COMP3308/3608 Introduction to Artificial Intelligenece semester 1, 2023
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
COMP3308/3608 Introduction to Artificial Intelligenece
(regular and advanced)
semester 1, 2023
Sample exam questions
In addition to these questions please also see on Canvas:
Search: Weeks_2-3_Practice.pdf (prepared by Jessica)
Bayesian networks: BN_practice_questions.pdf (prepared by Jessica)
Question 1. (Type 2 - problem solving/calculation)
In the tree below the step costs are shown along the edges and the h values are shown next to each node. The goal nodes are double-circled: F and D.
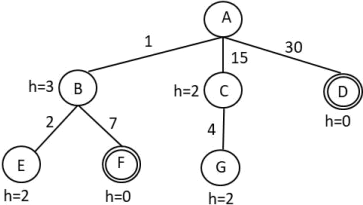
Write down the order in which nodes are expanded using:
a) Breadth-first search
b) Depth-first search
c) Uniform cost search
d) Iterative deepening search
e) Greedy search
f) A*
In case of ties, expand the nodes in alphabetical order.
Question 2. (Type 1 - short answers)
Answer briefly and concisely:
a) A* uses admissible heuristics. What happens if we use anon-admissible one? Is it still useful to use A* with anon-admissible heuristic?
b) What is the advantage of choosing a dominant heuristic in A* search?
c) What is the main advantage of hill climbing search over A* search?
Question 3. (Type 2 - problem solving/calculation)
Consider the following game in which the evaluation function values for player MAX are shown at the leaf nodes. MAX is the maximizing player and MIN is the minimizing player. The first player is MAX.
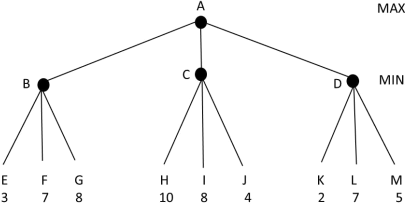
a) What will be the backed-up value of the root node computed by theminimax algorithm?
b) Which move should MAX choose based on theminimax algorithm - to node B, C or D?
c) Assume that we now use the alpha-beta algorithm. List all branches that will be pruned, e.g. AB etc. Assume that the children are visited left-to-right (as usual).
Question 4. (Type 1 - short answers)
Answer briefly and concisely:
a) The 1R algorithm generates a set of rules. What do these rules test?
b) Gain ratio is a modification of Gain used in decision trees. What is its advantage?
c) Propose two strategies for dealing with missing attribute values in learning algorithms. d) Why do we need to normalize the attribute values in the k-nearest-neighbor algorithm?
e) What is the main limitation of the perceptrons?
f) Describe an early stopping method used in the backpropagation algorithm to prevent overfitting.
g) The problem of finding a decision boundary in support vector machine can be formulated as an optimisation problem using Lagrange multipliers. What are we maximizing?
h) In linear support vector machines, we use dot products both during training and
during classification of a new example. What vectors are these products of?
During training:
During classification of a new example:
Question 5. (Type 2 - problem solving/calculation)
Consider the task of learning to classify mushrooms as safe or poisonous based on the following four features: stem = {short, long}, bell = {rounded, flat}, texture = {plain, spots, bumpy, ruffles} and number = {single, multiple}.
The training data consists of the following 10 examples:
Safe:

Poisonous:
These examples are also shown in the table below:

a) Use Naïve Bayes to predict the class of the following new example: stem=long, bell=flat, texture=spots, number=single. Show your calculations. 
a) How would 3-Nearest Neighbor using the Hamming distance classify the same example as above? Explain your answer. (Hint: The Hamming distance is the number of different feature values).
b) Consider building a decision tree. Calculate the information gain for texture and number and briefly show your calculations Which one of these two features will be selected and why?
You may use this table:
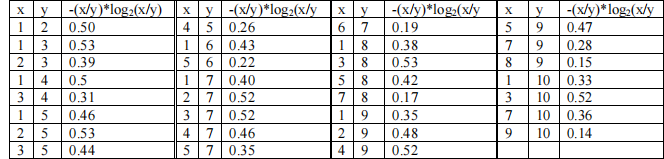
d) Consider a single perceptron for this task. What is the number of inputs? What is the dimensionality of the weight space? Briefly explain your answer.
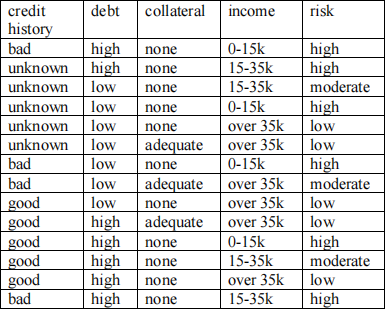
Question 6. Given the training data in the table below where credit history, debt, collateral and income are attributes and risk is the class, predict the class of the following new example using the 1R algorithm: credit history=unknown, debt=low, collateral=none, income=15-35K.
Show your calculations.
Question 7. (Type 2 - problem solving/calculation)
Use the k-means algorithm to cluster the following one dimensional examples into 2 clusters: 2, 5, 10, 12, 3, 20, 31, 11, 24. Suppose that the initial seeds are 2 and 5. The convergence criterion is met when either there is no change between the clusters in two successive epochs or when the number of epochs has reached 5.
Show the final clusters. How many epochs were needed for convergence? There is no need to show your calculations.
Question 8. (Type 1 - short answers)
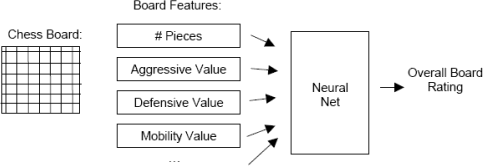
You task is to develop a computer program to rate chess board positions. You got an expert chessplayer to rate 100 different chessboards and then use this data to train a backpropagation neural network, using board features as the ones shown in the figure below.
Select the correct answer (“Yes” or “No”) in the questions below. Select “Yes” for all issues that could, in principle, limit your ability to develop the best possible chess program using
this method. Select “No” for all issues that could not. Briefly explain your answer.
a) The backpropagation network may be susceptible to overfitting, since you tested its performance on the training data instead of using cross validation.
Yes No
Explanation:
b) The backpropagation neural network can only distinguish between boards that are completely good or completely bad.
Yes No
Explanation:
c) The backpropagation network will converge to the global minimum.
Yes No
Explanation:
d) You should have used higher learning rate and momentum to guarantee convergence to the global minimum.
Yes No
Explanation:
e) The topology of your neural net might not be adequate to capture the expertise of the human expert.
Yes No
Explanation:
Question 9. (Type 2 - problem solving/calculation)
In the figure below, the circles are training examples and the squares are test examples,i.e. we are using the circles to predict the squares. Two algorithms are used: 1-Nearest Neighbour and 3-Nearest Neighbour.

We are given the following results about the squares:
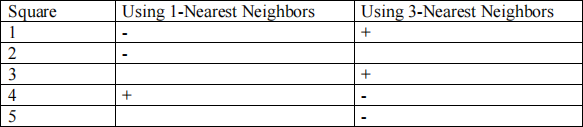
What will be the class of the following examples? Write +, - or U for cannot be determined.
1) Circle L:
2) Circle I:
3) Circle H:
4) Circle E:
5) Circle K:
6) Circle C:
7) Square 6 using 1-Nearest Neighbour:
8) Square 6 using 3-Nearest Neighbour:
9) Square 3 using 1-Nearest Neighbour?
10) Square 5 using 1-Nearest Neighbour?
2023-07-19