COMPLEX SURVEY DESIGNS AND ANALYSIS -SOST70032
COMPLEX SURVEY DESIGNS AND ANALYSIS -SOST70032
Assignment 2021
The assessment for this module is based on 85% for this three-part assignment, and the remaining 15% on an online quiz to be held on the 15th April 2021. This document specifies the particular requirements for the assignment. The total marks available for the assignment are set to 100.
Part A: An outline proposal
A maximum of 2-page (maximum 1000 words) summary of a proposal for research on a topic of your interest implementing a complex survey design.
Note: You are also allowed to have up to two pages of appendices, including figures, tables, and questionnaires.
This brief summary proposal should cover the following:
- Background, aims and objectives, and justification of your research questions.
- Description of your methodology with emphasis on your target population, survey design, sampling, mode of data collection, instrumentation and any piloting.
- Proposed methods of analysis, and implications of the complex survey design.
- Expected main contributions and outcomes of this work
Total points for Part A: 35
Part B: Practical Exercise
The dataset assignmentCSDA2021.dta is a stata format dataset based on data from the Brazilian Family Budgets Survey 2002/2003 (BFBS). The study was designed to be a nationally representative survey of Brazilian households, covering 26 States and the Federal District of Brasilia. Fieldwork took place between July 2002 and June 2003 (12 months). The survey aimed to get State and National level estimates for: (a) income and expenditure variables, (b) anthropometric measurements of population, and (c) a large number of socio-economic indicators.
The Sample Design involved a stratified, two-stage sampling of households, with the following details:
● Stratification of PSUs by
- State
- Education of heads of households (average at PSU level)
● Primary sampling units are census enumeration areas PSUs sampled with probability proportional to size (PPS – size) where the size variable is the number of HHs in the census
● Secondary sampling units are households SSUs sampled with SRS within each PSU2
The achieved sample sizes are summarised in the following table:
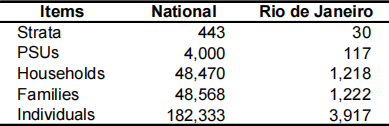
Data were collected at 3 levels with 6 CAPI questionnaires, as detailed below:
Household level:
● List of all usual residents, including those not present
● Household structure, tenure and utilities / services
● Existence of and number of appliances and cars
● Household related expenditures
Family (consumption unit):
● Family level expenditures
● Family subjective assessment of living conditions
Individual level:
● Age, sex, ethnicity, religion, education, height, weight
● Jobs held, and status, occupation, activity & income in each job
● Other individual income and expenditure
The dataset for analysis represents only the Rio de Janeiro area.
Variables have been pre-coded and labelled, but you will need to do some recoding for some of them. The variable description and codebook is attached at the end of the assignment. The variables indicating stratification and clustering, as well as the weights are also listed there (Appendix 1).
There are two potentially interesting response variables:
- The variable hlthins is a 2 category outcome indicating whether or not the person has health insurance.
- The variable crdcard is also a 2 category outcome indicating whether or not the person has a credit card
You will need to choose one of these two variables as your outcome of interest in order to perform the tasks in this assignment. We will call this variable within the guidelines ‘response’ variable.
It is of interest to find out how the chance of a person having health insurance or a credit card is associated with other variables in the dataset, including their education (education), gender (sex) and ethnic group (ethngrp).
Please note that you may need to perform some data recoding (for both dependent and independent variables) during the analysis.
Given this 2-stage stratified design, use STATA to carry out the analysis detailed next. It is advised that you present and discuss your results under the four headings used below. However, it is also advised that this should be in the form of a coherent essay-style report (and not simply a list of answers to these questions or copies outputs from the software):
Part 1: Descriptive analysis [5 points]
Q1. Obtain the overall proportion (mean) of the response variable, and its standard error assuming a SRS had been taken. Briefly comment.
Q2. Briefly state which variables you expect to significantly affect the response variable and give some descriptives for them. Explain any recoding you performed and the reasoning for this.
Part 2: Model based inference [25 points]
Q3. Using an appropriate model estimate (without considering the survey design yet):
a) The overall chance that the person has a health insurance/credit card.
b) The association between the chance that the person has health insurance/credit card and their age-group, gender, education and ethnic group. Which, if any of these variables have a significant effect?
c) Extend or adopt the model in Q3.b to include other variables of interest (as you discussed in Q2 – this will be defined as “your model” next)
Q4. Take the stratification by state into account in your model and estimate:
a) The association between the chance that the person has health insurance/credit card and their age-group, gender, education and ethnic group. Which, if any of these variables have a significant effect?
b) Do the same for “your model”.
Q5. Take the multistage clustering and stratification by state into account in your model and estimate:
a) The extent of within-PSU similarity of the response variable before adding the stratification variable and any other explanatory variables to the model.
b) The association between the chance that the person has health insurance/credit card and their age-group, gender, education and ethnic group. Which, if any of these variables have a significant effect?
c) Do the same for “your model”.
d) For either “your model” or the resulting model in Q5.b, discuss whether there are any differences between the conclusions from this model and the corresponding conclusions of the models from Q2, Q3 and Q4. Also discuss what is the extent of within PSU similarity of the response variable once the explanatory variables have been added to the model?
Part 3: Design based inference [15 points]
Q6. Use the appropriate commands in stata to set up a complex survey design used in the study. Then estimate:
a) The proportion of people who have health insurance/credit card.
b) The association between the chance that the person has health insurance/credit card and their age-group, gender, education and ethnic group. Which, if any of these variables have a significant effect?
c) Do the same for “your model”.
Part 4: Discussion [15 points]
Discuss the results in the context of the debate between design based and model based approaches. This should include a discussion of how the results from the design based approach in Part 3 compare with those from the model based approach in Part 2. This section needs to include a review of some relevant methodological literature, and a critical evaluation of the ‘debate’ between the two approaches with references. Please note that this section should not exceed 500 words.
Important Note: The results from the practical part of the assignment need to be written and presented in essay formal. Copied and pasted outputs from the software are not allowed.
Total points for Part B: 60
Total points for Parts A and B = 95.
5 points are awarded for layout and clarity of the report, including referencing. The combined word count for Parts A and B should not exceed 3000.
The submission deadline for this work is May 21st 2021, 3pm via turnitin. Penalties are applied to work that is submitted late without a valid excuse.
Please bear in mind that other modules may also have the same deadline as this one, so please manage your workload accordingly.
Please note the Assessment Pledge applies to this course.
Beyond this, extensions are granted only by the MSc Director and must be sough prior to the deadline. To ensure fairness, extensions to the deadline will only be granted in exceptional cases. Pressure of work will not be seen as a valid reason for extension and students should plan their workloads accordingly. The deadline has been set as late as possible in the semester and leaves the minimum time for marking ahead of the exam board.
Plagiarism
Plagiarism is presenting the ideas, work or words of other people without proper, clear and unambiguous acknowledgement. It also includes ‘self plagiarism’ (which occurs where, for example, you submit work that you have presented for assessment on a previous occasion), and the submission of material from ‘essay banks’ (even if the authors of such material appear to be giving you permission to use it in this way). Obviously, the most blatant example of plagiarism would be to copy another person’s or student’s work.
Plagiarism is a serious offence and will always result in imposition of a penalty. In deciding upon the penalty the University will take into account factors such as the year of study, the extent and proportion of the work that has been plagiarised and the apparent intent of the student. The penalties that can be imposed range from a minimum of a zero mark for the work (with or without allowing resubmission) through the down grading of degree class, the award of a lesser qualification (e.g. a pass degree rather than honours, a certificate rather than diploma) to disciplinary measures such as suspension or expulsion.
The University of Manchester is committed to combating plagiarism. In the School of Social Sciences a percentage of all work submitted for assessment can be submitted for checking electronically for plagiarism. This may be done in two ways: (i) Phrases or sentences in your assessed work may be checked against material accessible on the world wide web, using commonly available search tools. You will not be informed before this checking is to be carried out; (ii) The University subscribes to an online plagiarism detection service specifically designed for academic purposes.
See SRMS Booklet for more information.

2021-05-12