ECE340-440-Homework 2: Markov Decision Processes
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
ECE340-440-Homework 2: Markov Decision Processes
Answer all questions
Write down the Markov Decision Process Formulation for the following problems. Clearly specify each element of the process including {S (States), A (Actions), P (Transition Probability matrices), R (reward function)}. Identify if the MDP has a terminal state, or a finite horizon.
1. In the discrete maze below, at each step the agent can choose to move up, down, left or right. If there is no wall, the agent moves onto the corresponding empty space. If there is a wall, the agent stays in the same space. The starting space is marked in GREEN, and the destination in RED. Write the agent’s problem as an MDP. Since the state space might be large, you may fill out the transition probability matrices in an Excel sheet, and upload it as a separate file (Write all matrices in a single workbook).
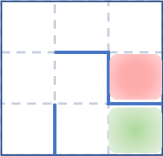
Figure 1: Maze on a Grid: The starting space is marked in GREEN, and the destination in RED
Evaluate the policy that randomly chooses to go up, down, left or right with probability ![]() each. Use value iteration to solve for the optimal policy. Upload any relevant code or Excel sheet.
each. Use value iteration to solve for the optimal policy. Upload any relevant code or Excel sheet.
2. We model a Tic-Tac-Toe game with one notable change. At each time, a player flips a fair coin, and places an X if the coin turns up Heads, and places a O if it turns up Tails. Write down the MDP for the game, if the opposing player (who also flips a coin to choose X or O) makes a uniformly random choice of play– In other words, if there are m empty spots on the board, the opposing player will choose any one of them with equal probability (1/m).
3. An urn contains 3 Red and 3 Blue balls. At every step you decide whether to Pick a ball from the urn, or Stop the game. If you pick a Red ball, you gain a point. If you pick a Blue ball, you lose a point. A ball once picked cannot be placed back in the urn again. Model this game as an MDP. Propose a policy and evaluate its expected reward. It should be a policy that depends on the state, and not something trivial like a policy that stops the game at step one. (If you use code to evaluate the expected reward, then attach the code as a separate file, and in your solutions write an explanation on how you used the code to evaluate the policy, and what your expected reward is). Optional for ECE 340 Compute the optimal policy. If you use code, upload it with an explanation on how you used it.
4. (Dont use code) Consider an infinite horizon discounted MDP problem with two states (0 and 1), and two actions (A and B) such that, V = .5, the rewards
R0i(A) = 1,R0i(B) = 2,R1i(A) = 0,R1i(B) = 0,i = 1, 2.
and transition probabilities
P00(A) = 1/2,P00(B) = 1/4,P10(A) = 2/3,P10(B) = 1/3.
(a) Start with zero initial values and perform three steps of value iteration.
(b) What is the best policy following the third iteration.
(c) Compute the optimsal policy.
2023-03-17