INFS3200 Advanced Database Systems Semester One Examinations, 2022
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
Semester One Examinations, 2022
INFS3200 Advanced Database Systems
Question 1. [12 Marks] Distributed Databases
Briefly answer the following questions.
Student Table:
|
Sid |
Sname |
Course |
Result |
|
452101 |
Jim |
2000 |
40 |
|
452102 |
David |
3600 |
50 |
|
452103 |
Paul |
2400 |
60 |
|
452104 |
Paul |
3900 |
80 |
|
452105 |
Kim |
1200 |
70 |
|
452106 |
Elisa |
6700 |
80 |
a) You are given a set of predicates P = {P1, P2, P3}, where P1: Result=40, P2: 40< Result <80, P3: Result =80.
(1) [2 Marks] Based on P, perform a horizontal fragmentation of the Student Table by listing the tuples of every fragment.
(2) [2 Marks] Does this fragmentation meet the correctness criteria? Briefly explain.
b) When performing horizontal fragmentation of the Student Table using minterm
predicates, we have a set of predicates P = {P1, P2}, where
P1: Result >60, P2: Result <60.
(1) [ 1 Mark] How many minterm predicates are possible?
(2) [ 1 Mark] List all possible minterm predicates.
(3) [2 Marks] Generate a set of minterm predicates that satisfy the correctness criteria.
c) Given a distributed database over three sites, S1, S2, and S3 with Fragment 1 of
Student Table on S1, Fragment 2 of Student Table on S2, and Study Table on S3.
S1: Fragment 1 of Student Table
|
Sid |
Sname |
Course |
Result |
|
452101 |
Jim |
2000 |
40 |
|
452102 |
David |
3600 |
50 |
|
452103 |
Paul |
2400 |
60 |
S3: Study Table
S2: Fragment 2 of Student Table
|
Sid |
Sname |
Course |
Result |
|
452104 |
Paul |
3900 |
80 |
|
452105 |
Kim |
1200 |
70 |
|
452106 |
Elisa |
6700 |
80 |
|
Sid |
GPA |
Sname |
Program |
|
452101 |
2 |
Jim |
CompSci |
|
452102 |
6 |
David |
Engg |
|
452103 |
5 |
Paul |
Engg |
|
452105 |
2 |
Kim |
IT |
|
452106 |
7 |
Elisa |
DataSci |
(1) [ 1 Mark] Write an SQL statement for a database query that is to be issued on site S3: “Find the information about Courses of Students whose GPA is 2”.
(2) [ 1 Mark] Step-by-step, use plain English or SQL queries to describe the process of the semi-join operation to be initiated at site S3.
d) [2 Marks] Using horizontal fragmentation of Student Table as an example, after Student Table is fragmented correctly, how do you update a tuple in Student Table with data integrity constraints (e.g., primary-key) maintained? Please briefly describe the process.
Student Table:
|
Sid |
Sname |
Course |
Result |
|
452101 |
Jim |
2000 |
40 |
|
452102 |
David |
3600 |
60 |
|
452103 |
Paul |
2400 |
70 |
|
452104 |
Paul |
3900 |
80 |
|
452105 |
Kim |
1200 |
70 |
|
452106 |
Elisa |
6700 |
80 |
Question 2. [8 Marks] Distributed Transaction Management
Briefly answer the following questions.
a) [4 Marks] When updating the distributed data, distributed transaction management can use either primary-copy-based approach or voting-based approach to maintain data consistency among multiple copies. Please explain how these two approaches work and compare their advantages and disadvantages.
b) [4 Marks] Why do we need Write-Ahead-Logging (WAL) in transaction management? What is UNDO operation in a recovery process? What will happen during the UNDO operation?
Question 3. [9 Marks] Data Warehouse Design
Briefly answer the following questions.
a) [2 Marks] What are the OLAP operations? Give two examples.
b) [2 Marks] List and describe the different kinds of data warehouse schemas. In data warehouse modelling, what are the fact table and the dimensionality table?
c) [3 Marks] What is a materialized view? Why can the performance of SQL queries with a GROUP BY clause be improved by using materialized views?
d) [2 Marks] Consider a data warehouse schema with 3 dimensions (x, y, z) and a data cube operation applied on all these dimensions. Please list all possible groups of dimensions (i.e., cuboids) that can be implemented as materialized views.
Question 4. [5 Marks] Data Warehouse Implementation
Briefly answer the following questions.
a) [2 Marks] Assume we have three hierarchical dimensions and one measure below.
Time: [day <month < quarter < year]
Item: [name < brand < type]
Location: [street <city < state < country]
Measure: sales
Which of the following cuboids can be used to answer the GROUP BY query on {month, state}? For each of the possible candidate cuboids, give a brief explanation.
Cuboid1: {quarter, type, country}
Cuboid2: {month, brand, state}
Cuboid3: {month, type, city}
Cuboid4: {quarter, type}
Cuboid5: {quarter, city}
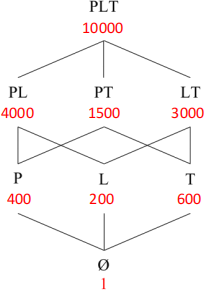
b) [3 Marks] Consider a data warehouse which contains three dimensions product, location, and time with no hierarchies. Below is a lattice of all possible cuboids created on the data warehouse, where P, L, and T represent product, location, and time, respectively. Each of the numbers shows the cost of using the corresponding cuboid, if materialized to answer a GROUP BY query. Suppose that the frequency distribution of GROUP BY queries is the same.
What are the first two cuboids that should be materialized in order to minimize the total query cost, and why?
Question 5. [10 Marks] Database Integration and Data Linkage
Briefly answer the following questions.
a) Given two strings “School of Art” and “Art School”:
(1) [2 Marks] Calculate their similarity using the Jaccard Coefficient (with 3-gram) string- matching technique.
(2) [4 Marks] Compare and contrast two different similarity computation approaches: the Edit Distance approach and the Tokenization (q-gram) approach. Describe their advantages and disadvantages in different situations of string comparison.
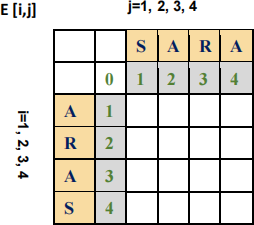
b) [4 Marks] Given two strings, “SARA” and “ARAS”, please use the dynamic programming approach to calculate their edit distance matrix by filling out the following matrix E with all values of E[i,j]: E[1,1], E[1,2], E[1,3], E[1,4], E[2,1], E[2,2], E[2,3], E[2,4], E[3,1], E[3,2], E[3,3], E[3,4], E[4,1], E[4,2], E[4,3], E[4,4].
Please also explicitly indicate the final result of the edit distance of these two strings.
Question 6. [6 Marks] Data Quality Management
Briefly answer the following questions.
a) [2 Marks] In data quality issues, what is Dynamic Data Integrity? Briefly explain this concept and give an example.
b) [4 Marks] In data quality governance, there are four basic steps. Briefly describe these four steps and their tasks to be performed.
Question 7. [4 Marks] Data Privacy
Briefly answer the following questions.
a) [2 Marks] Briefly describe the approach of k-Anonymity for preserving data privacy and compare it with other data privacy preservation approaches.
b) [2 Marks] In Differential Privacy approach, a function (e.g., Laplace Distribution) can be used to add random noise into the dataset. Why do we do it? What does the term of ‘sensitivity’ mean in Differential Privacy approach?
Question 8. [6 Marks] Advanced Topics
Briefly answer the following questions.
a) [2 Marks] Row storage vs. column storage, what are their advantages and disadvantages?
b) [2 Marks] Briefly explain the concept of NoSQL technology. What are the differences between NoSQL and SQL languages?
c) [2 Marks] What is “Curse of Dimensionality” in data processing? What is the implication to the algorithms when processing high dimensional data?
2023-05-30