Learning outcomes assessed
The learning outcomes assessed are:
• develop, validate, evaluate, and use effectively machine learning models
• apply methods and techniques such as decision trees and ensemble algorithms
• extract value and insight from data
• implement machine - learning algorithms in R
Instructions
In order to submit, copy all your submission files into a directory, e.g., DA, on the server linux and run the script
submit Coursework DA
from the parent directory. Choose CS5100 or CS4100, as appropriate, and Assignment (= exercise) 2 when prompted by the script. You will receive an automatically generated e-mail with a confirmation of your submission. Please keep the e - mail as a submission receipt in case of a dispute; it is your proof of submission. No complaints will be accepted later without a submission receipt. If you have not received a confirmation e - mail, please contact the IT Support team.
You should submit files with the following names:
• BDS.R should contain your source code for boosted decision stumps (these can be split into fifiles such as BDS1.R for task 1, BDS2.R for task 2, and BDS3.R for task 3); please avoid submitting unnecessary fifiles such as old versions, back - up copies made by the editor, etc. ;
• report. pdf should contain the numerical results and (optionally) discussion.
The files you submit cannot be overwritten by anyone else, and they cannot be read by any other student. You can, however, overwrite your submission as often as you like, by resubmitting, though only the last version submitted will be kept. Submissions after the deadline will be accepted but they will be automatically recorded as late and are subject to College Regulations on late submissions.
The deadline for submission is Friday, 29 November, 17:00. An extension can only be given by the academic advisor (and in some cases by the office, but not by the lecturer)

Tasks
You are to implement decision stumps (DS) and boosted decision stumps (BDS) for regression. As explained in Chapter 6, decision stumps are decision trees with one split. Decision trees are covered in Chapter 1 and Lab Worksheet 2. Boosting is covered in Chapter 6 and Lab Worksheet 5. (See also Chapter 8 of [1] . ) For further details, see below.
Your programs should be written in R. You are not allowed to use any existing implementations of decision trees or boosting in R, or any other language, and should code DS and BDS from fifirst principles.
You should apply your DS and BDS programs to the Boston data set to predict medv given lstat and rm. (In other words, medv is the label and lstat and rm are the attributes) . There is no need to normalize the attributes, of course. Split the data set randomly into two equal parts, which will serve as the training set and the test set. Use your birthday (in the format MMDD) as the seed for the pseudorandom number generator. The same training and test sets should be used throughout this assignment. Answer the following questions:
1. Train your DS implementation on the training set. Find the MSE on the test set. Include it in your report.
2. Train your BDS implementation on the training set for learning rate η = 0.01 and B = 1000 trees. Find the MSE on the test set. Include it in your report.
3. Plot the test MSE for a fixed value of η as a function of B ∈ [1, B0] (the number of trees) for as large B0 as possible. Do you observe overfitting? Include the plot and answer in your report.
Feel free to include in your report anything else that you find interesting .
Decision stumps
Decision trees in general are described on slides 45– 50 of Chapter 1. Decision stumps are a special case corresponding to stopping after the first split. The description below is a streamlined (for this special case and for our data set) version of the general description.
The DS algorithm A decision stump is specified by its attribute (lstat or rm) and the threshold s.
(Consider, e.g., s= 1.8, 1.9,. . ., 37.9 in the case of lstat and s= 3.6, 3.7, . . . , 8.7 in the case of rm. ) The training RSS of a decision stump (lstat, s) is
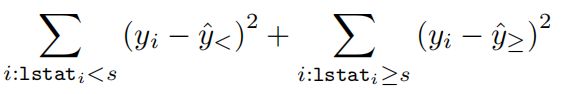
where both sums are over the training observations,ˆy< is the mean label yi for the training observations satisfying lstati < s and ˆy≥ is the mean label yi for the training observations satisfying lstati ≥ s. The training RSS of a decision stump (rm, s) is defifined similarly . Find the decision stump with the smallest training RSS. This will be your prediction rule.
Suppose the decision stump with the smallest training RSS is (rm, s) (i.e. , this is your prediction rule) . The test RSS of this decision stump is
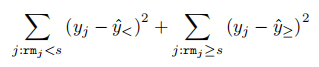
where both sums are over the test observations, ˆy< is the mean label yi for the training observations satisfying rmi < s, and ˆy≥ is the mean label yi for the training observations satisfying rmi ≥ s. The test MSE (to be given in your report) is the test RSS divided by the size m of the test set.
Remark. Using both RSS and MSE is somewhat superfluous, but both mea sures are standard. Remember that the test MSE is the test RSS divided by the size m of the test set, and the training MSE is the training RSS divided by the size n of the training set.
Boosted decision stumps
Boosting regression trees is described on slide 23 of Chapter 6. The description below is a more detailed version of that description.
The BDS algorithm
1. Setˆf(x) :=0 and ri
:=yi for all i= 1,. . ., n.
2. For b= 1, 2,. . ., B, repeat:
(a) fit a decision stumpˆf b to the training data (xi
, ri), i = 1, . . . , n; in other words, ˆ f b is the decision stump with the smallest training MSE
(b) remember the decision stump ˆf b for future use
(c) update ˆ f by adding in a shrunken version of the new stump: ˆ f(x) := ˆ f(x) + η ˆ f b(x) (but we do not really need this!)
(d) update the residuals: ri
:= ri-ηˆfb(xi), i= 1,. . ., n
The prediction rule is
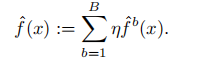
To compute the test MSE (to be given in your report) of this prediction rule use the formula
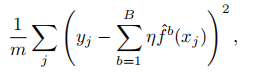
where the sum is over the test set and m is the size of the test set.
Marking criteria
To be awarded full marks you need both to submit correct code and to obtain correct results on the given data set. Even if your results are not correct, marks will be awarded for correct or partially correct code (up to a maximum of 75%) . Correctly implementing decision stumps (Task 1) will give you at least 50%.
References
[1] Gareth James, Daniela Witten, Trevor Hastie and Robert Tibshirani. An Introduction to Statistical Learning with Applications in R, Springer, New York, 2013.