Data Analysis Questions (DA), and Programming in R Questions (R)
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
Instructions
This assignment will consist of two sections – data analysis questions (DA), and programming in R questions (R):
● There will be 15 DA questions worth 1 point each.
● The DA questions will be multiple choice, and certain questions may have multiple correct answers. For these questions, you will be asked to select all answers that apply.
● There will be 5 programming in R questions worth 3 points each.
● The R questions will be multiple choice or file upload. However, each R question will have a part a) and part b). Part a) will contain the question stem, as well as multiple-choice responses or file upload. Please copy and paste your R code into part b. In order to receive full credit, code must be provided.
● If you get the answer wrong on any of the R questions, but still include code that is close to correct, you may earn partial credit.
● You will not earn extra credit for including your code in part b) of the R questions if you receive full credit in part a).
While you may discuss approaches with your peers, any copying of code or output will be treated as a case of academic dishonesty. All submitted work should be your own. See the syllabus for details on group collaboration.
Set Up
Load the following packages and datasets to complete the programming in R questions:
To find the datasets you will use throughout HW assignments in this course, please see:
Datasets.zip Download Datasets.zip
Download this folder and unzip it. Once you unzip the folder, you will find datasets you will use throughout this class for HW assignments.
On this problem set, you will use two of these datasets, entitled Traffic_Crashes-_-People.csv and Traffic_Crashes-_-Crashes.csv. Set the folder you downloaded to your working directory following the instructions from class, and load both datasets into R. An example is given below, where I have saved the datasets into a folder entitled "DPSS." You can also see me load packages which will be relevant for completing the programming assignments.
library(tidyverse)
library(lubridate)
setwd("/Users/afiakhan/DPSS/Datasets")
people <- read_csv("Traffic_Crashes_-_People.csv")
crashes <- read_csv("Traffic_Crashes_-_Crashes.csv")
This dataset was obtained from the City of Chicago data portal, found here:
https://data.cityofchicago.org/
In the "Traffic_Crashes-_-People" dataset, each record corresponds to an occupant in a vehicle which experienced a crash. The crashes are listed in a separate Crash dataset. Some people involved in a crash may not have been an occupant in a motor vehicle, but may have been a pedestrian, bicyclist, or using another non-motor vehicle mode of transportation. Injuries reported are reported by the responding police officer. Fatalities that occur after the initial reports are typically updated in these records up to 30 days after the date of the crash.
In the "Traffic_Crashes-_-Crashes" dataset, we see information about each traffic crash in Chicago for which the Chicago Police Department responded. Data are available for some police districts in 2015, but citywide data are not available until September 2017. Many crash parameters are reported by the responding police officer, including street condition data, weather condition, and posted speed limits.
—------------------------------------------------------------------------------------------------------------------
Question 1
Given the following table, where T represent treatment status (1=treated, 0=control),
Yic represents an individual’s outcome if they were in the control group, Yit represents an individual’s outcome if they were in the treatment group, Ti represents the individual’s true treatment effect, and Yi represents the observed outcome for the individual—answer the following question:
Hypothetical Experiment
Complete the following table, and use the values to find the average treatment effect ( T) and the estimated average treatment effect (T^):
a. ATE: 3.4, estimated ATE: 4
b. ATE: 3.4, estimated ATE: 2
c. ATE: 10, estimated ATE: 6.6
d. ATE: 6.6, estimated ATE: 10

Question 2
In the above problem, what is true about the assignment mechanism?
a. The average treatment effect among individuals who receive the treatment is lower than the average treatment effect among individuals who receive the control.
b. The average treatment effect among individuals who receive the treatment is equal to the average treatment effect among individuals who receive the control.
c. The assignment mechanism is like that of a Perfect Doctor, who assigns each unit the treatment status associated with the higher outcome.
d. The average treatment effect among individuals who receive the treatment is higher than the average treatment effect among individuals who receive the control.
Question 3
Consider the problem given in Question 1. Calculate the mean of the observed outcome for each individual.
a. 10
b. 6.6
c. 0.5
d. 9
Question 4
Suppose that John studies the relationship between hospitals and health. He has a sample of individuals, notes whether or not they have been to the hospital, and their self-reported health. John says: “it appears that hospitals cause worse health, as people who go to the hospital report worse health than those who do not.”
His friend Lina responds: “No, John. For those who go to the hospital, we don’t know what their health would have been had they stayed home. For those who stay home, we don’t know what their health would have been if they had gone to the hospital.”
What are Lina’s words an example of?
a. The Perfect Doctor: if we wanted to study the causal impact of hospitals on health, we would need to implement a perfect doctor design. In this design, we would only send people to the hospital if they would benefit from hospitalization, or keep them home if they would benefit from staying home.
b. General equilibrium effects: people who do not go to the hospital may have health affected by those who do go to the hospital.
c. The Fundamental Problem of Causal Inference: it is impossible to know what would happen to a unit both under treatment and under control.
d. Attrition: People dropped out of the study, so the remaining sample of hospital- goers and non-hospital goers may not be representative of the overall population.
Question 5
Jeanine flips a coin 100 times, and each time records the outcome as either Heads (1) or Tails (0). The result from each coin flip is what type of variable?
a. Binary
b. Ordinal
c. Continuous
d. String
Question 6
Familiarize yourself with the features of a normal distribution if you have not already. What distinguishes the standard normal distribution from a normal distribution?
a. The standard normal distribution is a type of normal distribution with the mean 1 and standard deviation 1.
b. The normal distribution is a type of standard normal distribution with the mean 1 and standard deviation 1.
c. For the normal distribution, 68% of the observations lie within 1 standard deviation of the mean, 95% within two standard deviations of the mean, and 99.7% within three standard deviations of the mean. This is not true for the standard normal distribution.
d. Data which follows a normal distribution can be converted into a standard normal distribution. To do so, for each entry of the data: subtract the population mean, and divide by the population standard deviation.
Question 7
Below, we have excerpted from Table 1 of "Price Subsidies, Diagnostic Tests and Targeting of Malaria Treatment: Evidence from a Randomized Control Trial" by Jessica Cohen, Pascaline Dupas, and Simone Schaner. The experiment studies the effect of different levels of subsidy for antimalarial therapies (ACTs) sold over the counter at retail drug outlets. They find that a very high subsidy increases access, but many drugs go to patients who do not have malaria.
Their randomization is the level of subsidy, as shown below. The first column shows average values of characteristics for the control group. Columns 2–5 show regression coefficients and standard errors on indicated treatment groups (the omitted category is the control group). Column 6 shows F-statistics and p-values from a test of whether the three ACT subsidy coefficients are jointly equal to zero.
Standard deviations are in brackets, standard errors are in parentheses, and p-values are in braces. * indicates significance at ten percent level, ** at five percent level, and *** at 1 percent level.
Look at Column 3, which compares the sample who receive the 88 percent subsidy to those who receive the control. On what variable do the characteristics of interviewed household head differ between the 88 percent subsidy group and the control group, at the 5 percent level?
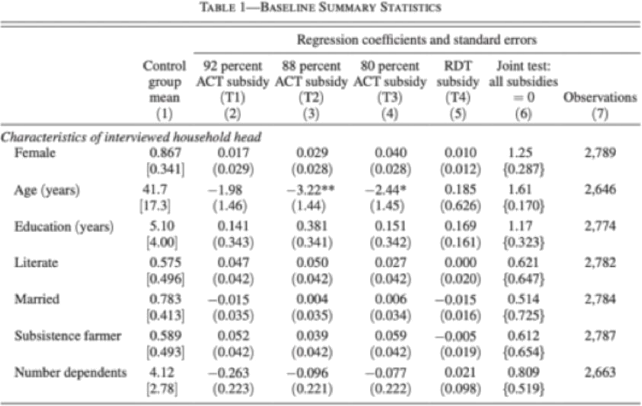
a. Female
b. Age (years)
c. Married
d. Education (years)
Question 8
What is the implication of balance test results when interpreting the findings of a Randomized Control Trial?
a. Balance tests tell us if the experiment is externally valid.
b. Balance tests tell us if randomization was implemented in a way that there is an equal number of individuals in the treatment and control groups.
c. Although treatment status is randomly assigned, it is possible that covariates are unbalanced across treatment and control groups. If we find evidence of unbalanced covariates across treatment and control, we would be concerned that the estimated treatment effect reflects these underlying differences, as opposed to the consequence of the treatment itself.
d. Balance tests check for evidence that treatment status is independent of covariate levels. If there are no differences in the observed covariates, we are certain that there are no possible omitted variables which might explain our estimated treatment effect.
Question 9
Consider the notation given in our discussion of bivariate regression.

Match each term to its meaning: Estimated Intercept, True Intercept, Estimated Slope, or True slope.
Terms:
Question 10
Say you run a bivariate regression on data from a randomized control trial. You use Y for the outcome of interest, and X as a dummy variable for treatment. You estimate the following equation.
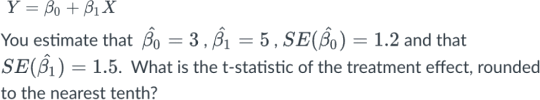
a. 2.0
b. 3.3
c. 5.3
d. 1.3
Question 11
Consider the same scenario given in Question 10. With the standard null hypothesis of no treatment effect, can you say that the treatment had a statistically significant impact?

Question 12
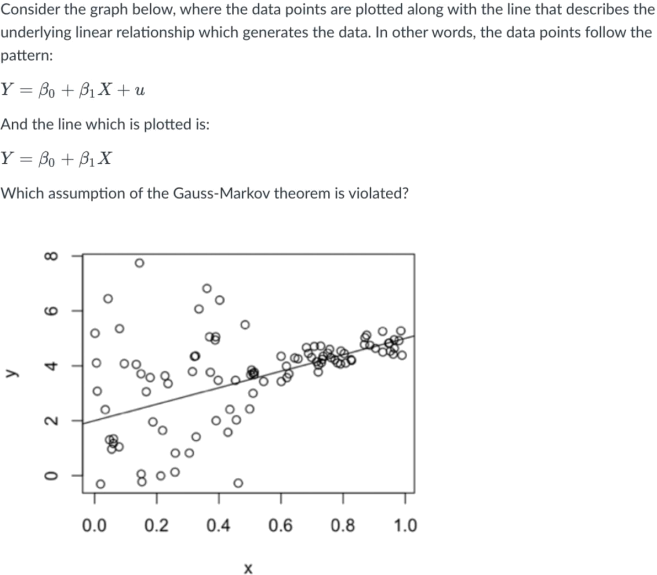
a. Neither homoskedasticity nor conditional mean zero are violated; both are satisfied.
b. We would need to conduct ordinary least squares and calculate the residuals to answer this question.
c. Homoskedasticity is violated, but conditional mean zero is not violated.
d. Conditional mean zero is violated, but homoskedasticity is not violated.
Question 13
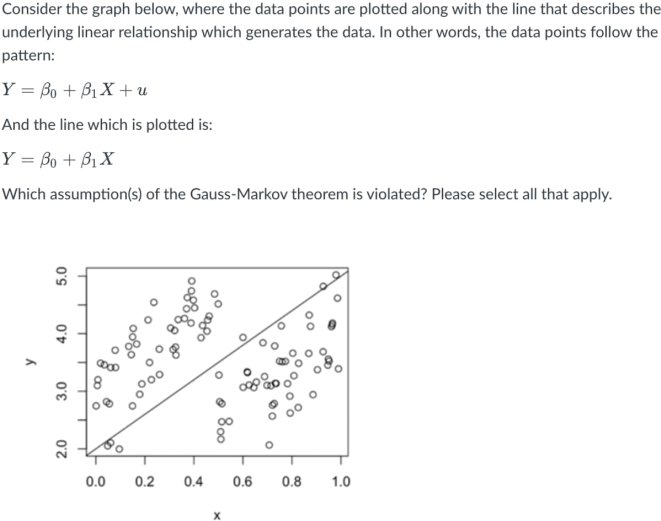
a. Homoskedasticity is violated, but conditional mean zero is not violated.
b. We would need to conduct ordinary least squares and calculate the residuals to answer this question.
c. Conditional mean zero is violated, but homoskedasticity is not violated.
d. Neither homoskedasticity nor conditional mean zero are violated; both are satisfied.
Question 14
Given the following table, calculate the intent-to-treat effect. Each box corresponds to the average outcome for that combination, and the number of individuals per cell is given in parentheses.
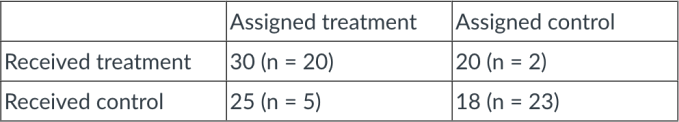
a. 8.5
b. 7
c. 10.8
d. 10
Question 15
When is the intent-to-treat equivalent to the average treatment effect on the treated? The letters in each cell correspond to the number of individuals per cell.

Programming In R
Question 1
Please follow the instructions in the HW description to download and load the dataset: "Traffic_Crashes_-_People.csv". Spend some time exploring the names of the different columns of the datasets, and how they are organized.
Among female sex individuals of age 65 and above in this dataset, what percentage are pedestrians?
HINT: Look at columns entitled AGE, SEX, and PERSON_TYPE. After selecting in the dataset only observations with female sex and age equal to or above 65, calculate what for what percentage PERSON_TYPE is PEDESTRIAN.
a. 1.48
b. 1.68
c. 2.63
d. None of the above
Question 2
Code for Question 1:
Question 3
Again using the dataset entitled "Traffic_Crashes_-_People.csv", answer the following.
Filter the dataset to only those with no indication of injury. How old is the oldest person in this filtered dataset? Use the INJURY_CLASSIFICATION and AGE columns to answer this question.
a. 110
b. 98
c. 38
d. 112
Question 4
Code for Question 3:
Question 5
Again using the dataset entitled "Traffic_Crashes_-_People.csv", answer the following.
How many people in the dataset are age 25 or younger and are passengers? Use PERSON_TYPE and AGE to answer this question.
a. 88049
b. 4225
c. 3890
d. 83848
Question 6
Code for Question 5:
Question 7
Begin with the "Traffic_Crashes_-_People.csv" dataset. Consider only observations pertaining to individuals who are age 65 or older. Merge with the crashes dataset. Get the year from CRASH_DATE. How many distinct people age 65 or above were involved in a car crash during the year 2020?
HINT: In order to merge, use the variable: "CRASH_RECORD_ID" which is shared across both datasets.
a. 11,944
b. 10,154
c. 8,096
d. 9,027
Question 8
Code for Question 7:
Question 9
Plot the number of people who died in car crashes over time (every year). Submit an image of your final result in a line graph, as well as your code in the following question.
Begin with the people dataset, and select only the observations where the variable INJURY_CLASSIFICATION indicates a fatal injury. Merge with the crashes dataset to obtain the year associated with each person who got into fatal car accident. Use ggplot to make a line graph which illustrates the number of people who died in car crashes every year.
Question 10
Code for Question 9:
2023-06-25