STAT 380 Data Science Through Statistical Reasoning and Computation Spring 2023
Hello, dear friend, you can consult us at any time if you have any questions, add WeChat: daixieit
STAT 380 Data Science Through Statistical Reasoning and Computation
Spring 2023
Exam 1 - Take-home
Acknowledgements: By uploading your work for the take-home in Canvas, you are acknowledging the following:
• I acknowledge that giving help to any other person during the exam, receiving help from any other person during the exam, or working with any other person on exam problems while taking the exam is grounds for an academic integrity violation. "Any other person" refers to anyone NOTjust a classmate.
• I acknowledge that posting any content from this exam or posting any questions for help on this exam to any online site (e.g., StatExchange, CourseHero, Chegg, GroupMe, ChatGPT, etc.) is grounds for an academic integrity violation.
• I acknowledge that copying answers from any source is grounds for an academic integrity violation.
• I acknowledge that sharing any or all parts of this exam with any other person, classmate or otherwise, is grounds for an academic integrity violation.
Set up: (5 Points)
• Create a new R Markdown by going to FILE >> NEW FILE >> R Markdown.
• Modify the YAML header so that
o the title is STAT 380 Exam 1 Take-home
o there is a line for the author with your name specified
o there is a date
• Delete the default text.
• Add a Front Matter section. Use a level 2 heading and add libraries as needed. All library commands should be in the Front Matter section. Also, include any commands for reading in the dataset in the Front Matter section.
• Name the file LastnameFirstinitial_STAT380_Exam1TH.
• For each problem, you should add a level 2 heading with the task number (e.g., Problem 1 Part a, Problem 1 Part b, etc.). Then, write code and answer the questions as necessary.
Data: The problems on this exam use the file LifeExpectancyData.csv. The Global Health Observatory (GHO) data repository under World Health Organization (WHO) keeps track of the health status as well as many other related factors for all countries. LifeExpectancyData.csv combines the data from the WHO along with economic data from the United Nations website.
The dataset contains the following variables:
• Country
• Year
• Status – Indicates whether the county is a developed or a developing country
• Life.expectancy – The country’s life expectancy in years
• Adult.mortality – Number of adult deaths per 1000 population (adult = ages 15-60)
• Infant.deaths – Number of infant deaths per 1000 population
• Alcohol – Alcohol consumption per person (in liters)
• Percentage.expenditure – Expenditure on health as a percentage of Gross Domestic Product per capita(%)
• Hepatitis.B – Percentage of 1-year-olds immunized for Hepatitis B
• Measles – Number of reported cases by 1000 people
• BMI – Average Body Mass Index of entire population
• Under.five.deaths – Number of child (less than 5 years old) deaths per 1000 population
• Polio - Percentage of 1-year-olds immunized for Polio
• Total.expenditure – Percentage of total government expenditure that goes to health
• Diphtheria – Percentage of 1-year-olds immunized for Diphtheria tetanus toxoid and pertussis (DTP3)
• HIV.AIDS – Deaths per 1000 live births from HIV/AIDS (0-4 years)
• GDP – Gross Domestic Product per capita (in USD)
• Population – Population of the country
• Thinness. 10. 19.years – Percentage of children and adolescents (10- 19 years) exhibiting thinness
• Thinness.5.9.years – Percentage of children exhibiting thinness
• Income.composition.of.resources – Human Development Index in terms of income composition of resources (index ranging from 0 to 1)
• Schooling – Average number ofyears of schooling
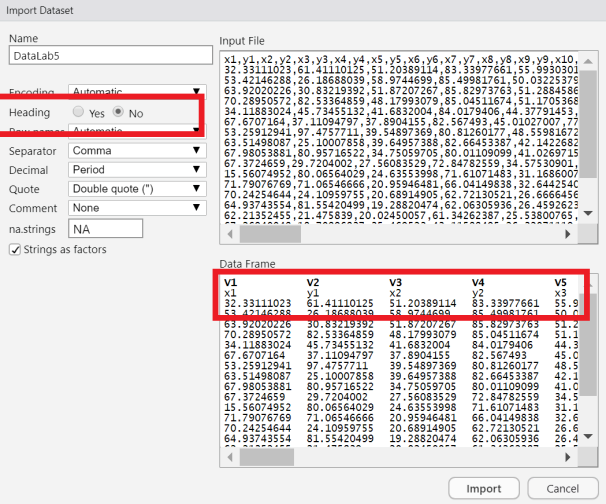
NOTE: When reading in this dataset, make sure the variables names are Country, Years, Status, etc. instead of V1, V2, V3, …
a. To solve this issue, click the box for Yes for Heading in the Import Dataset interface.
b. The image below, although unrelated to this dataset, demonstrates where to change the Heading option.
Problems:
1. (8 Points) Exploration. Suppose we are interested in understanding factors related to the life expectancy variable.
a. Read the variable descriptions and identify 3 variables that you believe will be associated with life expectancy. (Do not use Country or Year.) There is no right or wrong answer to this question; however, to answer this question, write a paragraph that identifies the 3 variables you have picked and explain your reasoning as to why you think the variables will related to life expectancy.
b. For each of the variables you have chosen, create an appropriate (and properly labeled) plot that shows the relationship between life expectancy and the variable. Then, write a sentence or two explaining what you have learned about the relationship based on the plot. NOTE: For this question, you should have 3 plots and 3 explanations.
c. Examine the data for Australia. (You can write code to explore or simply look through all of the columns.) Write a paragraph discussing concerns you have about the correctness of the data. Provide at least two specific examples of a value/variable that you think to be incorrect and explain your reasoning.
2. (12 Points) Prediction. Suppose we are interested in predicting the life expectancy as accurately as possible using Adult.mortality, Infant.deaths, GDP, Total.expenditure, BMI, and Status. The goal of this problem is to compare the predictive ability of a multiple linear regression model to that of a kNN regression based on test set performance. Both models should be based on the same variables.
a. Subset the data to only include the seven variables mentioned above and remove any observations with missing data (NA’s) in the seven variables.
b. Write a paragraph explaining the steps you will take to perform the analysis. This should include a description of the data processing that you plan to do, the decisions you will make regarding the training/testing split, how you plan to pick “k” in kNN, and the metric you will use to compare the predictive ability of the methods on the test set. (Unlike class where I tell you step-by-step what to do and what decisions to make, this question is trying to get you to articulate the steps/decisions.)
c. Implement the analysis described in Part b. Be sure to include a plot that can be used to justify your choice of “k” for kNN.
d. Based on your implementation, which model had better predictive ability based on the test set? Explain your reasoning. (Be sure to mention the value of “k” that you have chosen include values for test set performance in this explanation.)
3. ( 10 Points) Inference. Suppose we are interested in understanding the association between adult mortality, the country’s status (developing or developed), and life expectancy.
a. Starting with the full dataset, subset the data to only include the three variables mentioned above and remove any observations with missing data (NA’s) in the three variables.
b. Build a multiple linear regression model for life expectancy that uses adult mortality and status. Run the summary() function on the model, report the estimated equation, and interpret the coefficients (partial slopes) associated with adult mortality and status. Note, you do not have to perform a training/testing split for this problem.
c. Instead of a reporting a point estimate (single number) for the regression coefficient of Adult.mortality, we often use confidence intervals. In this problem, we will explore a computational procedure for estimate a 95% confidence interval for the coefficient of Adult.mortality. Remember that you can think of the confidence interval as a range of plausible values for the estimated quantity. Here is the logic:
i. Generate a bootstrap sample of the data. To do this, generate a random sample of n rows from a dataset of n rows by sampling with replacement.

ii. Build the model on the bootstrap sample (Train_boot) and store the estimated coefficient. The code below is helpful for extracting coefficients. The given code extracts the first estimated coefficient (the y-intercept). Changing the [1] to [2] extracts the second estimated coefficient (i.e., the first partial slope). And so on.

iii. Repeat this procedure a large number of times, say 1000 so that you have 1000 estimates of the coefficient.
iv. Find the values that cut off the middle 95% of the values. The code below shows how you would find the values that cut off the middle 95% of the values in the vector `beta_vec`.
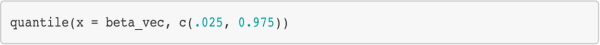
Instruction for Part c: Find a 95% confidence interval for the regression coefficient of Adult.mortality by implementing the procedure described above. Write a loop that repeats steps i. and ii. 1000 times. Set a seed (of your choice) before the loop., not inside the loop. You can place set.seed(NULL) after the loop (not inside). Once the loop is done, plot a histogram of the estimated values and perform step iv.
2023-03-05