FIT5047 Fundamentals of Artificial Intelligence 2023
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
FIT5047 2023
Fundamentals of Artificial Intelligence
FIT5047 4th Assignment
Due date: 23 th May 2023 (23:55).
Evaluation: 100 marks = 20%.
Submission site: In Moodle.
Submission instructions and late subimssion policy: In Moodle.
For this assignment, there are no restrictions on the use of generative AI technologies.
However, whenever used, generative AI must be acknowledged. For further information, please, refer to the current university policy on the use of generative AI.
Question 1: Classification, Decision Trees, Na¨ıve Bayes, k-NN, WEKA [ 4+((3+2)+(2+10+3)+(6+2))+8 = 40 ]
Consider the dataset postoperative-patient-data_simplified .arff available on moodle. This dataset contains health-status attributes of post-operative patients in a hospital, with the target class being whether the patients should be discharged (S) or remain in the hospital (A). Additional documentation regarding these attributes appears in the arff file.
1. Before you run the classifiers, use the wEKA visualization tool to analyze the data, and report briefly on the types of the different variables and on the variables that appear to be important.
2. Run J48 (=C4.5, Decision Tree), Na¨ıve Bayes and IBk (k-NN) to learn a model that predicts whether a patient should be discharged. Perform 10-fold cross validation, and analyze the results obtained by these algorithms as follows. Note: Click on the “Choose” bar to select relevant parameters. Explanations of parameters you should try appear below. You should report on performance for at least two variations in total of the operational parameters minNumObj and unpruned for J48, and at least two variations in total of KNN and distanceWeighting for k-NN.
J48
· binarySplits: whether you use binary splits on nominal attributes when building the trees.
· minNumObj: the minimum number of instances per leaf.
· unpruned: whether pruning is performed (try TRUE and FALSE). · debug: if set to TRUE, the classifier may output additional information. · saveInstanceData: whether to save the training data for visualization.
Na¨ıve Bayes (parameter variations are not relevant to this lab)
k-NN (IBk) (under lazy in wEKA)
· KNN: the number of neighbours to use.
· crossValidate: whether leave-one-out X-validation will be used to select the best k value between 1 and the value specified in the KNN parameter.
· distanceWeighting: specifies the distance weighting method used (when k > 1). · debug: if set to TRUE, the classifier may output additional information.
(a) J48 (=C4.5)
i. Examine wEKA’s output (e.g., Decision Tree), and indicate which are the main variables.
ii. What is the accuracy of the output produced by wEKA (e.g., Decision Tree)? Explain the results in the confusion matrix.
(b) Na¨ıve Bayes
i. Explain the meaning of the “probability distributions” in the output, illustrating it with reference to the BP STBL attribute. Note that WEKA does smoothing when computing probabilities for Naive Bayes. You should calculate the probabilities from the data, not from WEKA.
ii. Calculate (by hand) the probability that a person with the following attribute values would be discharged, and the probability that they would remain in hospital. Show your calculations.
L-CORE = mid
L-SURF = low
L-O2 = good
L-BP = high
SURF-STBL = stable
CORE-STBL = stable
BP-STBL = mod-stable
iii. Run the Na¨ıve Bayes classifier to confirm the prediction in item 2(b)ii. What is the accuracy of the Na¨ıve Bayes classifier? Explain the results in the confusion matrix.
(c) k-NN
i. Find three instances in the dataset that are similar to the above patient (you can do this visually), and use the Jaccard coefficient to calculate (by hand) the predicted outcome for this patient. Show your calculations.
ii. What is the accuracy of the k-NN classifier for different values of k? Explain the results in the confusion matrix.
3. Draw a table to compare the performance of J48, Na¨ıve Bayes and IBk using the summary measures produced by wEKA. Which algorithm does better? Explain in terms of wEKA’s summary measures. Can you speculate why?
Question 2: Classification, Decision Trees, Na¨ıve Bayes, k-NN, WEKA [ (1+1)+((2+3+12+3)+(5+2)+(5+2))+4 = 40 ]
Consider the dataset tic-tac-toe .arff available on moodle. Each example in this dataset represents a different game of tic-tac-toe (http://en.wikipedia.org/wiki/Tic-tac-toe), where the player writing crosses (“x”) has the first move. Only those games that don’t end in a draw are included, with the positive class representing the case where the first player wins and the negative class the case where the first player loses. The features encode the status of the game at the end, so each square contains a cross “x”, a nought “o” or a blank “b” .
1. Before you run the classifiers, use the wEKA visualization tool to analyze the data.
(a) Which attributes seem to be the most predictive of winning or losing? (hint: if you were the “x” player, where would you put your first cross and why?)
(b) What can you infer about the advantage (or otherwise) of being the first player?
2. Run J48 (=C4.5, Decision Tree), Na¨ıve Bayes and IBk (=k-NN) to learn a model that predicts whether the “x” player will win. Perform 10-fold cross validation, and analyze the results obtained by these algorithms as follows.
Note: When using J48, click on the “Choose” bar to try different values of minNumObj (default is 2); and when using IBk, try different values of KNN (default is 1).
(a) J48 (=C4.5)
i. Examine the Decision Tree and indicate the main variables.
ii. Trace the Decision Tree for the following game. What would it predict?

iii. What is the first split in the Decision Tree? Calculate (by hand) the Information Gain obtained from the first split in the tree. Show your calculations.
iv. What is the accuracy of the Decision Tree? Explain the results in the confusion matrix for the best option you tried.
(b) Na¨ıve Bayes
i. Calculate (by hand) the probability of a win for the following game, and the proba- bility of a loss. Show your calculations.
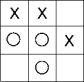
ii. Run the Na¨ıve Bayes classifier to confirm the prediction in item 2(b)i. What is the accuracy of the Na¨ıve Bayes classifier? Explain the results in the confusion matrix.
(c) k-NN
i. Find three instances in the dataset that are similar to the following game, and use the Jaccard coefficient to calculate (by hand) the predicted outcome for this game. Show your calculations.
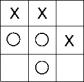
ii. What is the accuracy of the k-NN classifier? Explain the results in the confusion matrix.
3. Draw a table to compare the performance of J48, Na¨ıve Bayes and IBk using the summary measures produced by wEKA. Which algorithm does better? Explain in terms of wEKA’s summary measures. Can you speculate why?
Question 3: Regression [ 1+2+5 = 8 ]
Consider the dataset abs .arff available on moodle. This dataset contains continuous-valued economic attributes of a country, with the target variable being the unemployment rate. Additional documentation regarding these attributes appears in the arff file.
1. Perform a linear regression (Choose ● functions ● LinearRegression in wEKA) to learn a linear model of the unemployment rate as a function of the other variables. You can use the default parameters given in wEKA. What is the resultant regression function?
2. Using the resultant regression function, calculate by hand the Absolute Error for the year 1986.
3. Calculate the Mean Absolute Error (MAE) and Root Mean Square Error (RMSE) obtained by the regression function (you can use the excel spreadsheet provided on moodle). How is MAE different from RMSE? (do these functions emphasize different aspects of perfor- mance?)
Question 4: Clustering [ 6+6 = 12 ]
The dots in the following plot are data points to be clustered using the K-means algorithm. C1 and C2 indicate initial cluster centroids.
1. Show the first step of the K-means algorithm by indicating which data points belong to which cluster. Specifically, write the names of the data points in the cluster whose centroid is C1, and the names of the datapoints in the cluster whose centroid is C2.
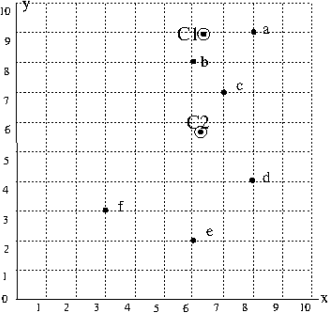
2. Show the next step of the K-means algorithm by writing the approximate x, y coordinates of the new class centroids; and entering the names of the data points in each cluster.
2023-05-21