ECS607U Data Mining 2019–2020
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
2019-2020 sem A
ECS607U Data Mining
Question 1
(a) suppose we have trained a parametric machine learning model using a labelled dataset. using validation techniques, we have noticed that our model is“over-itting”. For each of the following actions (on its own), determine whether it helps against over-itting (reduces over-itting), it hurts over-itting (makes it worse), or has no effect.
Note that your answers should be supported with a brief but clear explanation.
(i) Re-train with regularisation?
(ii) lncreasing the degrees of freedom of the model?
(iii) Train with a larger dataset? [9 marks]
(b) suppose a company wants to explore the effect of advertising on its sales. The data scientist of the company has collected the historical data as follows:
|
|
x (Million S per year) |
y (Million S per year) |
|
year 1 |
2 |
10 |
|
year 2 |
4 |
50 |
|
year 3 |
1 |
20 |
|
year 4 |
3 |
30 |
Namely, x has been the expenditure of the company on advertisement and y has been their overall sales per each year.
(i) what type of data mining problem is this (e.g. classiication, regression, clustering, etc.)? and why?
(ii) suppose our data scientist decides to use a simple linear model. Therefore, she can represent the model with two parameters w0 and w1 , where w0 is the intercept. Express the loss function that needs to be minimised during training for this training data set. You can assume the loss function is just the Mean-squared- Error (MsE). Your expression is parametrically in terms of w0 and w1. You don,t have to use a matrix representation: an expanded summation form is ine. No simpliication is necessary.
(iii) Recall that the best weights (achieving minimum MsE) is given by the formula w = (X TX)-1X TY. using this formula, derive the best trained model. You can use the following intermediate computation:
(X TX)-1 = l 10(.)55 ![]() 02(.5)] ,
02(.5)] ,
show all the steps involved in your calculation, not just the inal result.
(iv) use your obtained MMSE model to predict the overall sales of the company for next year if they have decided to spend 4 Million S on advertisement in that year .
(v) Describe the steps that you would take to obtain MMSE coeficients of the polyno- mial model y = wo + w1x + w2x2 + w3x3 + w4x4. Also specify (without computing the weights) what would you expect the training MSE of this polynomial model be? (Briely justify your answer.) [16 marks]
Question 2
(a) consider the dataset shown in Figure 1. This dataset consists of samples belonging to two classes (circle and cross: O and x)and each sample is described by two features (predictors): XA and XB .
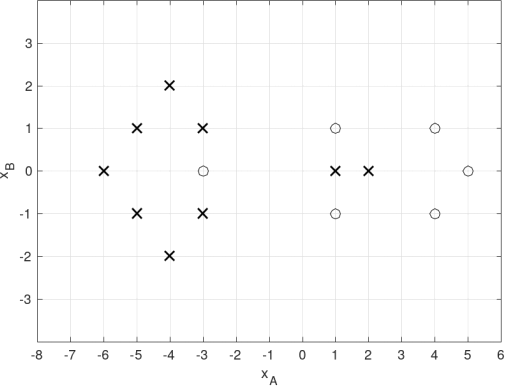
Figure 1: Question 2(a).
First, consider a family of linear classiiers deined by the equation W Tx = 0, where W is the coeficients vector and x = [1, XA , XB]T . A sample xi such that WTxi > 0 will be labelled as“circle”, whereas a sample xi such that WTxi 三 0 will be labelled as“cross”.
Given the linear classiierdeined by W = [2, 1, 0]T , answer the following questions.
(i) ldentify the classiier,s decision regions.
(ii) obtain the classiier,s confusion matrix for the dataset shown in Figure 1 and compute the sensitivity (true positive rate)and speciicity (true negative rate)of the classiier for this dataset.
(iii) Express the likelihood of the classiier L for the dataset shown in Figure 1 in terms of the logistic function p(t), p(t)= ![]() . You do not need to evaluate p(t)for every sample in the dataset. For instance for a sample such that t = 30, simply write p(30).
. You do not need to evaluate p(t)for every sample in the dataset. For instance for a sample such that t = 30, simply write p(30).
(iv) will the likelihood of the linear classiier increase if we use the boundary w = [0, 1, 0]T instead? Justify your answer. [12 marks]
(b) Now consider a Bayes classiier for the same dataset. This Bayes classiier will use the predictor XA only and we will assume that both classes produce XA values that follow a Gaussian distribution. ln addition, the Gaussian distributions of XA values for
each class are assumed to have different, unknown means, and equal variance.
(i) Estimate the means of the Gaussian distributions for both classes.
(ii) Describe the corresponding Bayes classiier.
(iii) How is a sample whose XA = -0.5 is classiied?
(iv) Describe a Bayes classiier that uses both predictors (XA and XB), by assuming that samples from both classes follow a Gaussian distribution with the same covariance matrix, and different means. ls the resulting boundary linear? [13 marks]
Question 3
(a) An ensemble model is the (weighted) sum of the decisions of individual experts/mod- els.
(i) why is it beneicialto increase the diversity of the experts in an ensemble? (ii) How do boosting methods differ from methods that increase the diversity?
(iii) Describe the steps of a boosting algorithm. [9 marks]
(b) This question is about Gaussian Mixture Model (GMM)and K-means clustering.
(i) contrast the assumptions made explicitly or implicitly by GMM versus K-means clustering algorithms.
(ii) Explain what is meant by the fact that both GMM and K-means only converge to local minima of their objective function, rather than global minimum.
(iii) ln relation to the issue of convergence to local minima (compare with part (ii)), outline a simple procedure that can improve both the performance of K-means and GMM as well as the repeatability of their results. [10 marks]
(c) Describe 2 methods for selecting a good value of K in the K-means algorithm. Explain in detail how each one works. [6 marks]
Question 4
(a) ln some learning-from-data problems, obtaining labels for data is costly. E.g., inding out if a inancial transaction is fraudulent may require hours of an analyst,s time. These situations typically result in more unlabelled data than labelled data.
(i) Both semi-supervised and active learning aim to deal with the sparse labels problem, but there are a few important differences in how they work. what are they?
(ii) Describe the steps of an active learning method. Give some criteria that could be useful for selecting which data samples will be labelled next. [8 marks]
(b) Recall that “ilter” and“wrapper” are two methods for feature selection. Describe one advantage and one disadvantage for using ilter methods compared to wrapper methods. [7 marks]
(c) Time-series prediction methods such as autoregressive (AR) models are commonly used in forecasting tasks involving variables changing over time, such as price predic- tion.
(i) outline how these methods relate to classic linear regression problems.
(ii) what unique challenges are created for fairly training and realistically evaluating these models compared to models of independently distributed data.
(iii) what is the idea behind extending AR models to include exogenous inputs (ARX models)? [10 marks]
2023-08-22