Popular machine learning technique, i.e. Neural Networks
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
PART I (60 marks):
Task:
In this assignment, you are to implement a popular machine learning technique, i.e. Neural Networks, using Python. You will train and test a simple neural network with the datasets provided to you and experiment with different settings of hyper parameters. The datasets provided to you is a subset of the popular MNIST hand written digits database (URL) in which a sample of it is given below:

The training and test sets are provided to you together with this assignment in the following files:
Training samples: TrainDigitX.csv.gz
Training labels: TrainDigitY.csv.gz
Test samples: TestDigitX.csv.gz
Test labels: TestDigitY.csv.gz
Test samples with no labels provided: TestDigitX2.csv.gz
There are 50,000 training samples in TrainDigitX.csv.gz, 10,000 test samples in
TestDigitX.csv.gz, and another 5,000 test samples in TestDigitX2.csv.gz. Each sample is a handwritten digit represented by a 28 by 28 greyscale pixel image. Each pixel is a value between 0 and 1 with a value of 0 indicating white. Each sample used in the dataset (a row in TrainDigitX.csv, TestDigitX.csv, or TestDigitX2.csv.gz) is therefore a feature vector of length 784(28x28=784). TrainDigitY.csv.gz and TestDigitY.csv.gz provide labels for samples in TrainDigitX.csv.gz and TestDigitX.csv.gz, respectively. The value of a label is the digit it represents, e.g., a label of value 8 indicates the sample represents the digit 8. Besides the python implementation, you should also submit a written document discussing about your implementation and experiments, which should address the following two parts, Part (a) and Part (b). Marks allocated to each part are as follows: Part (a) – 20 marks, Part (b) - 40.
You should hand in your well commented python scripts and the prediction files
PredictTestY.csv.gz and PredictTestY2.gz explaining your implementation and experimental results with respect to Part 1 to Part 2.
Part (a): Manual calculation for a small neural network
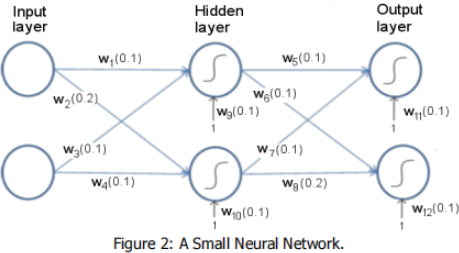
Before writing your code, you should work on the neural network shown in Fig. 2 by hand. The small network has two neurons in the input layer, two neurons in the hidden layer and two neurons in the output layer. Weights and biases are marked on the figure. W9, w10, w11, w12 are weights for the bias term. Note that there are no biases for the neurons in the input layer. There are two training samples: X1 = (0.1, 0.1) and X2 = (0.1, 0.2). The label for X1 is 0, so the desired output for X1 in the output layer should be Y1 = (1, 0). The label for X2 is 1, so the desired output for X2 in the output layer should be Y2 = (0, 1). You should update the weights and biases for this small neural net using stochastic gradient descent with backpropagation. You should use batch size of 2 and a learning rate of 0.1. You should update all the weights and biases only once MANUALLY. Show your working and results in your report. And then use this as a test case to test your code which you will implement in Part (b). (20 marks for Part (a))
Part (b): Implementation in Python
Your task is to implement a neural network learning algorithm that creates a neural network classifier based on the given training datasets. Your network has 3 layers: an input layer, one hidden layer and an output layer. You should name your main file as neural_network.py which accepts seven arguments. Your code should be run on the command line in the following manner:
> python neural_network.py NInput NHidden NOutput TrainDigitX.csv.gz
TrainDigitY.csv.gz TestDigitX.csv.gz PredictDigitY.csv.gz
where the meaning of each arguments are:
NInput: number of neurons in the input layer
NHidden: number of neurons in the hidder layer
NOutput: number of neurons in output layer
trainset.csv.gz: the training set
trainset_label.csv.gz: labels associated with the training set
testset.csv.gz: the test set
testset_predict.csv.gz: predicted labels for the test set
You should set the default value of number of epochs to 30, size of mini-batches to 20, and learning rate to 3, respectively.
Note: you can use numpy.loadtxt() and numpy.savetxt() methods to read from or write to a csv.gz. There is no need to un-compress the file before use. To making plots, you can use the Python library ‘matplotlib’.
The nonlinearity used in your neural net should be the basic sigmoid function:
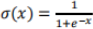
The main steps of training a neural net using stochastic gradient descent are:
• Assign random initial weights and biases to the neurons. Each initial weight or bias is
a random floating-point number drawn from the standard normal distribution (mean
0 and variance 1).
• For each training example in a mini-batch, use backpropagation to calculate a gradient estimate, which consists of following steps:
1. Feed forward the input to get the activations of the output layer.
2. Calculate derivatives of the cost function for that input with respect to the activations of the output layer.
3. Calculate the errors for all the weights and biases of the neurons using backpropagation.
• Update weights (and biases) using stochastic gradient descent:
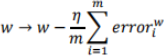
where m is the number of training examples in a mini-batch, is the error of weight w for input i, and is the learning rate.
• Repeat this for all mini-batches. Repeat the whole process for specified number of
epochs. At the end of each epoch evaluate the network on the test data and display
its accuracy.
For this part of the assignment, use the quadratic cost function:
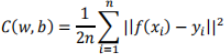
where
w: weights
b: biases
n: number of test instances
xi: ith test instance vector
yi: ith test label vector, i.e. if the label for xi is 8, then yi will be
[0,0,0,0,0,0,0,0,1,0]
f(x): Label predicted by the neural network for an input x
For this hand written digits recognition assignment, we will encode the output (a number between 0 and 9) by using 10 output neurons. The neuron with the highest activation will be taken as the prediction of the network. So the output number y has to be represented as a list of 10 numbers, all of them being 0 except for the entry at the correct digit.
You should do the following:
1. Create a neural net of size [784, 30, 10]. This network has three layers: 784 neurons in the input layer, 30 neurons in the hidden layer, and 10 neurons in the output layer. Then train it on the training data with the following settings: epoch = 30, minibatch size = 20, = 3.0 Test your code on the test data (TestDigitX.csv.gz) and make plots of test accuracy vs epoch. Report the maximum accuracy achieved. Also run your code with the second test set (TestDigitX2.csv.gz) and output your predictions to PredictDigitY2.csv.gz. You should upload both PredictTestY.csv.gz and PredictTestY2.gz in your submission. (10 marks)
2. Train new neural nets with the same settings as in (1) above but with = 0.001, 0.1,
1.0, 10, 100. Plot test accuracy vs epoch for each on the same graph. Report the
maximum test accuracy achieved for each . Remember to create a new neural net each time so its starts learning from scratch. (Different learning rates- 10 marks)
3. Train new neural nets with the same settings as in (1) above but with mini-batch sizes = 1, 5, 10, 20, 100. Plot maximum test accuracy vs mini-batch size. Which one achieves the maximum test accuracy? Which one is the slowest? (Different batch sizes- 10 marks)
4. Try different hyper-parameter settings (number of epochs, , and mini-batch size, etc.). Report the maximum test accuracy you achieved and the settings of all the hyper
parameters. (Different hyper-parameter settings- 10 marks)
Note: Once you implemented your neural network learning algorithm, you should compare its computed values with the manually calculated values you did by hand in Part 1 for the small network shown in Fig. 2 to verify its correctness. To verify your implementation, make sure that the weights and biases output by the learned network after one epoch are the same as those you calculated manually in Part 1. Train this small network for 3 epochs and output the weights and biases after each epoch. Report this in your report. Note that you need to do this before you run your network on the MNIST dataset.
PART II (40 marks):
Question 1 (10 marks):
(a) Critically discuss the main difference between k-Means clustering and Hierarchical
clustering methods. Illustrate the two unsupervised learning methods with the help of an example. (2 marks)
(b) Consider the following dataset provided in the table below which represents density and sucrose content of different categories of substances:

Assuming the value of Clusters to be k = 2, randomly selected as the initial mean vectors from the data set in table above:
i) Implement k-Means clustering in python to allocate individual dataset points to one
of the two clusters. Use greedy strategy to find an optimised approximate final
solution. (6 marks)
ii) Use graphical representation to show the clusters and their associated datapoints.
You do not need to write a program for this but only need to show it using a 2D
graph in your report. (2 marks)
Question 2 (10 marks):
(a) With the help of an example, critically analyse the impact of size of the neuron
neighbourhood in self-organising maps (SOM). Based on your analysis, discuss the best approach for the selection of the neuron neighbourhood size. (2 marks)
(b) Let us assume that the initial weights of neurons n1, n2, n3 and n4 be w1=(0.45,0.89), w2=(0.55,0.83), w3=(0.95,0.32) and w4=(0.62,0.78) respectively. The neurons n1, n2, n3 and n4 are located at the coordinate positions of (0,0), (0,1), (1,0) and (1,1) respectively.
The network takes two dimensional input vector (x1,x2) with values of (3,1). Let
w_i=(w1_i,w2_i) be the weight for the neuron i. Assume the neighbourhood radius = 0.6, and the learning rate = 0.5 (which stays constant throughout). Using the information provided:
i) Draw a diagram to represent the nodes, their weights and input vectors in the
cartesian coordinate system. (2 marks)
ii) Write SOM algorithm to compute the above data. You do not need to write a routine
in python, a pseudocode in your report would be sufficient. (3 marks)
iii) Compute the data to its first iteration. Also, update weights of the nodes after the
first iteration is complete. (3 marks)
Question 3 (10 marks):
In Macao, a casino has VIP gamblers. On each day , one of the gamblers visit the casino and plays round of blackjack for that day and wins of those rounds. The probability that a VIP gambler wins a round of blackjack, which ranged between 0 and 1, is denoted as . Unfortunately, casino refuses to disclose which VIP gambler plays on which day. Hence, on certain day , if the VIP gambler played round of blackjack, the probability that the gambler will win of those rounds is represented by a binomial distribution of 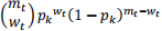
The expectation maximization (EM) algorithm is applied to estimate the likelihood a VIP gambler will win out of rounds.
(a) State the usage of E step and M step for the EM algorithm (4 marks)
(b) Express the likelihood for any given iteration in terms of parameters from previous
iteration for the E-step update. (6 marks)
Question 4 (10 marks):
Alpha Go was developed by Google DeepMind. The program gained traction when it has beaten two world-class professional Go players. For instance, Alpha Go relies on reinforcement learning to train and improve itself.
(a) State the four fundamental elements of the reinforcement learning environment. (4 marks)
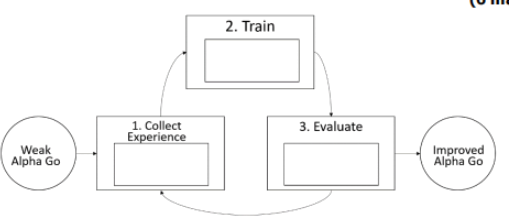
(b) A new Alpha Go has been developed. At this stage, it is weak. The bot needs to be
trained before it can be released. Neural network is implemented during the training. Explain the reinforcement learning flow adopted by Alpha Go in the flow chart given
below. (6 marks)
2023-03-16
You are to implement a popular machine learning technique, i.e. Neural Networks, using Python.