COMP/ENGN 4528 Computer Vision Semester 1, 2023 Final Exam
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
COMP/ENGN 4528 Computer Vision
Semester 1, 2023
Final Exam
• Section 1. Image Processing and Local Features (32 marks)
1. (4 marks, easy) What is the effect of applying each of the following filters to a given image, respectively? Very briefly explain your answer.
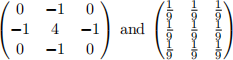
2. An image matrix I is defined as in Fig.

1) (6 marks, easy) For image I above, compute its gradient in both horizontal and vertical directions (I北 and Iy) for three pixel locations A, B and C marked in Fig. 2, using the Sobel filter. Here, use 0 for padding. Padding type is “same”, where the output and input should be the same size. Sobel filters for correlation are provided below, where G北 is for x direction, and Gy is used for y direction. (Convolution and correlation are the same in our course.)
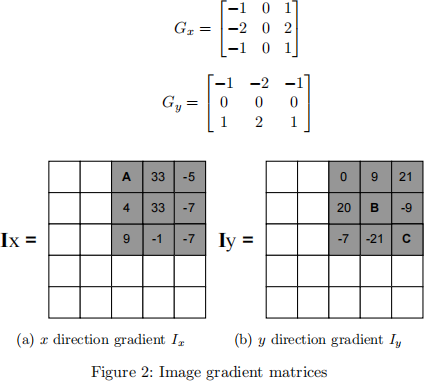
2) (4 marks, medium) Compute the second-order moments matrix of gradients M for the 3 by 3 window highlighted in the above gradient matrices.
3) (4 marks, medium) Compute the cornerness response R for the second-order moments matrix of gradients M for the above window, with empirical constant k = 0.05.
4) (2 marks, easy) What do you think we have in the above window? A corner? An edge? Or a flat region? Explain your answer.
3. We have the following operator that takes I(x,y) as input and outputs g(x,y). This operator, when discretized, can be used to process an image I(x,y) into a new image g(x,y).
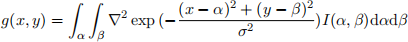
where 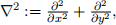 and σ is a hyper-parameter.
and σ is a hyper-parameter.
1) (2 marks, hard) Give the general name for this type of mathematical operation, and the main purpose that it serves in image processing.
2) (2 marks, easy) What image structures (or features) are expected at places (x, y) in the image I(x, y) where the operator output g(x, y) undergoes zero-crossings g(x,y) = 0? (zero- crossings are where the curve goes from positive to negative or from negative to positive)
3) (3 marks, easy-medium) How does σ affect image processing results? That is, if you increase its value, would there be more or fewer points (x,y) where g(x,y) = 0?
4. (5 marks, medium) RANSAC-based fundamental matrix estimation. Assume a user does not have a good estimate of the inlier rate of the observed data of 8000 pixel correspondences cross two views. Experimentally a good fundamental matrix is obtained after sampling for 108 times with probability of 99% to get the correct fundamental matrix. Here we would like to use the minimal number of pixel correspondences per iteration to compute the fundamental matrix. Please write down your derivation in detail about what the inlier rate is.
• Section 2. Deep Learning (34 marks)
1. Given a convolutional neural network 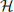 (x), which consists of a convolution layer and a linear layer (dot product). Both layers contain only weight parameters (no bias parameters).
(x), which consists of a convolution layer and a linear layer (dot product). Both layers contain only weight parameters (no bias parameters).
The parameters of the network are provided as follows. Vector k is the kernel used for convolution (convolution and correlation are the same in our course); vector w is used in the linear layer:
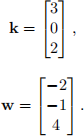
Given an input vector x, the output from the neural network can be calculated as:
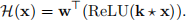
Note that the ⋆ denotes a neural network 1D convolutional layer (cross-correlation operation) using k as the filter kernel applied to the input x. In this question, the stride is 1 and no padding is used for the convolutional layer.
You are provided with a training sample (x,y), where x is the input vector and y is the corre- sponding ground truth:
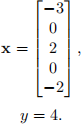
Answer the questions below and show detailed calculations.
1) (5 marks, easy-medium) Calculate the forward pass output from the convolutional neural network using data provided above.
2) (5 marks, medium-hard) Calculate the partial derivative of loss L with respect to the con- volutional layer weight k and the linear layer weight w, using the mean squared error loss, defined as

3) (5 marks, hard) Hence or otherwise, calculate one step of gradient descent for optimising model parameters with a learning rate of 0.01. Show the updated weight vectors k\ and w\.
2. (3 marks, easy-medium) In Fig. 3, feature map at layer L+2 is produced by dilated convolution (left) on feature map at Layer L+1; feature map at layer L+1 is produced by the same dilated convolution (left) on the feature map at Layer L. For a neuron in layer L+2, compute its receptive field size at Layer L. Just giving a result does not have marks. Please show necessary reasoning process, where partial marks will apply.
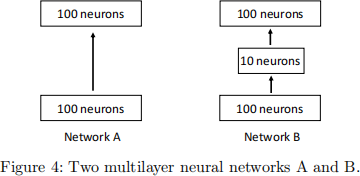
3. Two multilayer neural networks are shown in Fig. 4. For simplicity, the output layer is not drawn.
1) (3 marks, easy) What can be the advantage of Network A over B?
2) (3 marks, easy) What can be the advantage of Network B over A?
3) (3 marks, medium) Suppose we deal with a C-way classification problem and that the classifier (a fully connected layer) is directly attached to the top layer drawn in the figure. Compute the number of learnable parameters of the classification layer (let’s assume the bias term remains 0).
4) (4 marks, medium) Consider a scenario: C increases to a very large number. Under this scenario, what would happen? Write down a real-world example of this scenario.

Figure 3: [Left]: Convolutional kernel of dilated convolution. [Right]: Feature maps of three layers. The blue neuron at layer L+2 has different receptive fields (light blue) at layer L+1 and layer L.
4. (3 marks, medium) In the lecture of unsupervised model evaluation, we discussed the relationship between model accuracy and the Fr´echet distance (FD) of training and test sets. Now suppose we have a model M trained on dataset C . We then evaluate this model on two unlabeled test sets A and B . We find FD(A,C) < FD(B,C). Will M always have a higher accuracy on test set A than test set B? Use the experimental results shown below to explain your answer.
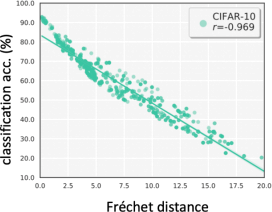
Figure 5: Correlation between classification accuracy and Fr´echet distance on a series of test sets. Figure is from the lecture.
• Section 3. 3D Vision (34 marks)
1. (2 marks) The homogeneous coordinates of a point P in the image coordinate frame are [150, 30, 3]T , where the origin is at the top left corner of the image. Which row and which column of this image is P in?
2. Given two calibrated cameras, C1 and C2 .
1) (4 marks, easy) C1 has a focal length of 400 in x and 250 in y (in pixel unit). The camera has a resolution of 348 × 348, and the camera centre projected to the image is at (225 , 225), with no skew. C2 has a focal length of 500 in x and 375 in y (in pixel unit). The camera has a resolution of 405 × 405, and the camera centre projected to the image is at (400 , 400), with no skew. Here, the origin of the image coordinate frame is the upper left corner. Write down the calibration matrix K1 and K2 for C1 and C2 respectively.
2) (3 marks, easy-medium) Suppose that the coordinate system of camera C1 was originally the same as the world coordinate system and is then clockwise rotated by 30 ◦ about its X axis. Subsequently, the centre of C1 is translated by 0.1 metre along the positive X axis of the world coordinate system, then moved 0.2 metre along the positive Y axis of the world coordinate system. Write down the projection matrices P1 for camera C1, which define the projection of points in the world system to the image of C1 .
3) (3 marks, easy-medium) Suppose that camera C2 begins being aligned to the world coordinate system and is then counterclockwise rotated by 20 ◦ about its X axis. Subsequently, the centre of C2 is translated by 0.15 metre along the positive Y axis of the world coordinate system, then moved 0.3 metre along the negative Z axis of the world coordinate system. Write down the projection matrices P2 for camera C2, which define the projection of points in the world system to the image of C2 .
4) (4 marks, hard) Suppose that the scene has a point P . In the world coordinate system defined above, P lies at (70, 100, −130). Note that the point in the world coordinate system is measured in centimetres. What location (to the nearest pixel) will that world point P map to in the images of both cameras C1 and C2?
5) (4 marks, hard) Hence or otherwise, determine whether the real-world point P is observable from either camera C1 or camera C2 . Please provide an explanation based on the provided information.
Hint: it is not difficult to make incorrect calculations, so write down your steps for partial marks.
3. For a location A on a flat lambertian surface, the surface normal is [0, 0, −1]T . The direction of the incident light is [0, 0, −1]T . We assume light source intensity is 1 and that camera response function is the identify function.
1) (2 marks, easy) If we further assume the albedo of point A is 1, compute the intensity of this point on our image. Does this intensity change when our camera is from a different position (but still can see this point).
2) (2 marks, medium) If we can freely configure our camera position and change light source di- rection (light intensity remains unchanged), will we eventually find a configuration that produces a higher intensity of point A? Explain your answer.
3) (2 marks, easy) Does every point on this surface have the same normal?
4) (2 marks, medium) Does every point on this surface always have the same intensity in our camera?
4. Algorithm design. (6 marks, hard) As shown in Fig. 6, (A, A’), (B, B’), (C, C’), (D, D’), (E, E’), (F, F’), (G, G’) are pairs of corresponding points in the left and right images. Given the image coordinates of point A, A’, B, B’, C, C’, D, D’, E, E’, F, and G, design an algorithm to get the image coordinates of point F’ and point G’ . Here, trivial solutions do not earn marks, i. e ., we assume you cannot manually get coordinates of F’ and G’ . If you are not able to get the coordinates of F’ or G’, briefly explain your reason.

2023-07-18