COMPSCI 351 Fundamentals of Database Systems Semester One, 2020
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
Semester One, 2020
FINAL ASSESSMENT
COMPUTER SCIENCE
Fundamentals of Database Systems
Question 1 (10 marks)
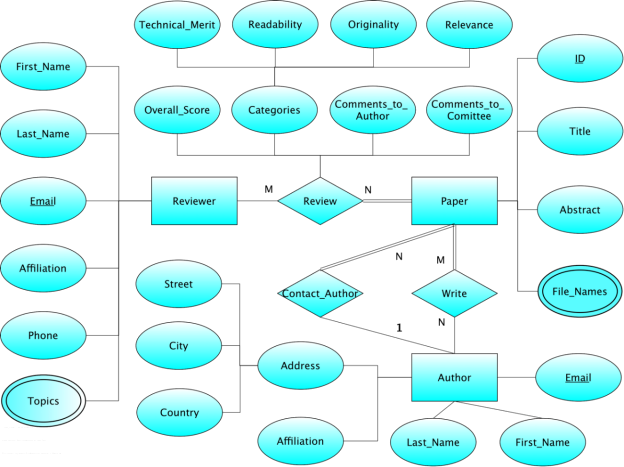
Using the algorithm taught in the course, map the following Conference-Review ER diagram into a relational database schema. Specify all primary keys and foreign keys.
Question 2 (25 marks)
The following questions use the UNIVERSITY database schema and the sample database state shown below .

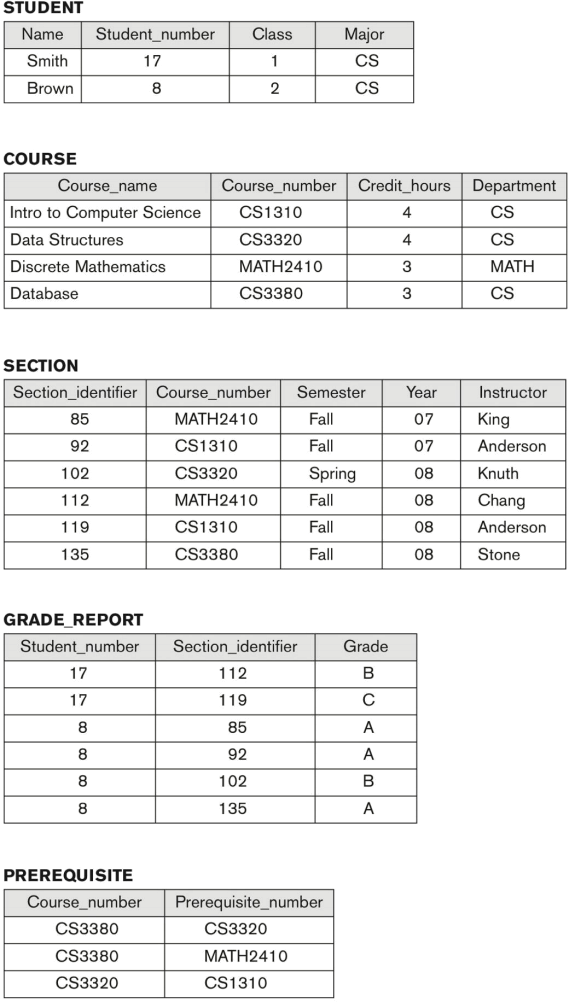
a) Define the following SQL statements:
i . Set the default value of the attribute ‘Department’ in the COURSE table to ‘CS’ . [3 marks]
ii . Add a new attribute ‘Birth_Date’ to the STUDENT table with the ‘DATE’ type as its domain . [3 marks]
iii . Change the grade value of the student number ‘17’ with the section number ‘119’ in the ‘GRADE_REPORT’ table to ‘B ’ (assume that the domains of the Student_number and Section_identifier attributes are both CHAR). [4 marks]
iv . Define a query to retrieve the transcript records of the student number ‘8’ . Transcript includes the course name, course number, credit hours, semester, year, and grade for each course completed by the student . [5 marks]
b) Define the following queries using Relational Algebra expressions:
i . For each section taught by Professor ‘Anderson’ , retrieve the course name, course number, semester, year, and number of students who took the section . [5 marks]
ii . Retrieve the names and major departments of the students who did not study all the courses that were offered in 2008. [5 marks]
Question 3 (25 marks)
A B+-tree on an attribute X can be alternatively constructed in a batched manner:
1. Sequentially store the relation by sorting the records in a non-descending order of X;
2. Build the first-level index (the smallest key of each block in the index can be safely removed), then the second- level index, · · · , until the top level has only one block .
Consider 19 records inserted sequentially (not in ascending order) to a relation . The key values (in the order of the insertion) are 38, 12,9,6,31,42,33,8,2, 15,5,7, 11,23,22,34, 27, 49, 50 respectively . Each block can hold up to 3 data records . Each block can hold up to 4 pointers together with 4 integers . Consider the two methods in building a B+-tree:
a) Start with an initially empty B+-tree, insert the records sequentially . Draw the snapshots of the B+-tree after the insertion of 6, 7 and 50, respectively . [12 marks]
b) Construct the B+-tree in a batched manner:
i. Show the process of sorting the records (use a box to denote a block) and indicate the I/O cost of the sorting process (for simplicity, each record needs to be read once and written once in a pass), given that the memory can hold up to 3 blocks of data. [9 marks]
ii. Draw the structure of the B+-tree after the construction. [4 marks]
Question 4 (20 marks)
Consider three relations x(A, B), y(B,C) and z(A,C) . x has a primary index on the key of combined attributes (A, B); y has a primary index on the key of combined attributes (B, C); z has a primary index on the key of combined attributes (A, C) . Both x(A, B) and y(B, C) have clustering index on B . z(A,C) has a clustering index on A and a secondary index on C . The parameters (|x| denotes the number of tuples in relation x) are:
• x(A,B): |x| = 500, V (A,x) = 30, V (B,x) = 50,
• y(B,C): |y| = 400, V (B,y) = 30, V (C,y) = 100,
• z(A,C): |z| = 300, V (C,z) = 40, V (A,z) = 50,
• The memory can hold up to m = 102 pages,
• Each block holds 2 tuples for all relations including intermediate results .
Find the best “index-based” plan for x ⋈ y ⋈ z, i.e . , the plan only considers index-based join algorithms introduced in the course without sorting any relation . Explain your answer by analyzing the I/O cost (under the default uniform distribution assumption, only count the I/Os for retrieving the underlying tuples) . Assume that tuples of each attribute value, if the relation is stored sequentially, is aligned with the block boundaries . This problem does not consider pipeline, but the final join result does not need to be outputted . [20 marks]
Question 5 ( 15 marks)
Consider the four transactions below:
• T1 : r1 (A); w1 (C); w1 (B);
• T2 : r2 (B); w2 (D); w2 (A) ;
• T3 : r3 (C); w3 (B);
• T4 : w4 (D);
a) Insert locks using conservative (static) 2PL: A transaction T requests all the shared and exclusive locks needed by T immediately before the first operation of T while a lock of T is released immediately after its final use by T . Explain why conservative (static) 2PL can prevent deadlock, i.e . , eventually all transactions can complete . [4 marks]
b) Draw the precedence graph of the schedule
S : r1 (A); r2 (B); w1 (C); w2 (D); r3 (C); w3 (B); w1 (B); w4 (D); w2 (A) ; and then indicate if the schedule is conflict- serializable . [3 marks]
c) Consider schedule S under a lock scheduler: each transaction requests the (shared / exclusive, depending on the operation) lock of the corresponding data item immediately before an operation and release all the locks immediately after the last operation of the transaction .
i . Find the first deadlock of the schedule by drawing the corresponding wait-for graph . [3 marks]
ii . Explain why the wait-die protocol can prevent this deadlock . Assume that the transactions arrive to the system in the order of T 1 ,T2 ,T3 ,T4 . [5 marks]
Question 6 (5 marks)
Consider a system that uses the immediate update protocol (steal/no-force) with checkpointing . Describe the recovery process from a system crash for the following transactions:
1. T1 has committed before thecheckpoint,
2. T2 started before the checkpoint but has committed after the checkpoint,
3. T3 started before the checkpoint but has not committed before the crash,
4. T4 started after the checkpoint but has committed before the crash,
5. T5 started after the checkpoint but has not committed before the crash .
Specifically, for each transaction, indicate the action (e.g . , redo and undo), the application scope (i .e . , operations before the checkpoint or after the checkpoint) and the order (i .e . , new to old , or old to new) of operations on which the action should be applied . Anoperation (data access operation) w is newer than another operation w ’ if w is logged later than w ’ . [5 marks]
2023-06-03