CSE120 Final
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
Q1
Suppose there are 3 cache designs
Design 1:
Direct-mapped cache.
Each cache block is 1 byte.
Cache has 10-bits for index and 6-bits for tag field.
Design 2:
2-way set associative cache.
Each cache block is 1 word (4 bytes).
Cache has 7-bits for index and 7-bits for tag field.
Design 3:
fully associative cache with 256 cache blocks.
Each cache block is 1 word.
Cache has a 14-bit tag.
a. What is the size of each cache? The size here comprises only the cached data (excluding tag bits or valid/dirty bits)
b. How many total number of bits (or Kibits) does each cache need to store tags?
c. Which cache design has the maximum number of conflict misses? Which has the least? Make sure to upload readable image of your work!
a.
Design1 :
Index=10bits. Therefore, no of blocks=2^10=1Ki. Cache size= 1Ki * 1 B = 1KiB.
Design2:
Index =7bits. No. of blocks= 2^7 * 2 = 256 (*2 because of the 2 way SA cache). Cache size = 256 * 4B = 1KiB Design3:
No. of blocks=256. Cache size =256 * 4 B = 1KiB
b.
Design 1 :
6-bits for tag field. Total tag space= 6 * no. of blocks= 6* 1Ki= 6Kibits
Design 2:
7-bits for tag field. Total tag space= 7 * no. of blocks = 7 * 256= 1792 bits = (1782/1024) Kibits=1.75 Kibits
Design 3:
Cache has a 14-bit tag. Total tag space = 14 * no. of blocks=14* 256= 3.5 Kibits
c.
A direct mapped cache will have the maximum number of conflict misses, therefore it will be Design 1. Design 3 (Fully associative) will have 0 conflict misses This question(c) won’t feature in F2022 fnal exam
Q2
This question examines the accuracy of 1-bit dynamic branch predictors for the following repeating patterns (e.g., in a loop) of branch outcomes. Answer each question (1-4) for each sequence (a-b):
(a) T, T, T, T, NT
(b) T, NT, NT, NT, NT
1. What is the accuracy (“score card” in lec 15-16) of a 1-bit dynamic predictor for these sequences of branch outcomes (a and b) provided we encounter this branch outcome sequence only once? Assume this predictor starts in the "Predict not taken" state for both a and b.
Make sure to upload readable image of your work! You will need to show the prediction behavior using the following table format:
|
Branch Prediction |
Actual Branch behavior |
Prediction Accuracy |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
1.
![]() (a)
(a)
|
Branch Prediction |
Actual Branch behavior |
Prediction Accuracy |
|
NT |
T |
❌ |
|
T |
T |
✔ |
|
T |
T |
✔ |
|
T |
T |
✔ |
|
T |
NT |
❌ |
Score card= 3/5
(b)
|
Branch Prediction |
Actual Branch behavior |
Prediction Accuracy |
|
NT |
T |
❌ |
|
T |
NT |
❌ |
|
NT |
NT |
✔ |
|
NT |
NT |
✔ |
|
NT |
NT |
✔ |
Score card=3/5
Q3
This question examines the accuracy of 2-bit dynamic branch predictors for the following repeating patterns (e.g., in a loop) of branch outcomes. Answer each question (1-4) for the following sequence
T, T, T, T, NT
1. What is the accuracy (“score card” in lec 15-16) of the 2-bit predictor for this sequence of branch outcomes provided we encounter this branch outcome sequence only once, assuming that the predictor starts off in the “Strongly Predict Not Taken” state (SNT)?
2. What is the accuracy (“score card” in lec 15-16) of a 2-bit predictor if the pattern is repeated forever? Assume this predictor starts in the “Strongly Predict Not Taken” state (SNT).
Make sure to upload readable image of your work! You will need to show the prediction behavior using the following table format:
|
Branch Prediction |
Actual Branch behavior |
Prediction Accuracy |
|
|
|
|
|
|
|
|
1.
|
Branch Prediction |
Actual Branch behavior |
Prediction Accuracy |
|
SNT |
T |
❌ |
|
WNT |
T |
❌ |
|
WT |
T |
✔ |
|
ST |
T |
✔ |
|
ST |
NT |
❌ |
Score card= 2/5
2.
1st pass already covered.
2nd pass:
|
Branch Prediction |
Actual Branch behavior |
Prediction Accuracy |
|
WNT |
T |
❌ |
|
WT |
T |
✔ |
|
ST |
T |
✔ |
|
ST |
T |
✔ |
|
ST |
NT |
❌ |
Score card= 3/5
3rd pass:
|
Branch Prediction |
Actual Branch behavior |
Prediction Accuracy |
|
WT |
T |
✔ |
|
ST |
T |
✔ |
|
ST |
T |
✔ |
|
ST |
T |
✔ |
|
ST |
NT |
❌ |
Score card= 4/5
Henceforth the pattern repeats. Therefore, for n passes, the score card is:
(2 +3+ (n-2)*4)/ (5*n) .In infinity limit, this becomes 4/5
Q4
Given the following processor configuration of P1.
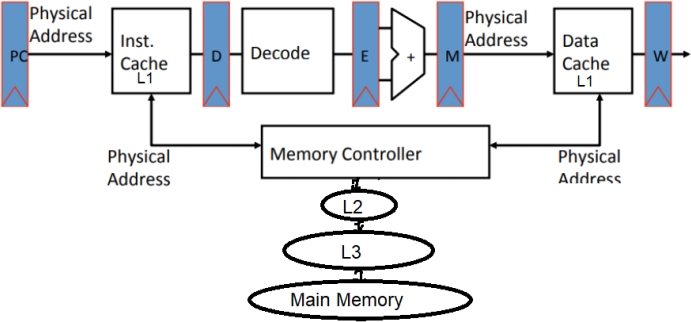
Assume base CPI=1 without memory stalls; assume L1 hit occurs within base CPI. L1 access time=1 cycle (accounted for within base CPI), L1 miss rate=10%. L2 access time=10 cycles, L2 miss rate=40%. L3 access time=50 cycles, L3 miss rate=80%, Main memory access time = 100 cycles.
80% of instructions access L1 data cache.
1. Find the AMAT of P1
2. Find the overall CPI of P1
Make sure to upload readable image of your work!
1. AMAT = 1 + 0.1*10 + 0.1*0.4*50 + 0.1*0.4*0.8*100 = 7.2 cycles
2. Data cache access cycles d= 1 + 0.8*(0.1*10 + 0.1*0.4*50 + 0.1*0.4*0.8*100 )= 5.96 cycles CPI = Additional Cycles spent in accessing instruction + d
= 0.1*10 + 0.1*0.4*50 + 0.1*0.4*0.8*100 +d
= 12.16 cycles
Q5
A 4-processor systems implements cache coherence with a snoopy MSI protocol. For each access in the sequence below (to the same BLOCK address), list the coherence states (M/S/I) for each processor’s cache after the access. Assume all the cache states begin in the Invalid (I) state.
|
Event |
P1 state |
P2 state |
P3 state |
P4 state |
|
|
I |
I |
I |
I |
|
P1 reads |
|
|
|
|
|
P1 writes |
|
|
|
|
|
P2 reads |
|
|
|
|
|
P4 reads |
|
|
|
|
You may only upload an image of the completed table shown above. You do not need to show any other accompanying work.
|
Event |
P1 state |
P2 state |
P3 state |
2023-06-14