very rare disease in a population. Do you prefer a classiier that has a high value of recall (close to 1) and a low value of precision, or one with a high value of precision (close to 1) and low value of recall? provide your argument.
(ii) consider a binary classiier that achieves “precision” value of 0.8, and “recall” value of 0.7 on a “balanced” dataset. compute what you would expect to be the “accuracy” measure of this classiier on the same dataset. show the detail of your work. [7 marks 一 word limit 150]
2023-08-23