Homework 7 | JSON and NoSQL
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
Homework 7 | JSON and NoSQL
Objectives: To write queries over the semi-structured data model. To manipulate semi-structured data in JSON and use a NoSQL database system (AsterixDB).
What to turn in:
A single file for each question (q1.sqlp, q2.sqlp, … ). It should contain commands executable by SQL++, and any text answers should be comments in the file (start comments with -- like SQL).
For the appropriate questions, leave your runtime in a comment.
Resources
● data: which contains mondial.adm (the entire dataset), country, mountain, and sea (three subsets) (Note: this is named hw7.zip, but it is properly for hw6)
Assignment Details
In this homework, you will write SQL++ queries over the semi-structured data model implemented in AsterixDB. Asterix is an Apache project on building a DBMS over data stored in JSON or ADM files.
Mondial Dataset
You will run queries over the Mondial database , a geographical dataset aggregated from multiple sources. As is common in real-world aggregated data, the Mondial dataset is messy; the schema is occasionally inconsistent, and some facts may conflict. We have provided the dataset in ADM format, converted from the XML format available online, for use in AsterixDB.
Setting up AsterixDB
1. Download and install AsterixDB. Download the file asterixdb-0.9.6 and unzip it anywhere you'd like.
2. (extra step for some users:) You need to install the Java 8 SE Development Kit if you don’t already have it. Follow this link to the download for your system. Many people will have this already if you’ve installed the tools for writing Java programs. On Windows, just installing the JDK should be enough. For Mac you may need to do some additional steps as described here.
3. Start an instance of AsterixDB using the start-sample-cluster.sh (or .bat if you are on Windows) located in the opt/local/bin folder.
4. When your AsterixDB instance is running you can enter the query interface by visiting 127.0.0.1:19001 in your favorite web browser. It may take a few minutes before you can access the page, while the instance starts up.
5. Download the geographical data from the link in the resources above. The data are JSON data files; you can inspect them using your favorite text editor.
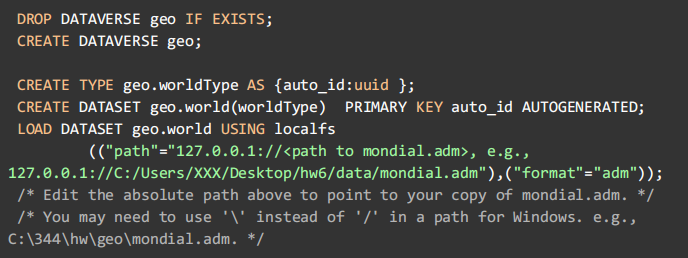
6. Create a dataverse of Mondial data. Copy and paste the text below in the Query box of the web interface. Edit the <path to mondial.adm>. Then press Run:
7. Alternatively, you can use the terminal to run queries rather than the web interface. After you have started Asterix, put your query in a file (say q1.sqlp), then execute the query by typing the following command in terminal:

This will print the output on the screen. If there is too much output, you can save it to a file

8. To reference the geodatabase, use the statement USE geo; before each of your queries to declare the geo namespace. Alternatively, prefix every dataset with geo. Try this query to see if things are running correctly:

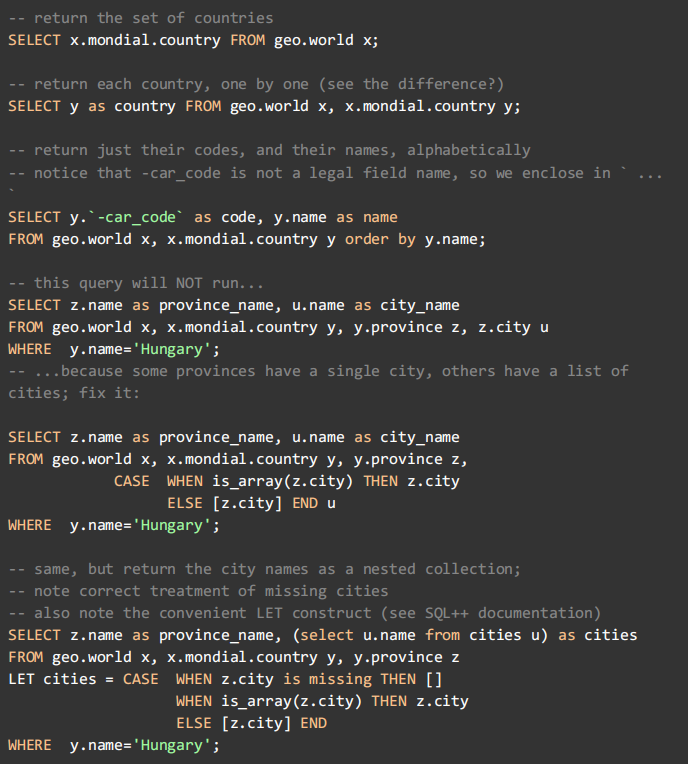
9. For practice, run, examine, modify these queries. They contain useful templates for the questions on the homework: make sure you understand them.
10. To shutdown Asterix, simply run stop-sample-cluster.sh in the terminal. The script is located in opt/local/bin (or opt\local\bin\stop-sample-cluster.bat on windows).
Problems (100 points)
Notes:
● For all questions asking to report free response-type questions, please leave your responses in comments
● The order of the keys can differ due to how AsterixDB works internally.
● To count rows, you can copy the entirety of the UI output into a text editor and note the line number.
Use only the mondial.adm dataset for problems 1-9.
1. Retrieve the names of all cities located in Peru, sorted alphabetically. Name your output attribute city.
[Result Size: 30 rows of {"city":...}]
2. For each country, return its name, its population, and the number of religions sorted
alphabetically by country. Report 0 religions for countries without religions. Name your output attributes country, population, num_religions.
[Result Size: 238 rows of {"num_religions":..., "country":..., "population":...}]
3. For each religion return the number of countries where it occurs; order them in decreasing number of countries.
Name your output attributes religion, num_countries.
[Result size: 37 of {"religion':..., "num_countries":...}]
4. For each ethnic group, return the number of countries where it occurs, as well as the total population world-wide of that group. Hint: you need to multiply the ethnicity’s percentage with the country’s population. Use the functions float(x) and/or int(x) to convert a string to a float or to an int.
Name your output attributes ethnic_group, num_countries, total_population. You can leave your final total_population as a float if you like.
[Result Size: 262 of {"ethnic_group":..., "num_countries":..., "total_population":...}]
5. Find all countries bordering two or more seas. Here you need to join the "sea" collection with the "country" collection. For each country in your list, return its code, its name, and the list of bordering seas, in decreasing order of the number of seas.
Name your output attributes country_code, country_name, seas. The attribute seas should be a list of objects, each with the attribute sea.
[Result Size: 74 rows of {"country_code":..., "country_name":..., "seas": [{"sea":...}, {"sea":...}, ...]}]
Submission Instructions
Write your answers in a file for each question: q1.sqlp, … , q5.sqlp to Gradescope. For the appropriate questions, leave your runtime in a comment.
2023-03-15