COMS30033 Machine Learning (Mock exam) 2022
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
January 2022 (Mock exam) Examination Period
Department of Computer Science
3rd Year Examination for the Degrees of
Bachelor in Computer Science
Master of Engineering in Computer Science
COMS30033
Machine Learning (Mock exam)
TIME ALLOWED:
2 Hours
plus 30 minutes to allow for collation and uploading of answers.
Part 1: Short questions (5 marks each)
Question 1 (5 marks)
Which form(s) of learning requires a explicit target?
Question 2 (5 marks)
What is the key difference between parametric and non-parametric models?
Question 3 (5 marks)
Figure 1 shows a Bayesian network structure (i.e. directed acyclic graph). Write down all pairs of variables which are independent conditional on F.

Figure 1: Directed acyclic graph for Question 3
Question 4 (5 marks)
Let (1, 5, 2) and (1, 3, 1) be the first two principal components computed from some dataset. Let ①1 = (2, 6, 0) and ①2 = (−6, 1, 2) be two datapoints. Compute a 2-d approximation for each of ①1 and ①2 using the two principal components.
Question 5 (5 marks)
Suppose you were using EM to estimate the parameters of a mixture of 3 Gaussians. Let ①i be a training datapoint where Ⅵ (①i |μ1 , Σ 1 ) = 0.2, Ⅵ (①i |μ2 , Σ2 ) = 0.1, Ⅵ (①i |μ3 , Σ3 ) = 0.4. μj and Σj are the current parameter values for the jth Gaussian. Let Ti1 = 0.4, Ti2 = 0.2, Ti3 = 0.4 be the current responsibilites for ①i. What are the current values for the mixing coefficients.
Question 6 (5 marks)
When using MCMC what is burn-in (2 marks) and we do we use it (3 marks)?
Question 7 (5 marks)
(a) Must kernel function always return non-negative values? If yes, explain why. If no, find values of ① , g and k such that k(①, g) < 0, and where k is a valid kernel function.
(b) Explain why kernels must symmetric: i.e. k(①, g) = k(g, ①).
Question 8 (5 marks)
This question is about decision trees. We have a dataset containing three types of clothing with three features:

(a) What is the minimum depth of tree that would give zero training error? Explain your reasoning.
(b) In general, are there any problems that might arise if we grow a decision tree until there is zero training error? Explain your reasoning and give some ways to avoid this problem with CART trees.
Question 9 (5 marks)
Explain in words how the Adaboost method applies weights to training data instances, and why it does this?
Question 10 (5 marks)
Labelled data is important for supervised machine learning and evaluating machine learn- ing systems. A common solution for obtaining large labelled datasets is crowdsourcing. Briefly explain two disadvantages or challenges of using crowdsourcing to obtain labelled data.
Part 2: Long questions (10 marks each)
Question 11 (10 marks)
(a) Which of the following models overfit, underfit and provide an adequate fit to the data? (3 marks)

Figure 2: Examples of data (red scatter plot) with three different models (A,B,C; blue solid line).

Figure 3: Schematic of a simple artificial neural network.
(b) Given a very simple neural network with only one input x and one output neuron y with a linear activation f function, where x = 0.5 , the target t = 1 and a standard mean squared error (E ![]() 2 ) what is the exact value for ∆wyx ? Assume that the current wyx = −0.5 and that there are no bias. Your answer only needs to be approximate (e.g. 0.06). You should use the chain rule as discussed in the lectures. (7 marks)
2 ) what is the exact value for ∆wyx ? Assume that the current wyx = −0.5 and that there are no bias. Your answer only needs to be approximate (e.g. 0.06). You should use the chain rule as discussed in the lectures. (7 marks)
Question 12 (10 marks)
(a) Consider running k-means on the following datapoints: x1 = (0, −1), x2 = (1, 2), x3 = (1, 1), x4 = (2, 1). Suppose k = 2 and assume that initially x1 and x2 are assigned to cluster 1 and x3 and x4 are assigned to cluster 2. After running one iteration of the k-means algorithm to which cluster are the datapoints assigned? (5 marks)
(b) Give two advantages of using Gaussian mixtures over k-means for clustering and one disadvantage. (5 marks)
Question 13 (10 marks)
(a) Explain what slack variables in support vector machines (SVMs) are. (5 marks)
(b) Is it correct to call SVMs a nonparametric method? Explain your answer. (5 marks)
Question 14 (10 marks)
This question is about hidden Markov models (HMM). Consider a hidden Markov model (HMM) with the following transition matrix and initial state probability estimates:

Rows in A correspond to values of zn and columns to values of zn+1 .
The observations are discrete and can take values X, Y or Z. The model also has the following emission probabilities for the observations:
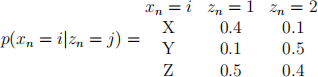
We observe the sequence X, Y.
(a) Use the parameters to compute the probability distribution p(x1 = X, x2 = Y, z2 = 1).
(b) Suppose we want to compute the probability that the next state is z3 = 1. Briefly state explain the first order Markov assumption and how it applies to this computation.
Question 15 (10 marks)
This question is about linear dynamical systems. Suppose you are using a linear dy- namical system to predict a continuous state variable, zn. The model parameters have already been learned using expectation maximisation. For a new time-step, n, you have a Gaussian prior over zn with mean 0 and variance 100. You observe a noisy sensor measurement, xn , then use it to obtain a posterior distribution over zn. The observation xn = 10 with noise variance 1.
(a) What kind of distribution is the posterior distribution over zn and which method can you use to compute it?
(b) Will the posterior mean of zn be closer to 0 or 10 and why?
(c) If we now observe xn+1 and want to update the posterior over zn , what method do we need to use and why?
2023-08-09