INFS3200 Semester Two Examinations, 2022
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
Semester Two Examinations, 2022
INFS3200
Question 1: [14 marks] Distributed Systems
Briefly answer the following questions.
Employee Table:
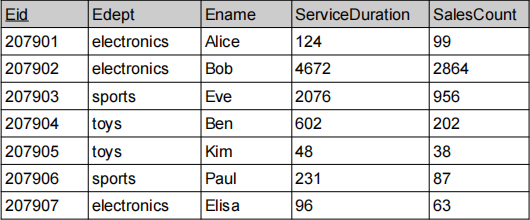
Part A
Given the Employee table and a set of predicates P = {P1, P2, P3}, where:
- P1: ServiceDuration < 200
- P2: 200 <= ServiceDuration < 1000
- P3: ServiceDuration > 1020
(A1) [2 marks] Based on P, perform a horizontal fragmentation of the Employee table by listing the tuples in every fragment.
(A2) [3 marks] There are three “correctness” criteria to consider when fragmenting tables; completeness, disjointness, and reconstructibility (CDR properties). Explain what is meant by each of these three properties.
(A3) [1 mark] Does the fragmentation of the Employee table shown above (in the definition of P) comply to the CDR criteria? Briefly explain.
Part B
Given a new set of predicates P = {P1, P2} where P1: ServiceDuration < 500, P2: SalesCount > 50, answer the following questions:
(B1) [1 mark] How many minterm predicates can be derived from P?
(B2) [1 mark] List all possible minterm predicates based on P.
(B3) [2 marks] Does the horizontal fragmentation of the Employee table based on your minterm predicates satisfy the CDR criteria? Explain.
Part C
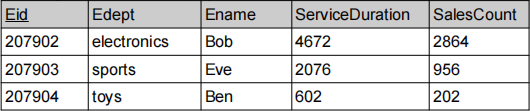
Given a distributed database over three sites (S1, S2, and S3), with S1 containing fragment F1 of the Employee table, S2 containing fragment F2 of the Employee table, and S3 containing the LeaveAllowance table as follows:
S1: Fragment 1 of the Employee table
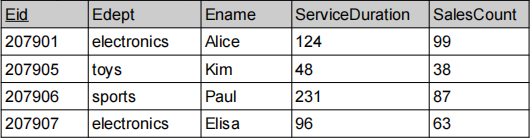
S2: Fragment 2 of the Employee table
S3: LeaveAllowance
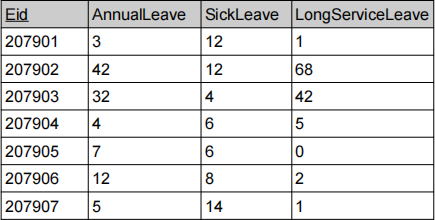
(C1) [1 mark] Write an SQL query which will be issued on site S3 to get the Eid and Ename of employees who have an AnnualLeave balance greater than 20 days.
(C2) [3 marks] Please explain how we can use a semi-join operator to conduct derived horizontal fragmentation on the LeaveAllowance table based on Fragment 1 and Fragment 2. For each resulting fragment (LeaveAllowance1 and LeaveAllowance2), list the tuples of each.
Question 2: [8 marks] Distributed Transaction Management
Briefly answer the following questions.
(1) [2 marks] In a database which handles multiple concurrent transactions, a schedule governs the order of operations for each of these concurrent transactions. What does it mean for a schedule to be in conflict? Use a simple example with two concurrent transactions T1 and T2 to explain your answer.
(2) [2 marks] The two-phase locking (2PL) protocol can be used to ensure the serializability (correctness) of parallel transactions. Explain each of the two phases of the 2PL protocol.
(3) [4 marks] When we want to update distributed data, we can maintain consistency among multiple copies of the same data through either a synchronous (eager) approach, or an asynchronous (lazy) approach. Explain how these two approaches differ, focusing on the advantages and disadvantages of each. You may provide examples which motivate the selection of one over the other to assist with your explanation.
Question 3: [7 marks] Data Warehouse Design
Briefly answer the following questions
(1) [3 marks] Describe the difference between OLTP and OLAP queries. Which type do data warehouses primarily support?
(2) [2 marks] Given the following fact table containing two dimensions (time and location) as well as the sales fact, perform a roll-up operation on the time dimension, listing all the tuples of the new output table. You may assume that all entries in the fact table belong to the same year (2022).
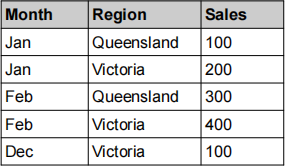
(3) [2 marks] Compare and contrast the star schema and the snowflake schema in data warehouse modelling. What is the major difference between the two?
Question 4: [7 marks] Data Warehouse Implementation
Briefly answer the following questions
Part A
(A1) [1 mark] Given the following table, generate a bitmap index for the Location column.
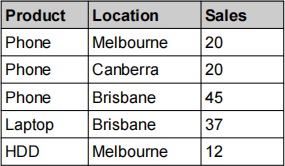
(A2) [2 marks] Assume we have three hierarchical dimensions and one measure:
Time: day < week < month < year
Product: brand < type < department
Location: city < state < country < continent
Which of the following cuboids can be used to answer the GROUP BY query on the dimension/hierarchy values of {month, country}? For each candidate cuboid, provide a brief explanation as to why it can or cannot be used.
Cuboid 1: {month, brand, country}
Cuboid 2: {month, brand}
Cuboid 3: {week, continent}
Cuboid 4: {year, type}
Cuboid 5: {department, country}
Part B
Consider a data warehouse which contains three dimensions product, location, and time, each with no hierarchies. Below is a lattice of all possible candidate cuboids where P, L, and T represent each of product, location, and time. Each number in the lattice shows the cost of solving a GROUP BY query if that particular cuboid can be used (and is materialized).
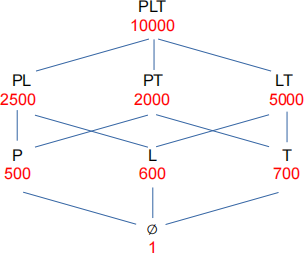
(B1) [1 mark] You can assume that PLT is already materialized. Explain why this is the case.
(B2) [3 marks] Given that PLT is already materialized, and assuming that the frequency of all GROUP BY queries is the same, compute which cuboid should be materialized first to minimize the total query cost.
Question 5: [10 marks] Database Integration and Data Linkage
(1) [2 marks] The mediator-wrapper architecture is one approach for supporting database integration. Explain what the roles of both the mediator and the wrapper(s) are when dealing with different data sources.
(2) [1 mark] (Distributed) Databases can be classified on a three-dimensional space. Briefly explain the meaning of each dimension: Distribution, Autonomy, and Heterogeneity.
(3) [2 marks] Given the two strings “Australia_Bank” and “Bank_of_Aus”, compute the Jaccard similarity using 3-grams.
(4) [1 mark] Given the aforementioned strings “Australia_Bank” and “Bank_of_Aus”, is Edit distance or tokenization-based similarity (like 3-gram Jaccard similarity) a better choice for measuring similarity? Why?
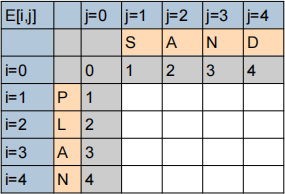
(5) [4 marks] Given two strings “SAND” and “PLAN”, compute the edit-distance between them using the dynamic programming edit-distance algorithm. The following matrix can be filled in to assist you.
Please also explicitly indicate the final edit distance value from your computation.
Question 6: [4 marks] Data Quality Management
Briefly answer the following questions.
(1) [2 marks] Provide two (of the many) data quality dimensions, and give an example of each.
(2) [2 marks] There are four basic steps for data governance. The second step involves “measuring the costs” . What are these costs, and how can they be measured?
Question 7: [4 marks] Data Privacy
Briefly answer the following questions.
(1) [2 marks] Given the following table, and the following privacy rule, explain (by example) how an attacker could leak private information about specific staff members.
StaffPayment
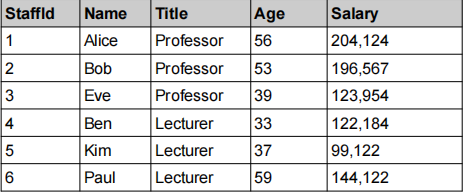
Privacy Rule
The requester cannot query the salary of any individual employee.
(2) [2 marks] Explain how either k-anonymity or l-diversity (or both) could be applied to the StaffPayment table in order to reduce the chance of any privacy leakage.
Question 8: [6 marks] Advanced Topics
Briefly answer the following questions.
(1) [2 marks] Given the following geospatial map with ten data points (labelled 1 to 10), and the associated quad-tree data structure (shown as boxes over the geospatial map) with a maximum per-bucket load of 1, explain what happens when we insert an element 11 (labelled 11) at the position shown in the map? What does the resultant quad-tree look like?
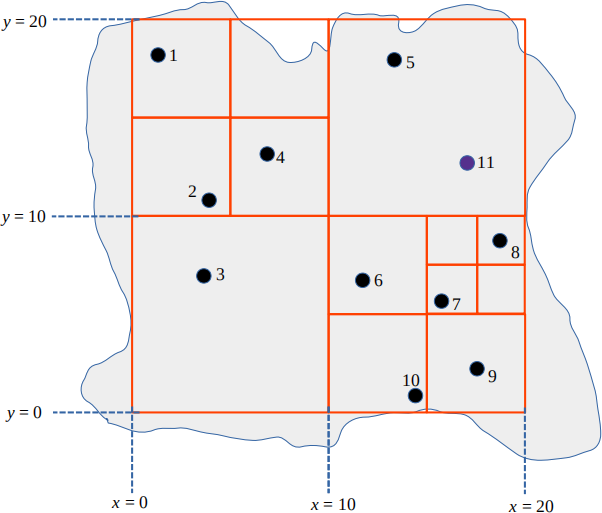
(2) [2 marks] Explain how we can use the quad-tree structure to query for all points within the (x,y) region bounded by (10, 0) and (20, 10)? Which points will be returned?
(3) [2 marks] Briefly discuss the concept of in-memory key-value stores as compared to traditional relational database management systems. Provide one possible use-case for an in-memory key- value store.
2023-05-30