AcF 633 - Python Programming for Data Analysis
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
AcF633: Python Programming
Final Individual Project - Resit
AcF 633 - Python Programming for Data Analysis
Final Individual Project - Resit
31st July 2021 noon/12pm to 11st August 2023 noon/12pm (UK time)
This assignment contains one question worth 100 marks.
You are required to submit to Moodle ONE SINGLE .zip folder containing a single Jupyter Notebook .ipynb file OR a single Python script .py file, together with any supporting .csv files (e.g. any input data files. However, do NOT include the ‘IBM 202001.csv.gz’ data file as it is large and may slow down the upload and submission) AND a signed coursework coversheet. The name of this folder should be your student ID or library card number (e.g. 12345678.zip, where 12345678 is your student ID).
submission) AND a signed coursework coversheet. The name of this folder should be your student ID or library card number (e.g. 12345678.zip, where 12345678 is your student ID).
Your submission .zip folder MUST be submitted electronically via Moodle by the 21st August 2023 noon/12pm (UK time). Email submissions will NOT be considered. If you have any issues with uploading and submitting your work to Moodle, please email Carole Holroyd at [email protected] BEFORE the deadline for assistance with your submission.
The following penalties will be applied to all coursework that is submitted after the specified submission date:
Up to 3 days late - deduction of 10 marks
Beyond 3 days late - no marks awarded
Good Luck!
PLEASE NOTE:
The classic Jupyter Notebook, e.g. accessed from Anaconda Navigator, is being upgraded and migrated to Notebook 7. Consequently, you may get a ‘505 Inter- nal Server Error’ when trying to open a notebook .ipynb file in Jupyter Notebook launched from Anaconda Navigator. Thus, it is recommended that you write your answer in a Python script .py file using either Spyder, Visual Studio Code or PyCharm.
However, if you would like to write your answer in a notebook file, you should use an online version of JupyterLab (which integrates Jupyter Notebook) at the following link https://jupyter.org/try-jupyter/lab/?path=notebooks%2FIntro.ipynb, which di- rects you to an online folder. From there, you can create a new notebook, upload and open a pre-written notebook stored in a local folder in your PC, and upload supporting data files to the same online folder. Once your answer notebook is written, you can download it to your local folder by right clicking it on the left panel and selecting Download.
Question 1:
Task 1: High-frequency Finance (Σ = 30 marks)
The data file ‘IBM 202001.csv.gz’ contains the tick-by-tick transaction data for stock IBM in January 2020, with the following information:
stock IBM in January 2020, with the following information:
|
Fields |
Definitions |
|
DATE
TIME M
SYM ROOT EX SIZE PRICE NBO NBB NBOqty NBBqty BuySell |
Date of transaction Time of transaction (seconds since mid-night) Security symbol root Exchange where the transaction was executed Transaction size Transaction price Ask price (National Best Offer) Bid price (National Best Bid) Ask size Bid size Buy/Sell indicator (1 for buys, -1 for sells) |


Import the data file into Python and perform the following tasks:
1.1: Write code to perform the filtering steps below in the following order: (20 marks)
F1: Remove entries that are outside the normal market trading hours, i.e. before 9:30 am or after 4 pm
F2: Remove entries with either transaction price, transaction size, ask price, ask size, bid price or bid size ≤ 0
F3: Remove entries with bid-ask spread (i.e. ask price - bid price) ≤ 0
F4: Aggregate entries that are (a) executed at the same date time (i.e. same ‘DATE’ and ‘TIME M’), (b) executed on the same exchange, and (c) of the same buy/sell indicator, into a single transaction with the median transaction price, median ask price, median bid price, sum transaction size, sum ask size and sum bid size.
the same buy/sell indicator, into a single transaction with the median transaction price, median ask price, median bid price, sum transaction size, sum ask size and sum bid size.
F5: Remove entries for which the bid-ask spread is more that 50 times the median bid-ask spread on each day
F6: Remove entries with the transaction price that is either above the ask price plus the bid-ask spread, or below the bid price minus the bid-ask spread
Create a data frame called summary of the following format that shows the number and proportion of entries removed by each of the above filtering steps. The proportions (in %) are calculated as the number of entries removed divided by the original number of entries (before any filtering).
|
|
F1 |
F2 |
F3 |
F4 |
F5 |
F6 |
|
Number |
|
|
|
|
|
|
|
Proportion |
|
|
|
|
|
|
Here, F1, F2, F3, F4, F5 and F6 are the columns corresponding to the above 6 filtering rules, and Number and Proportion are the row indices of the data frame.
1.2: Using the cleaned data from Task 1.1, write code to compute Realized Volatility (RV) (defined in the lectures) for each trading day in the sample using 5min sampling frequency. The required output is a Pandas series RVsr with index being the unique dates in the sample. (4 marks)
1.3: Using the cleaned data from Task 1.1, write code to compute Two Time Scales Realized Volatility (TTSRV) for each trading day in the sample using the optimal sampling observations suggested by Zhang et al. (2005) (see the lecture slides for more details). The required output is a Pandas series
TTSRVsr with index being the unique dates in the sample. (6 marks)
Task 2: Return-Volatility Modelling (Σ = 30 marks)
Refer back to the csv data file ‘SP100-Feb2023.csv’ that lists the constituents of the S&P100 index as of 8 February 2023 that was investigated in the group projects 1 and 2. Import the data file into Python.
Using your student ID or library card number (e.g. 12345678) as a random seed, draw a random sample of 2 stocks (i.e. tickers) from the S&P100 index excluding stocks ABBV, AVGO, CHTR, DOW, GM, KHC, META, PYPL and TSLA.1 Import daily Adjusted Close (Adj Close) prices for both stocks between 01/01/2009 and 31/12/2022 from Yahoo Finance. Compute the log daily returns (in %) for both stocks and drop days with NaN returns. Perform the following tasks.
2.1: Using data between 01/01/2009 and 31/12/2018 as in-sample data, write code to find the best-fitted ARMA(p,q) model for returns of each stock that minimizes AIC, with p and q no greater than 3. Print the best-fitted ARMA(p,q) output and a statement similar to the following for your stock sample.
Best-fitted ARMA model for AMT: ARMA(2,2) - AIC = 8859.0599
Best-fitted ARMA model for JPM: ARMA(2,2) - AIC = 11093.1840 (7 marks)
2.2: Write code to plot a 2-by-4 subplot figure that includes the following diag- nostics for the best-fitted ARMA model found in Task 2.1:
Row 1: (i) Time series plot of the standardized residuals, (ii) histogram of the standardized residuals, fitted with a kernel density estimate and the density of a standard normal distribution, (iii) ACF of the standardized residuals, and (iv) ACF of the squared standardized residuals.
Row 2: The same subplots for the second stock.
Your figure should look similar to the following for your sample of stocks.

2.3: Use the same in-sample data as in Task 2.1, write code to find the best- fitted AR(p)-GARCH(p* , q* ) model with Student’s t errors for returns of each stock that minimizes AIC, where p is fixed at the AR lag order found in Task 2.1, and p* and q* are no greater than 3. Print the best-fitted AR(p)- GARCH(p* , q* ) output and a statement similar to the following for your stock sample.
Best-fitted AR(p)-GARCH(p*,q*) model for AMT: AR(2)-GARCH(1,3) - AIC = 8321.5863
Best-fitted AR(p)-GARCH(p*,q*) model for JPM: AR(2)-GARCH(1,1) - AIC
= 9336.2033 (8 marks)
2.4: Write code to plot a 2-by-4 subplot figure that includes the following diag-
nostics for the best-fitted AR-GARCH model found in Task 2.3:
Row 1: (i) Time series plot of the standardized residuals, (ii) histogram of the standardized residuals, fitted with a kernel density estimate and the density of a fitted Student t distribution, (iii) ACF of the standardized residuals, and (iv) ACF of the squared standardized residuals.
Row 2: The same subplots for the second stock.
Your figure should look similar to the following for your sample of stocks.
Comment on what you observe from the plots. (5 marks)

2.5: Write code to plot a 1-by-2 subplot figure that shows the fitted conditional volatility implied by the best-fitted AR(p)-GARCH(p* , q* ) model found in Task 2.3 against that implied by the best-fitted ARMA(p,q) model found in Task 2.1 for each stock in your sample. Your figure should look similar to the following.
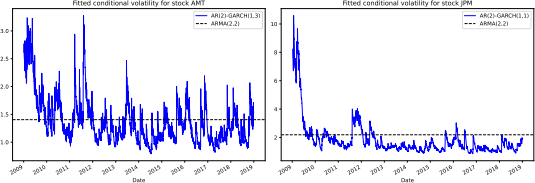
(5 marks)
Task 3: Return-Volatility Forecasting (Σ = 20 marks)
3.1: Use data between 01/01/2019 and 31/12/2022 as out-of-sample data, write code to compute one-step forecasts, together with 95% confidence interval (CI), for the returns of each stock using the respective best-fitted ARMA(p,q) model found in Task 2.1. You should extend the in-sample data by one obser- vation each time it becomes available and apply the fitted ARMA(p,q) model to the extended sample to produce one-step forecasts. Do NOT refit the ARMA(p,q) model for each extending window.2 For each stock, the forecast output is a data frame with 3 columns f, fl and fu corresponding to the
one-step forecasts, 95% CI lower bounds, and 95% CI upper bounds. (6 marks)
3.2: Write code to plot a 1-by-2 subplot figure showing the one-step return forecasts found in Task 3.1 against the true values during the out-of-sample period for both stocks in your sample. Also show the 95% confidence interval of the return forecasts. Your figure should look similar to the following.
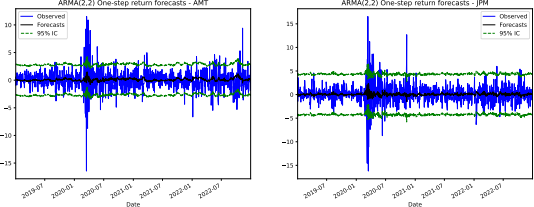
(3 marks)
3.3: Write code to produce one-step analytic forecasts, together with 95% confidence interval, for the returns of each stock using respective best-fitted AR(p)-GARCH(p* , q* ) model found in Task 2.3. For each stock, the forecast output is a data frame with 3 columns f, fl and fu corresponding to the
one-step forecasts, 95% CI lower bounds, and 95% CI upper bounds. (4 marks)
3.4: Write code to plot a 1-by-2 subplot figure showing the one-step return forecasts found in Task 3.3 against the true values during the out-of-sample period for both stocks in your sample. Also show the 95% confidence interval of the return forecasts. Your figure should look similar to the following.
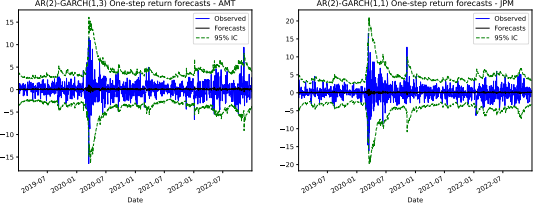
(3 marks)
3.5: A return forecast is considered ‘reasonably accurate’ if the observed return falls within the 95% CI of the forecast. Compute the proportion of ‘reasonably accurate’ return forecasts implied by the best-fitted ARMA(p,q) and AR(p)- GARCH(p* ,q* ) models for each stock in your sample. Print a statement similar to the following for your stock sample.
Proportion of reasonably accurate forecasts for AMT: ARMA(2,2): 87.80%; AR(2)-GARCH(1,3): 97.72%
Proportion of reasonably accurate forecasts for JPM: ARMA(2,2): 94.15%;
AR(2)-GARCH(1,1): 98.12% (4 marks)
Task 4: (Σ = 20 marks)
These marks will go to programs that are well structured, intuitive to use (i.e. provide sufficient comments for me to follow and are straightforward for me to run your code), generalisable (i.e. they can be applied to different sets of stocks (2 or more)) and elegant (i.e. code is neat and shows some degree of efficiency).
2023-08-08