CIS 550: Database and Information Systems Practice Midterm 2
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
CIS 550: Database and Information Systems
Practice Midterm 2 (with answers)
Part 1. (16 points, General)
Select the best answer for each of the following questions.
1. Which of the following is more true of a relational database than of MongoDB?
a. Flexible schema
b. Strong consistency guarantees
c. Distributed query processing
d. Schema parsing overhead.
ANSWER: b
RDBMS have stronger consistency guarantees and join is one of the algebraic operators. The schema is fixed, so it is not flexible and there is no parsing overhead. It is also harder to parallelize the operation.
2. Which of the following is true about indexes?
a. A search key must also be a candidate key
b. Every sparse index is clustered.
c. Indexes do not impose additional overhead for record updates.
d. Every search key in the index must be the search key of some record in the data file.
ANSWER: b
Indices must be updated as the tuples in the indexed relation are updated, and therefore create overhead.
It is possible for a search key to appear in the index but not the file, e.g. a B+ tree where the tuple was deleted but the index was not updated.
3. Which of the following is true about B+ trees?
a. Each key value in the index must appear in some data entry.
b. The length of the path from the root to a data entry block is the same for every data entry block.
c. If the order of the tree is 50, then each node in the index must contain at least 50 pointers.
d. The height of the tree is constant, and does not change over time.
ANSWER: b
A is False, since when the minimum data entry is deleted on a block, the index does not have to be changed. C is False, since the root may contain only 2 entries (pointers).
4. Which of the following is true about Block Nested Loop joins, where B is the number of buffered pages?
a. It is always better than the naive Simple Nested Loop join
b. The cost is the same no matter which relation is used as outer
c. B-2 pages should be used for the larger relation
d. The cost increases as B increases
ANSWER: a
A Simple Nested Loop join does a scan of the inner relation per tuple of the outer relation, and a Page Oriented Nested Loop join does a scan of the inner relation per page of the outer relation. These are both always worse than doing a scan for a larger “chunk” of the outer relation, which is however much can fit in memory (B-2). As B increases, there are fewer “chunks” and the cost decreases.
The cost of any flavor of nested loop join is better if the smaller relation is used as outer.
5. When measuring the cost of a join implementation (e.g. Block Nested Loop Join, Merge Join, Hash Join) what is typically being counted?
a. The number of comparisons performed in main memory
b. The estimated time it takes to retrieve all pages accessed, including the seek time, rotational delay and transfer time
c. The number of pages moved between main memory and disk
d. All of the above
ANSWER: c
The cost is typically calculated by counting only the I/O cost, i.e. the estimated number of pages moved between main memory and disk. A refinement of this will also consider the number of comparisons performed in main memory (e.g. the hash join will build a hash index in memory using a secondary hash function to speed up comparisons). Typically, the seek time and rotational delay are not considered.
6. Which of the following are true about the three alternatives for data entries in an index over A in a relation R(A, B, C, D)?
a. Only Alternative 1 can be used for a Hash index; all alternatives can be used for B+ trees.
b. The number of I/Os required to access a tuple in R matching the search key (e.g. “B=2”) using the index is the same for all three alternatives.
c. The number of data entry pages needed for Alternative 1 is larger than the number for Alternative 2.
ANSWER: c
A is incorrect since the choice of alternative for data entries is orthogonal to the indexing technique.
B is incorrect since in Alternative 1 the data entry is the data record, whereas in Alternatives 2 and 3 the RID must be followed to find the data record (1 more block access).
C is correct since entire tuples are being stored at the data entry
7. Suppose you have a transaction T running in access mode “SET TRANSACTION READ/WRITE”. Which isolation level should you specify for T if you wish to prevent unrepeatable reads?
a. READ UNCOMMITTED
b. READ COMMITTED
c. REPEATABLE READ or SERIALIZABLE
ANSWER: c
REPEATABLE READ prevents dirty reads as well as unrepeatable reads; SERIALIZABLE additionally prevents “phantoms”.
8. Suppose that two transactions are running simultaneously:
T1: R(X);
T2: R(X);
Which isolation levels should the user specify for T1 and T2 so as to maximize concurrency?
a. READ UNCOMMITTED for T1, READ COMMITTED for T2
b. READ COMMITTED for T1, READ UNCOMMITTED for T2
c. REPEATABLE READ for T1, READ UNCOMMITTED for T2
ANSWER: b
A is incorrect since T1 is a READ/WRITE transaction, and cannot therefore use READ UNCOMMITTED.
C is incorrect since READ COMMITTED allows more concurrency than REPEATABLE READ as it releases READ locks as soon as they are not needed rather than holding them until the end of the transaction.
Part 2: Transactions (14 points)
Consider the following two transactions:
T10: R10(A), R10(B), W10(B)
T11: R11(B), R11(A), W11(A)
1. (5 points)
Show an interleaved (non-serial) execution of T10 and T11 that is not serializable. Justify why the execution is not serializable.
Answer:
T10: READ(A), T11: READ(B), T10: READ(B), T11: READ(A), T10: WRITE(B), T11: WRITE(A)
The precedence graph for this schedule is T10 → T11 → T10. Since it contains a cycle, the execution is not serializable.
2. (4 points)
Add lock acquisition and release instructions (using shared and exclusive locks) to transactions T10 and T11 so that they are well-formed and two-phased. Write this representation of each of these two transactions below, using SLOCK and XLOCK to indicate lock acquisitions and REL to indicate lock releases. Be sure to indicate which transaction is performing the lock acquisition or release, e.g. as XLOCK10(B) for an exclusive lock acquisition by T10 on B.
Answer:
T10 : SLOCK(A), READ(A), XLOCK(B), READ(B), WRITE(B) REL(A, B)
T11 : SLOCK(B), READ(B), XLOCK(A), READ(A), WRITE(A) REL(A, B)
3. (5 points)
Using your previous answer (the well-formed, two-phased versions of T10 and T11), show a partial execution that results in deadlock. Justify why the partial execution is deadlocked. Again, be sure to indicate which transaction is performing the lock acquisition or release, e.g. as XLOCK10(B) for an exclusive lock acquisition by T10 on B.
Answer:
T10:SLOCK(A), T10:READ(A), T11:SLOCK(B), T11:READ(B),
Part 3. (14 points) B+ trees
Consider the following B+ tree. In this tree, as well as those in (a), (b) and (c), you should assume that the leaves of the tree are linked and that you can navigate between them. Nodes are identified by the ids in red (e.g. N1… N5, A1...A6, B1...B5, and C1...C5). You can use the node ids in your answers to the following questions.
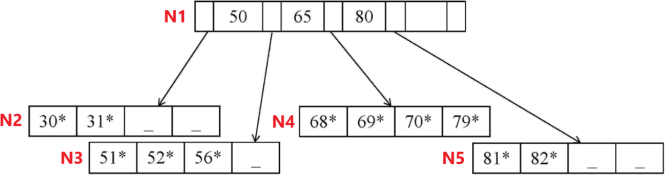
You are asked to insert the record with key value 75, and see three possible options, pictured below:
(a) split the leaf node N4 containing 68*, 69*, 70* and 79*;
(b) make room on N4 for 75* by pushing 68* to the leaf N3 containing 51*, 52* and 56* ; or
(c) make room on N4 for 75* by pushing 79* to the leaf N5 containing 81*, 82*.
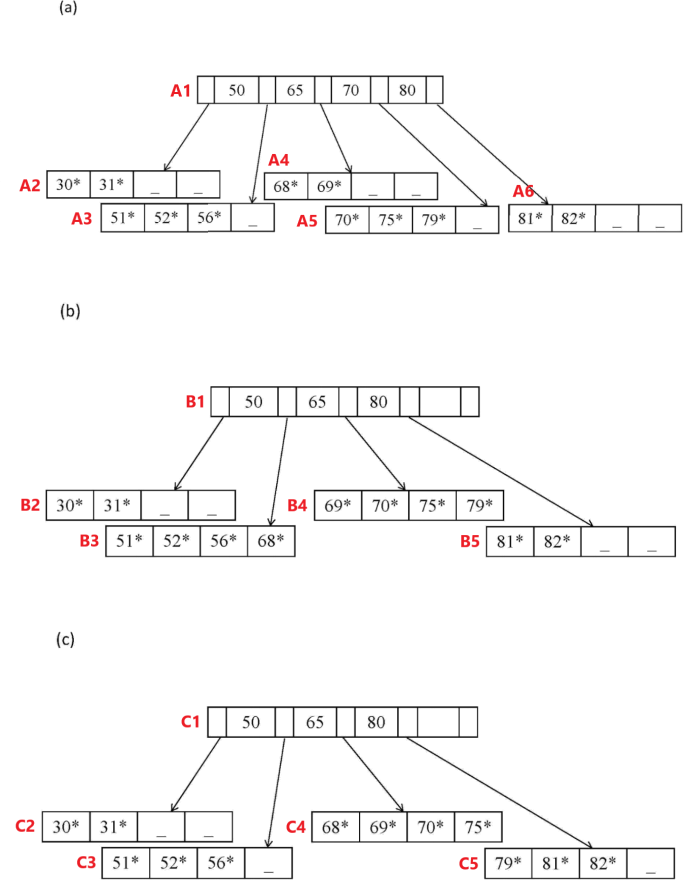
1. (4 points)
Your friend points out that you made a mistake in each of the resulting trees (b) and (c). Briefly explain what rules of B+ trees each mistake violates, and how it can be corrected.
ANSWER:
For (b): The key value in the root B1 containing 65 needs to be modified to 69.
For (c): The key value in the root C1 containing 80 needs to be modified to 79.
Otherwise it does not preserve the semantics of a B+ tree, where each (key,ptr) pair must preserve the fact that the subtree pointed at by ptr must contain values less than the key.
2. (2 points)
Assuming that data will be inserted at a much higher rate than it will be deleted, which option is the best one, and why?
ANSWER:
Option (1), since eventually the node will probably need to be split anyway. (This is the option taught in class.)
3. (4 points)
Using the original tree, describe briefly in English the result of deleting the record with key value 31. You may use the node ids N1, …, N5 to reference the affected nodes.
ANSWER: N2 should borrow 51* from its sibling N3. This will change the key value in the root, N1, from 50 to 52.
Another option is to move 30* to N3, and delete N2. The root is also changed to delete the pointer to N2 (and 50), so that it becomes [(
However, since trees are expected to grow this is not a good option (deduct one point for the option of moving 30* to N3 and deleting N2).
4. (4 points)
Using the original tree, describe briefly in English the result of inserting a record with key value 79.5. As before, you may use the node ids N1, …, N5 to reference the affected nodes.
ANSWER:
Must insert in the node N4, which is full. It must be split, introducing a new node N6, and the new entry must be inserted into the root N1. Assuming that N4 contains [68*, 69*] and N6 contains [70*, 79*, 79.5*], N1 now becomes [(
If you split so that N4 contains [68*, 69*, 70*] and N6 contains [79*, 79.5*], then N1 becomes [(
Part 4. (10 points) Using indexes
Consider a table Person(SSN, Name, Age) with a B+ tree index on (Name, Age), i.e. primarily on Name and secondarily on Age.
Suppose the following query is executed:
SELECT Age
FROM Person
WHERE Name=”David” AND Age>50;
1. (2 points)
Is the index useful for this query? Explain your answer.
Yes, it is useful because there must be a term of form attr
2. (3 points)
Suppose that Alternative 2 is used for data entries at the leaves of the index. Can the query be executed without retrieving the data records? Explain your answer.
Yes, because the index contains (Age, Name) and the query returns just the Age.
3. (2 points)
Suppose the index on (Name, Age) is a hash index. Is the hash index useful for the query (repeated below)? Explain your answer.
SELECT Age
FROM Person
WHERE Name=”David” AND Age>50;
No, because there must be a term of form attr=val for each attribute in the index’s search key; “Age>50” is not of this form.
4. (3 points)
Suppose there is a hash index on (Name) using Alternative 1 in Person(SSN, Name, Age). Explain how the hash index would be used to answer the query (repeated below).
SELECT Age
FROM Person
WHERE Name=”David” AND Age>50;
The index would be used to find the bucket containing people named “David”; note that the data entries are the same as the data records since Alternative 1 is being used. Each data record in the bucket would be scanned, and those where Age>50 would be returned.
Part 5. (15 points) MongoDB
Suppose we have a collection called movies whose documents have a structure similar to the following:
myMovie={
_id: 1,
title: “Pulp Fiction”,
year: 1994,
score: 94,
director: {last: “Tarantino”, first: “Quentin”},
actors: [{last: “Travolta”, first: “John”}, {last: “Thurman”, first: “Uma”}, ... ]
}
db.movies.insert(myMovie)
1. (2 points)
Would myMovie be returned by the following query?
db.movies.find({“director”: {“last“: “Tarantino”}})
SOLUTION:
No, since the director value in myMovie also has a first name.
2. (4 points)
Write a query which returns the title of every movie from 1994 in which John Travolta acted. Do not return _id.
Result schema: {title}
SOLUTION:
db.movies.find({year: 1994, actors: {last: “Travolta”, first: “John”}}, {title:1, _id:0})
3. (4 points)
Write an aggregation query (db.movies.aggregate(...)) to find the number of movies appearing in each year.
Result schema: {_id, numMovies} where _id has the value of the year.
SOLUTION:
db.movies.aggregate({$group: {_id: “$year”, numMovies: {$sum:1}}})
4. (5 points)
Write a MapReduce function which returns for each year the total number of movies, the total number of actors, and the average number of actors for a movie in the movies collection. Give your answer by filling in the map reduce template code provided below.
Result schema: {countMovies, countActors, avg}
var mapFunction = function() {
}
var reduceFunction = function( keyYear, vals) {
}
var finalizeFunction = function ( keyYear, reducedVal) {
}
db.movies.mapReduce(mapFunction, reduceFunction, {
out: {inline: 1},
finalize: finalizeFunction
});
SOLUTION:
var mapFunction = function () {
var value = {countMovies: 1, countActors: this.actors.length};
emit(this.year, value);
}
var reduceFunction = function(keyYear, vals) {
var reducedVal = {countMovies: 0, countActors:0};
for (var idx = 0; idx < vals.length; idx++) {
reducedVal.countMovies += vals[idx].countMovies;
reducedVal.countActors += vals[idx].countActors;
}
return reducedVal;
}
var finalizeFunction = function(keyYear, reducedVal) {
reducedVal.avg = reducedVal.countActors / reducedVal.countMovies;
return reducedVal;
}
db.movies.mapReduce(mapFunction, reduceFunction, {
out: {inline:1},
finalize: finalizeFunction
});
Part 6. (16 points) Neo4j
Consider the Neo4j instance created by the following Cypher code:
CREATE (mary:Person {name:"Mary", age:20})
-[:WORKED_WITH]->(neo:Database {name:"Neo4j" }),
(mary)-[:WORKED_WITH]->(sql:Database {name:"Sql"}),
(mary)-[:WORKED_WITH]->(mongo:Database {name:"Mongo"}),
(amanda:Person {name:"Amanda", age:30})-[:WORKED_WITH]->(neo),
(amanda)-[:WORKED_WITH]->(mongo),
(johan:Person {name:"Johan", age:18})-[:WORKED_WITH]->(neo),
(johan)-[:WORKED_WITH]->(mongo),
(julia:Person {name:"Julia", age:25})-[:WORKED_WITH]->(sql),
(mary)-[:KNOWS]->(johan), (johan)-[:KNOWS]->(mary),
(mary)-[:KNOWS]->(julia),
(julia)-[:KNOWS]->(anna:Person {name:"Anna", age: 26})
The instance created by the above CREATE statement can be visualized as follows:
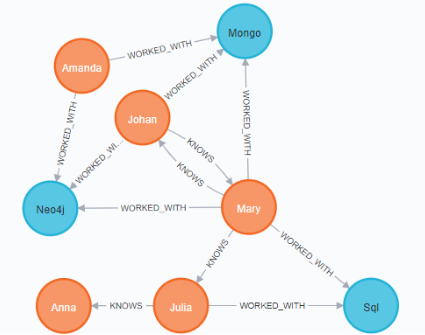
Write Cypher queries for each of the following.
1. (5 points)
Return the names of people whose age is greater than 20.
Result schema: (Name)
SOLUTION:
MATCH (person:Person)
WHERE person.age > 20
RETURN person.name;
2. (5 points)
Return the number of people that “mary” knows (i.e. the person with name “Mary”).
Result schema: (Count)
SOLUTION:
MATCH p = (mary:Person {name:"Mary"})-[:KNOWS]->(:Person)
RETURN count(p) AS Count;
3. (6 points)
Return pairs of people who can work with at least one database that is the same (i.e. a node with label “Database”) and who know each other. The KNOWS relationship must be symmetric. You should return a pair once, e.g. if (X,Y) is in the result then (Y, X) should not be.
Result schema: (Name1, Name2).
SOLUTION:
MATCH (p1:Person)-[:WORKED_WITH]->(:Database)<-[:WORKED_WITH]-(p2:Person)
WHERE p1.name < p2.name and (p1)-[:KNOWS]->(p2) and (p1)<-[:KNOWS]-(p2)
RETURN p1.name AS Name1, p2.name AS Name2
Part 7. (15 points) Optimization
Consider the following schema:
Person(PName, State)
Votes(PName,CName)
Candidate(CName, Position)
Where the key of each relation is in bold.
1. (3 points)
For each of the following join orders of Person, Votes and Candidate say whether or not it would be considered by the System R query optimizer. Briefly explain your answer (1 sentence).
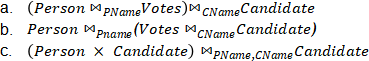
ANSWER:
a.Yes, it is left deep.
b.No, it is not left deep.
c.No, there are no join attributes between Person and Candidate
2. (6 points)
You are given the following information:
● 52 buffers
● The Person relation fits on 5,000 pages and is sorted on PName.
● The Votes relation fits on 2,000 pages and is not sorted on any field.
What is the optimal cost in terms of page I/Os of executing the following query using Block Nested Loop join? State which relation is the outer and which is inner and explain your answer.
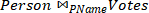
ANSWER:
Votes is smaller, so use it as outer. The cost is 2000+(2000/50)5000=
2000+(40*5000)=202,000
Using Person as outer: 5000+(5000/50)2000= 205,000
3. (6 points)
Recall:
● 52 buffers
● The Person relation fits on 5,000 pages and is sorted on PName.
● The Votes relation fits on 2,000 pages and is not sorted on any field.
What is the cost in terms of page I/Os of executing the following query (repeated below) using Merge Join? Explain your answer.
![]()
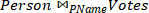
Hint: 522=2,704
ANSWER:
Since Votes is not sorted on PName, it must be sorted. Since sqrt(2000)< 52, this can be done in 2 passes, for a cost of 2*2000*2=8000 page I/Os. Merging Person and Votes can then be done in one pass over each, for an additional cost of 5000+2000=7000. So the total cost is 7000+8000=15,000 page I/Os.
2023-08-04