STATS 102A HW2
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
STATS 102A
HW2
Due July 18
General Notes
• You will submit a minimum of three files, the core files must conform to the following naming conventions (including capitalization and underscores). 123456789 is a placeholder, please replace these nine digits with your nine-digit Bruin ID. The files you must submit are:
1. 123456789 stats102a hw1.R: An R script file containing all of the functions you wrote for the homework. The first line of your .Rmd file, after loading libraries, should be sourcing this script file.
2. 123456789 stats102a hw1.Rmd: Your markdown file which generates the output file of your submission.
3. 123456789 stats102a hw1.html/pdf : Your output file, either a PDF or an HTML file depending on the output you choose to generate.
4. included image files: You may name these what you choose, but you must include all of the image files you generated for your structured flowcharts, otherwise your file will not knit. One way to attach an image file is to use .
5. Please place all of your files into a single folder named 123456789 stats102a hw2 and compress the folder into 123456789 stats102a hw2.zip.
If you fail to submit any of the required core files you will receive ZERO points for the assignment. If you submit any files which do not conform to the specified naming convention, you will receive half credit for the assignment.
• Your .Rmd file must be knittable. If your .Rmd file does not knit in graders’ computer, you will receive at most half credit for the assignment.
The two most common reason files fail to knit are because of workspace/directory structure issues and because of missing include files. To remedy the first, ensure all of the file paths in your document are relative paths pointing at the current working directory. To remedy the second, simply make sure you upload any and all files you source or include in your .Rmd file.
• Your coding should adhere to the tidyverse style guide: https://style.tidyverse.org/.
my function ¡- function(x, y, ...){
#A short description of the function
#Args:
#x: Variable type and dimension
#y: Variable type and dimension
#Return:
#Variable type and dimension
Your codes begin here
}
NOTE: Everything you need to do this assignment is here, in your class notes, or was covered in discussion or lecture.
• DO NOT look for solutions online.
• DO NOT collaborate with anyone inside (or outside) of this class.
• DO NOT print out the whole dataset in the markdown.
• Work INDEPENDENTLY on this assignment.
• EVERYTHING you submit MUST be 100% your, original, work product. Any student suspected of plagiarizing, in whole or in part, any portion of this assignment, will be immediately referred to the Dean of Student’s office without warning.
1: Teacher’s Gradebook
The formatting takes 15% of this homework grade. The efficiency, accuracy, and robustness of your functions account for 60%. The total is 75% for this question. If your functions violent any instructions of this assignment, the functions will not be graded.
Requirements:
1. Draw flowcharts (or algorithms) of the main functions sufficiently complete, clear, and concise enough to enable a person to accurately implement the functions in any programming languages they are adept with using.
2. Write the functions which accurately implements the algorithms.
3. Include the error-handling to ensure your functions work properly.
Note: The requirements apply to your messy_impute() and tidy_impute() functions only.
One scenario which naturally creates non-tidy data is a teacher’s gradebook. Table 1 shows an example with five homework and five quizzes.

• Each row of the gradebook should contain all measurements for a student.
• Each column should contain scores for one assignment.
• The last column should be “Quiz 5.”
The simulated gradebook should contain the grades for 100 students and scores (out of 100) for 5 homework and 5 quizzes. Set the seed for simulating your data with your UID.
(b) Write R code in R markdown file to randomly replace 10% of Homework 4 and Quiz 4 by NA respectively, and then use is.na() in conjunction with sum() to show your results.
(c) Write a function messy_impute() that imputes missing values in the gradebook. Please also present your algorithm or flowchart to answer this question in the R markdown file.
Note:
• Imputation is the process of replacing missing values by estimated values. The simplest (far from preferred) method to impute values is to replace missing values by the most typical value, say the mean.
• Assume the format of the gradebook is fixed (five homework and five quizzes), but NA values may occur in any assignments except for UID.
• The messy_impute() function should have at least three arguments and ...:
– A tibble contains the gradebook as specified in the example. However, the number of rows and where NA values occur may be different while grading.
– A center argument should be a character object indicating the impute functions (mean or median). The default center is “mean”.
– A margin argument should be an integer (1 or 2) indicating either the function imputes the missing values by row/student (1) or by column/assignment (2). If choosing by column, the function should process homework and quizzes separately.
• The function should return the imputed tibble.
• Toy example with three homework assignments : Suppose the input data frame contains the data as follow.
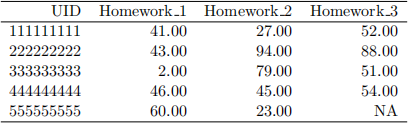
To impute the NA value by column with mean, we compute 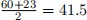 to replace the NA. If do it by row, the function should compute
to replace the NA. If do it by row, the function should compute 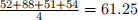 to replace the NA.
to replace the NA.
(d) Select two students missing Homework 4 and two students missing Quiz 4. Please use these cases to demonstrate your function in the R markdown file. Here are some suggested cases but not limited to while grading.
• messy impute(gradebook, “mean”, 1)
• messy impute(gradebook, “median”, 2)
• messy impute(gradebook, “mean”, 1, trim = 0.25)
(e) Write R code using the main function in the tidyr package to convert the gradebook into the tidy format. Name this object gradebook_tidy. You may directly write code in the R markdown file.
(f) Write a function tidy_impute() that imputes missing values in gradebook_tidy object. The tidy_impute() function should have the same arguments as in the messy_impute() function. You should return an imputed gradebook_tidy object. Please also present your algorithm or flowchart to answer this question in the R markdown file.
Note: Don’t convert gradebook_tidy object to be a messy format or reuse your messy_impute() in any steps of your tidy_impute().
(g) Please use the cases you select from (d) to demonstrate your function in the R markdown file.
2: Short Answers
The formatting takes 10% of your homework grade. The accuracy takes 15% of your grade. The total is 25% for this question.
(a) Please find three examples in which data might naturally be presented in a messy (non-tidy) way. For each example, include the context, observations, and variables that would be recorded. Showcase a small sample, say 10 observations, for each example. You may search online for context, but you MUST cite your sources. Please don’t make up data on your own.
(b) For each of the three examples in (a), describe how the data might be better presented in a tidy way. Please use tidyverse functions to reorganize the small sample datasets in (a) into tidy format.
2023-07-31