COMPSCI 3DM3 Winter 2023 Introduction to Data Mining Assignment 3
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
COMPSCI 3DM3 Winter 2023
Introduction to Data Mining
Assignment 3
Total marks: 100 marks (5% of the final grade)
Assignment 3.1 (40 marks)
Consider a 1-dimensional data set with the three “natural” clusters {1, 2, 3, 4, 5}, {8, 9, 10, 11, 12} and {24, 28, 32, 36, 40}. Apply the k-means algorithm and show the resulting clusters and cluster centroids for every iteration. (We are assuming that ties are broken by assigning an object to the first of the closest centroids.)
a) Start with initial centroids of 1, 11, and 28.
a- 1) What are the centroids and clusters for each iteration? (8 marks)
a-2) Does k-means correctly find the natural clusters? (2 marks)
b) Start with initial centroids of 1, 2, and 3.
b- 1) What are the centroids and clusters for each iteration? (20 marks)
b-2) Does the algorithm detect the correct clusters? (5 marks)
b-3) Comparing the results of a) and b), what does this tell you? (5 marks)
Assignment 3.2 (60 marks)
We want to cluster categorical data, i.e. data that have categorical attribute domains. The k-medoid algorithm can be applied to any datasets with a given pair-wise distance function and, therefore, is applicable also to categorical data. The k-means algorithm, on the other hand, is much more efficient than the k-medoid algorithm, but it requires numeric data. The task of this assignment is to develop an analogion to the k-means algorithm for categorical data. We assume the following distance function for pairs of categorical objects:
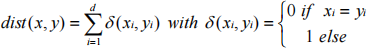
a) What is the analogion m for the means of a cluster C for categorical data? Note that m must be computable by scanning the set of objects of C once (similar to the computation of the cluster means). (10 marks)
[Hint1: If a concept A is in analogy another concept B, then A is said to be an analogion for B] [Hint2: an analogion m for the means of a cluster C refers to a new definition of the means of a cluster of categorical data, where the original definition of cluster centre used by k-means does not work anymore.]
b) Prove that m according to your definition in a) is the object minimizing the following cluster cost. (25 marks)
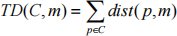
c) Is the cluster representative m as defined in a) unique? (5 marks)
d) Describe the major differences that distinguish the whole resulting algorithm for clustering categorical data from the standard k-means algorithm. (20 marks)
2023-03-10