COSC2002/2902 Computational Modelling
COSC2002/2902 Computational Modelling
Assignment — due Sunday May 30th, 11:59pm
The assignment consists of two questions. It is worth 10% of your total assessment for this Unit of Study. You will be marked on the correctness and quality of the code, as well as your written responses to the questions.
You should submit your assignment as a jupyter notebook through the Canvas submission portal.
Written responses to assignment questions should also be included in the jupyter notebook, using the ‘markdown’ option for a cell (so that your whole notebook can still be run without error). Check that your notebook runs before submission.
You are welcome to work in pairs. If submitting as a pair please both submit the notebook (with both your SIDs in the file name), so that Canvas records a submission for both members of the pair. If you submit this assignment with another student, you certify that you have both made a fair contribu-tion to it, and are happy to both receive the same mark.
Assignments that have simply been copied will not be accepted. Copying the work of another person without acknowledgement is plagiarism and contrary to University policies. By uploading your submission to Canvas, you are certifying that you have read and understood the University Academic Dishonesty and Plagiarism in Coursework Policy.
Question 1: Population models(10 marks)
Given the impact it has had on all our lives it seems we should have a go at modelling the spread of a virus through the community. We will also use this model as a basis for an exploration of two interacting populations (e.g. rabbits and sheep), seen earlier in the course in the ordinary differential equation context.
Let’s approach the virus problem in this way. Begin with a 2-dimensional grid of squares (the “world”). A number of healthy people are randomly distributed throughout the world, as well as one infected person. Each day, each person either stays still or moves one square up, down, right, or left. If an infected person spends a day on the same square as a healthy person, the healthy person becomes infected.
Parameters
The simulation should be initialized with four parameters: the size of the 2-dimensional world people inhabit (sidelength, default 40 squares per side), the maximum time to run the simulation for (maxtime, default 1000 days), the number of people (npeople, default 100), and the number of initially infected people (ninfected, default 1).
People
Each person will be associated with a number of pieces of information: (i) their x coordinate (an integer between 0 and the size of the world-1), (ii) their y coordinate (same), and (iii) their status (healthy or infected).
Simulation
The “simulation” consists of the calculations that occur inside the loop over time.
First, we need to figure out where people move to. For this, we’ll need an inner loop over people. At each timestep there are five options, corresponding to the four directions the person can move, and their current position (meaning they don’t move). If people move outside the world (x, y < 0 or x, y > sidelength-1), they come through the other side of the world (i.e. we shall assume we have periodic boundary conditions). So, a person who moves to x = −1 will instead move to x =sidelength-1.
Second, we need to figure out which people are infected, and which are not.
Third comes the tricky part: we need to handle infections. To do this, we can loop over just the infected people, then loop over all the healthy people. For each infected/healthy pair, we need to check whether the healthy person is occupying the same square as the infected person (i..e., their x and y coordinates are identical).
Plotting
Construct a scatter plot, where a dot shows the position of a healthy or infected person on the xy plane. Plot healthy people in blue and infected in red.
Questions
(1.1) Starting with the defaults specified above, what is the average length of time until the last person gets infected? Provide also an estimate of the uncertainty in your value.
(1.2) Averaging over many runs: Plot the number of infected people as a function of time.
(1.3) If you halve the size of the world (i.e., set sidelength=20), how does this change the time it takes until the last person is infected? Briefly discuss the real-world implications of this result.
(1.4) This model could also describe the interaction of two populations (e.g. rabbits and sheep). In this case, when two individuals meet there are a number of different options. When they are the same ‘species’ then there is a probability that a third (i.e. new) individual will appear at the same square. If they are different species then there is a probability that one or both individuals die. Modify your code so that it is now possible for new individuals to appear in your population. Starting with the same default grid size, but now 50 individuals in each species, we want to carry out a population simulation. Take the probability of a new individual appearing, and the probability of an individual dying when encountering the opposite species, to be the same for each species. Plot the population numbers versus time, and specify your chosen probabilities for the two parameters in the title of your plot (these must be both nonzero).
(1.5) Explore your model for different parameter values, and different values between species. De-scribe your main findings here. Do they agree with the findings of the ordinary differential equation model used earlier in the course? Justify your answer and comment on the validity of the model.
(1.6) COSC2902 ONLY Discuss how this model might be improved.
Question 2 Network models (10 marks)
Before covid-19, in Australia we had the bushfires. The bushfires of the 2019/2020 summer devastated the wilderness areas of the east coast of Australia. This event was accompanied by a correspondingly large response on social media, with discussion of the causes trending globally. In this question we shall use this event as a motivation to explore the spreading of content on a network.
Consider a network of users connected to followers (where a user may follow one of their follow-ers). This is known as a directed network, as information flows from a user to the user’s followers.
Consider the establishment of the network in the following way. Users in the network join one by one. When a user joins they initially randomly follow one other user in the network, and are followed by one other random user (which may be the same user). They also decide to follow one other user on the network. The probability of a particular user being selected as the new user being followed depends on the number of followers that user has already. The probability Pi that user i is chosen as the user to be followed is given by:
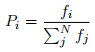
where fi is the number of followers user i has already and the sum on the bottom is the total number of follower connections between the N members of the network. Note, in this model it is possible for the randomly selected user and the user selected based on popularity to be the same.
Let’s now consider the user behaviour. At any given time step one user is randomly chosen in the network. This user may generate new content with some probability µ, or ‘retweet’ what they last saw with probability 1 − µ. A user will only see tweets coming from users they are following.
(2.1) Set up a directed network for 100 users, following the rules above. Plot a histogram of the number of followers per member, i.e. a histogram where the bin edges define the number of followers and the numbers in the bins are the number of users with this many followers. What sort of distribution is this? What sort of network is this? Justify your answers.
(2.2) Now let’s set up the simulation. Use the rules given in the introduction, with the following addition: if a chosen user has not yet seen any other content then they will generate new content with a probability of 1. Run your simulation on your network of 100 users with µ = 0.1 for 1000 time steps. Plot the number of unique messages currently in the network (i.e. currently visible to users in the network), as a function of time.
(2.3) Let’s have a look now at some real data. Download the file ‘daily climate hashtag counts.zip’ from Canvas. This contains around 100 csv files each containing a list of hashtags and their frequencies by day, over the period spanning the bushfire event. Read in this data and create two plots. One showing the total number of hashtags used each day versus date (the number of ‘tokens’), the second showing the number of different types of hashtags used per day versus date (the number of ‘types’). Comment on your plot, and compare the plot to the output from your model. Is there any agreement between the two?
(2.4) COSC2902 ONLY Explore the model for different values of µ. Are there different regimes of behaviour? Can the model help us to explain or understand any of the data?
2021-05-18