CMT655 Manipulating and Exploiting Data
Cardiff School of Computer Science and Informatics
Module Code: CMT655
Module Title: Manipulating and Exploiting Data
Lecturer: Dr Luis Espinosa-Anke
Assessment Title: Course Portfolio
Assessment Number: 1
Date Set: Friday 26th March 2021
Submission Date and Time: May 31st 2021 9:30
Return Date: June 30th 2021
This assignment is worth 100% of the total marks available for this module. If coursework is submitted late (and where there are no extenuating circumstances):
1 If the assessment is submitted no later than 24 hours after the deadline, the mark for the assessment will be capped at the minimum pass mark;
2 If the assessment is submitted more than 24 hours after the deadline, a mark of 0 will be given for the assessment.
Your submission must include the official Coursework Submission Cover sheet, which can be found here:
https://docs.cs.cf.ac.uk/downloads/coursework/Coversheet.pdf
Submission Instructions
Your coursework should be submitted via Learning Central by the above deadline. It consists of a portfolio divided in three assessments.
Assessment (1) consists of a set of exercises. The final deliverable consists of two jupyter notebooks.
Assessment (2) is a machine-learning powered web service which is able to train, evaluate and run predictions on unseen data, as well as storing model configuration and results in a database. The deliverable is a zip file with the application source code, a README.txt file and (optionally) a requirements.txt file which lists dependencies and versions the app would require to run.
Assessment (3) is a reflective report (up to 2,000 words) describing solutions, design choices and a reflection on the main challenges and ethical considerations addressed during the development of solutions for assessments (1) and (2).
You have to upload the following files:
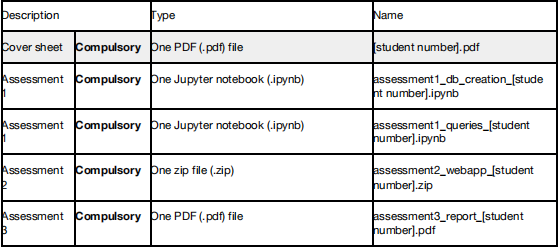
Any deviation from the submission instructions above (including the number and types of files submitted) may result in a mark of zero for the assessment or question part.
Assignment
In this portfolio, students demonstrate their familiarity with the topics covered in the module via three separate assessments.
Deliverable
Assessment 1
The deliverable for Assessment 1 consists of 2 jupyter notebook (.ipynb) files. They will be submitted with all the output cells executed in a fresh run (i.e., Kernel -> Restart and run all). 20 marks.
Assessment 2
The deliverable for Assessment 2 will be a zip file containing the webapp code, a README.txt and an optional requirements.txt file, which will list the dependencies the app requires. 25 marks.
Assessment 3
The deliverable for Assessment 3 will be a PDF file based on the .docx template provided for this assessment in the starter package, available at Learning Central. 55 marks.
Assessment 1
In Assessment 1, students solve two main types of challenges. These challenges are: (1) data modeling and (2) database querying.
DATA MODELING AND QUERYING (20 Marks)
assessment1_db_creation_[student number].ipynb
assessment1_queries_[student number].ipynb
1. Data modeling (8 marks)
You are given an initial .csv dataset from Reddit (data_portfolio_21.csv, available in the starter package in Learning Central). This data dump contains posts extracted from Covid-related subreddits, as well as random subreddits. Your first task is to process this dump and design, create and implement a relational (MySQL) database, which you will then populate with all the posts and related data.
This dataset has information about three entities: posts, users and subreddits. The column names are self-explanatory: columns starting with the prefix user_describe users, those starting with the prefix subr_ describe subreddits, the column subreddit is the subreddit name, and the rest of the columns are post attributes (author, post date, post title and text, number of comments, score, favorited by, etc.).
What to implement: Start from the notebook assessment1_db_creation_[student number].ipynb, replacing [student number] with your student number. Implement the following (not necessarily in this order):
-- Python logic for reading in the data. [2 marks]
-- SQL code for creating tables. [3 marks]
-- SQL code for populating tables. [3 marks]
Use comments or markdown along the way to explain how you dealt with issues such as missing data, non-standard data types, multivalued columns, etc. You are not required to explain the database design (normalization, integrity, constraints, etc) process in this notebook, as there is a dedicated part of the report in Assessment 3 for this. However, you can include pointers to design choices for facilitating the understanding of your implementation.
All your code should be self-contained in Python code, and therefore you will have to rely on a MySQL library for executing SQL statements and queries. Please use pymysql, the one we have used in class.
You should submit your notebook with all the cells executed, from start to finish, in a fresh run (i.e., first cell number should be [1], second [2], etc.). You can achieve this by selecting Kernel -> Restart and run all. At the end of the run, your notebook should have populated a database in the university server which you will have created exclusively for this coursework.
2. Querying (12 marks)
You are given a set of questions in natural language, for which you must implement queries to find the answer. While the queries will be answered in the provided jupyter notebook, they will have to be written in SQL, i.e., you cannot use Python to solve them.
What to implement: Start from the notebook assessment1_queries_[student number].ipynb, replacing [student number] with your student number. All the logic should be contained inside the provided (empty) functions. Then, a call to each function should show the output of these queries. You are also required to submit your notebook after a fresh run (Kernel -> Restart and run all).
The questions are:
1 - Users with highest scores over time [0.5 marks]
● Implement a query that returns the users with the highest aggregate scores (over all their posts) for the whole dataset. You should restrict your results to only those whose aggregated score is above 10,000 points, in descending order. Your query should return two columns: username and aggr_scores.
2 - Favorite subreddits with numbers but not 19 [0.5 marks]
● Implement a query that returns the set of subreddit names who have been favorited at least once and that contain any number in their name, but you should exclude those with the digit '19', as we want to filter out COVID-19 subreddit names. Your query should only return one column: subreddit.
3 - Most active users who add subreddits to their favorites. [0.5 marks]
● Implement a query that returns the top 20 users in terms of the number of subreddits they have favorited. Since several users have favorited the same number of subreddits, you need to order your results, first, by number of favourites per user, and secondly, alphabetically by user name. The alphabetical order should be, first any number, then A-Z (irrespective of case). Your query should return two columns: username and numb_favs.
4 - Awarded posts [0.5 marks]
● Implement a query that returns the number of posts who have received at least one award. Your query should return only one value.
5 - Find Covid subreddits in name and description. [1 mark]
● Implement a query that retrieves the name and description of all subreddits where the name starts with covid or corona and the description contains covid anywhere. The returned table should have two columns: name and description.
6 - Find users in haystack [1 mark]
● Implement a query that retrieves only the names of those users who have at least 3 posts with the same score as their number of comments, and their username contains the string meme anywhere. Your returned table should contain only one column: username.
7 - Subreddits with the highest average upvote ratio [1 mark]
● Implement a query that shows the 10 top subreddits in terms of the average upvote ratio of the users that posted in them. Your query should return two columns: subr_name and avg_upv_ratio.
8 - What are the chances [1 mark]
● Implement a query that finds those posts whose length (in number of characters) is exactly the same as the length of the description of the subreddit in which they were posted on. You should retrieve the following columns: subreddit_name, posting_user, user_registered_at, post_full_text, post_description and dif (which should show the difference in characters between the subreddit description and the post.
9 - Most active December 2020 days. [1 mark]
● Write a query that retrieves only a ranked list of the most prolific days in December 2020, prolific measured in number of posts per day. Your query should return those days in a single-column table (column name post_day) in the format YYYY-MM-DD.
10 - Top 'covid'-mentioning users. [1 mark]
● Retrieve the top 5 users in terms of how often they have mentioned the term 'covid' in their posts. Your query should return two columns: username and total_count. You will consider an occurrence of the word 'covid' only when it appears before and after a whitespace (i.e.,
covid ) and irrespective of case (both Covid and covid would be valid hits).
11 - Top 10 users whose posts reached the most users, but only in their favorite subreddits. [2 marks]
● Write a query to retrieve a list of 10 users sorted in descending order by the number of users their posts reached, considering only the subset of users belonging to their favourite subreddits. Your query must return only one column: username.
12 - Users with high score for their posts. [2 marks]
● Retrieve the number of users with an average score for their posts which is higher than the average score for the posts in our dataset. Your query should return only one result, under the column result.
Assessment 2
In Assessment 2, you implement a Flask application which manages a machine-learning based text classifier and speaks to both MongDB and MySQL databases.
WEBAPP (25 Marks)
assessment2_webapp_[student number].zip
In this assessment the goal is to set up a web service based on Flask which will sit on top of the database you built in Assessment 1, and will have a machine learning component. Specifically, the app will have several functionalities for training, evaluating and deploying a covid-or-not classifier, which will take as input a message posted in social media (e.g., Reddit), and predicts whether it is about Covid-19 or not.
What to implement: You will pull your data from the MySQL database that you implemented in Assessment 1. Then, your task is to develop a web application based on Flask which will have the following functionalities:
a) Run a classification experiment and store results, models and configuration in a MongoDB database;
b) Retrieve results for the experiments done so far, ranked based on a criterion of your choice; and
c) Perform inference, i.e., given a piece of text provided by the user, predict whether it is about Covid-19 or not.
You are provided with an ‘empty’ skeleton which contains starter HTML and Python code. Your task is to implement the backend logic following the detailed instructions below. The provided skeleton has an index.html page which has the layout shown in Figure 1:

Then, your task will be to implement the backend logic that is triggered when each of the three buttons shown in Figure 1 are clicked on. The logic corresponding to each of these buttons is explained in detail below.
1. Run a classification experiment [15 marks]
In this exercise, you have to implement the following workflow:
a) Reset, create and verify two VIEWS, which you will call training_data and test_data. These VIEWS should contain non-overlapping posts which you will use to train and evaluate your classifier. The logic will be implemented in the following (empty) functions, located in the main.py script, provided in the starter package:
- reset_views() - Drop (if they exist) and create the views. [1 mark]
- create_training_view() - Create an SQL VIEW for training data. This
view will have two columns, the text and the label. It is up to you to decide the size of the dataset and the proportion of Covid vs. non-Covid posts. And also which part of the post you take (title, body or both). You will justify these choices in Assessment 3. We will make the strong assumption that any post submitted to a Covid-related subreddit will be about Covid-19, and that it will be non-related to Covid if it is submitted somewhere else. [3 marks]
- create_test_view() - Create view for test data. This view will have two columns, the text and the label. The same principles as in the previous case apply. [3 marks]
- check_views() - Retrieve all records in training_data and test_data, and print to the console their size. This is a small sanity check. [1 mark]
b) Retrieve data from the views you created in step 1, train and evaluate a classifier, and return the results as a JSON object that is rendered in the browser. Implement this functionality in the experiment() method, again in the main.py script. It is up to you to decide on the classifier and its configuration. There is an opportunity to reflect on these choices in Assessment 3. [5 marks]
c) Take the model binaries, model configuration and the classification results you obtained in step (b), as well as the time in which the experiment was performed, and store this information in a dedicated collection. This exercise is open, i.e., there is no suggested format on how to store this data, what information to store for your models or the evaluation metrics you use. There is an opportunity to reflect on these choices in Assessment 3. [2 marks]
2. Retrieve information on the experiments conducted so far (5 marks)
a) In this exercise, you query the collection you implemented in step 1c, and show the top 3 experiments based on a certain criterion (best scoring according to metric X, the most recent experiments, the fastest experiments in training time, etc.). Your results will be returned as JSON objects and rendered in the browser. [5 marks]
3. Implement a ‘covid-or-not’ predictor (5 marks)
a) In this exercise, you implement a functionality for predicting ‘on the fly’ whether a piece of text is Covid-19-related or not. To this end, you will use the top-ranked model according to the ranking you implemented in step 2a. This model will then be applied to the input text and the results will be rendered in the browser as a JSON object with the format:
{
"input_text": some_input_text,
"prediction": the_prediction_of_your_classifier
}. [5 marks]
Assessment 3
Report (55 Marks)
assessment3_report_[student number].pdf
In Assessment 3, you write a technical report on Assessments 1 and 2, and discuss ethical, legal and social implications of the development of this Covid-19 application in the context of the UK Data Ethics Framework. You are strongly encouraged to follow a scholarly approach, e.g., with peer-reviewed references as support, and with additional empirical evidence (your own tests) for justifying your decisions (e.g., performance or physical storage for DBMS, training time or accuracy for the ML webapp solution). Maximum 2,000 words (not counting references, index and table and figure captions).
This report should cover the following aspects, discussing challenges and problems encountered and the solutions implemented to overcome them. The mark will be divided between 3 expected sections:
o [3a] Database Creation (DB choice, design, etc.), i.e., the research and findings stemming from the development of Assessment 1. Specifically, you should discuss any business rules that can be inferred from the dataset (reverse engineering), normalization (identifying partial and transitive dependencies, if any, unnormalized relations, etc.), data integrity and constraints, bad data, etc. Moreover, the expectation is that any design decision (or lack thereof) will be empirically (e.g., with performance tests) and/or theoretically (pointing to peer-reviewed publications) supported. [20 Marks]
o [3b] ML Application, explaining the implementation of the training and test VIEWS; the ML algorithm chosen (based on main features, hyperparameters used in the application, training speed as opposed to other alternatives, etc); evaluation metrics; the overall logic followed by the app for storing and retrieving experimental results; and finally any further details that may be relevant for the ‘covid-or-not’ inference functionality. You should also discuss the rationale behind the MongoDB interaction with pointers both to the database and the code that interacts with it. [20 Marks]
o [3c] Ethics and Bias in Data-driven Solutions in the specific context of this dataset and the broader area of application of this project (automatic categorization of social media content to enable easier screening of public opinion). You should map your discussion to one of the five actions outlined in the UK’s Data Ethics Framework. You should prioritize the action that, in your opinion, is the weakest. Then, justify your choice by critically analyzing the three key principles outlined in the Framework, namely transparency, accountability and fairness. Finally, you should propose one solution that explicitly addresses one point related to one of these three principles, reflecting on how your solution would improve the data cycle in this particular use case. [15 Marks]
Learning Outcomes Assessed
This coursework covers the 7 LOs listed in the module description.
Criteria for assessment
Credit will be awarded against the following criteria.
Assessment 1 (20 Marks) Criteria for assessment are detailed below:
Data Modeling (8 marks)

Querying (12 marks)

Assessment 2 (25 Marks) Criteria for assessment are detailed below.

Assessment 3 (55 Marks) Criteria for assessment are detailed below, with specific benchmarks for each section.
Database creation (20 marks)

ML Application (20 marks)

Ethics and Bias in Data-driven Solutions (15 marks)

The grade range is divided in:
o Distinction (70-100%)
o Merit (60-69%)
o Pass (50-59%)
o Fail (0-50)
Feedback and suggestion for future learning
Feedback on your coursework will address the above criteria. Feedback and marks will be returned between June 30rd and July 2th via Learning Central. There will be opportunity for individual feedback during an agreed time.
Feedback for this assignment will be useful for subsequent skills development, such as database design, SQL and NoSQL, data analysis, machine learning and client-motivated deliverables involving predictive analysis.
2021-05-17